It is not every day that you come across a new term or concept Google doesn’t yet know about. So today we’ll teach Google about something new we’ve added to SPM in the latest release: Algolerts.
Please tweet about Algolerts – Algorithmic Anomaly Detection Alerts
The Problem with Threshold-based Alerts
Why do we even have alerts in performance monitoring systems? We have them because we want to be notified when something bad happens, when some metric spikes or dips too much – when CPU usage hits the roof, when disk IO goes up, when the network traffic suspiciously quiets down, and so on. We see such spikes or dips in metric values as signs that something might be wrong or is about to go wrong. When limited to traditional threshold-based alerts one is forced to figure out what range of metric values represents a non-alarming, normal state and, conversely, at which point spikes and dips should be considered out of an acceptable range and taken seriously. One needs to pick minimum and maximum metric values and then create one alert rule for each such value. The same process then needs to be repeated for every metric one wants to monitor. This is painful and time-consuming. To make things worse, these thresholds have to be regularly updated to match what represents the new normal! One can try to fight this by setting very “loose alerts” by picking high maxima and low minima, but then one risks not getting alerted when something really does go awry.
To summarize:
- It is hard to estimate the normal range of each metric and pick min and max thresholds
- Metric values often fluctuate and create false alerts
- To avoid false alerts one has to regularly adjust alert rule thresholds
Algolerts to the Rescue!
With the name obviously derived from terms Algorithm and Alert, Algolerts are SPM’s alternative, or perhaps even a replacement for traditional threshold-based alerts you so often see in most, if not all monitoring solutions. Algolerts don’t require thresholds to figure out when to alert you. Algolerts can watch any metric you tell them to watch and alert you when an anomalous pattern – a pattern that deviates from the norm – is detected.
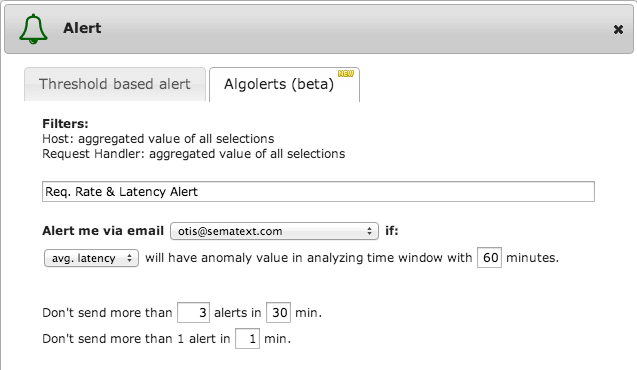
Creating Algolerts is even simpler than adding threshold-based alerts and is done through a familiar interface:
Algolert notifications provide useful and easy to read numbers so one can quickly see just how big of an anomaly this is about. Here is an example notification:
Anomalous value for 'received' metric has been detected for SPM Application SA.Prod.Kafka Host filter=xxx, Network Interface filter=eth0. Anomaly detection window size: 1800 seconds. Statistics for 'received' metric are: Current: 1,220,121.00 Average: 185,147.97 Median: 89,536.00 StdDev: 222,173.70
Known Kinks
Algolerts implementation that’s in place in SPM today has a few known kinks. The kinks we know about and that we’ll be ironing out are:
- no “things are OK again, you can go back to sleep” notifications are sent when the metric value goes back to normal
- regular anomalies (e.g. a CPU intensive nightly cron job) may trigger false alerts, though this is not necessarily different from threshold-based alerts anyway
- recently observed anomalies can create “the new norm” and thus hide subsequent anomalies
Despite this, Algolerts have already proven very good and valuable in our own use of SPM and Algolerts – we’re slowly removing all our threshold-based alerts and are switching to Algolerts and invite you to try them out as well.
Please send us your feedback and follow @sematext for updates.