With the release of Solr 5.0, the most recent major version of this great search server, we didn’t only get improvements and changes from the Lucene library. Of course, we did get features like:
- segments control sum
- segments identifiers
- Lucene using only classes from Java NIO.2 package to access files
- lowered heap usage because of new Lucene50Codec
…but those features came from the Lucene core itself. Solr introduced:
- improved usability for start-up scripts
- scripts for Linux service installation and running
- distributed IDF calculation
- ability to register new handlers using the API (with jar uploads)
- replication throttling
- …and so on
All of these features come with the first release of branch 5 of Solr, and we can expect even more from future releases — like cross data center replication! We want to start sharing what we know about those features and, today, we start with replication throttling.
The Use Case
Imagine a situation where your Solr deployment (no matter if it is SolrCloud or traditional master-slave) hosts very large collections/indices. It is even easier to illustrate in master-slave deployment. Imagine that we force-merge our very large index to one segment. What Solr will do is copy all the index files from master to slave, because they all changed. In these situations replication can use the whole network bandwidth. Of course, that means that the index/collection will be transferred as soon as possible; but that also means that all the queries and indexing operations could suffer because they could be slowed down by replication using the whole bandwidth. In such cases replication throttling can be very useful.
The Test
To illustrate how replication throttling works in Solr 5, we decided to use two simple configurations of replication in a SolrCloud environment. The setup used collection with one shard and one replica. The leader shard contained about 2GB of data, not much, but more than enough to show you how it works.
Replication without Throttling
The first test has been done with the default replication configuration that looked as follows:
<requestHandler name="/replication" class="solr.ReplicationHandler"> </requestHandler>
As you can see, this is nothing complicated — only the default replication handler configuration. This is what SPM Performance Monitoring showed us when we looked at the network usage metrics:
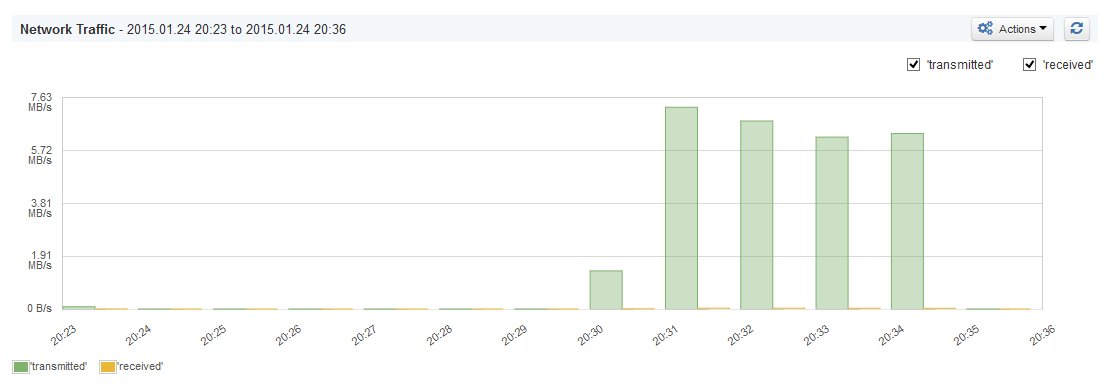
Almost 7.5MB/s of bandwidth usage and the test was done on a local network, between two PCs connected to the same WiFi network. If the index were to be as large as a few hundred GB and that would have to be transferred, we would have our network bandwidth exhausted for a few minutes — at least!
Replication with Throttling
The second test was done so we could see if throttling really works, i.e., to see that we’ve set up the replication handler to use not more than 100KB/s of bandwidth, which is small enough to see the difference. Our modified replication handler configuration looked as follows:
<requestHandler name="/replication" class="solr.ReplicationHandler"> <lst name="defaults"> <str name="maxWriteMBPerSec">0.1</str> </lst> </requestHandler>
We’ve introduced the maxWriteMBPerSec property in the defaults section of the handler configuration and we’ve set it to 0.1, which means no more than 100KB/s. Of course we have to remember that this is an approximation, so it is expected that Solr can transfer a bit more data sometimes. But, in general, the average shouldn’t be larger than the value we’ve set.
Again we’ve looked at SPM network utilization visualization and we’ve seen the following:
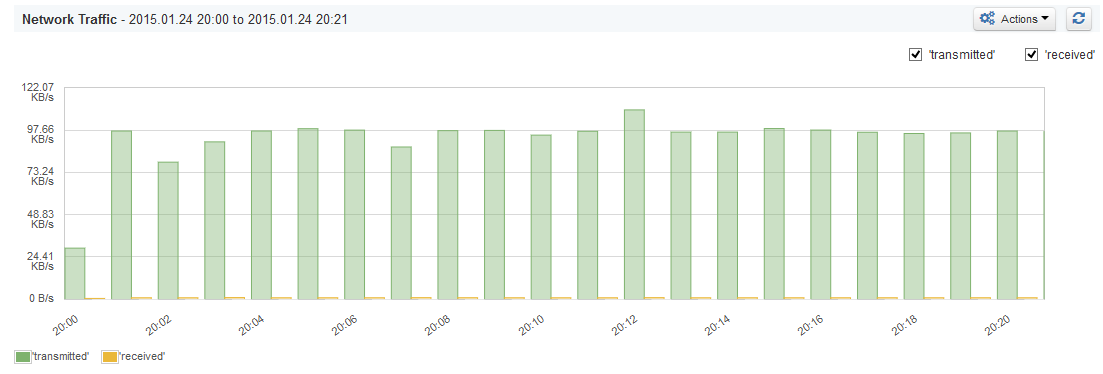
And this is what we expected. We’ve seen that almost the whole time Solr didn’t transfer more than 100KB/s.
A Brief Summary
Replication throttling in Solr 5 works; that’s a fact. What we would like to see next is an API that would enable us to dynamically change the throttling, so we can automate that depending on our needs without pushing our collection configuration to ZooKeeper or reloading a core in master-slave deployment. Looking into the past at how Solr changed between 4.0 and 4.10, we can expect a lot of nice features to be released in upcoming versions of the 5.x branch.