During the Entity Extraction For Product Searches talk that Radu Gheorghe and I gave at Activate conference in Montreal last year, we talked about various natural language processing and machine learning algorithms. We showed entity extraction both on top of Solr and using external libraries. In this post we dig into Learning to Rank with Solr Streaming Expressions.
 Solr Node, Jetty, JVM Metrics and more…
Solr Node, Jetty, JVM Metrics and more…Solr Metrics API Cheat Sheet
What is Learning to Rank
Learning to Rank is a contrib module available in the default Solr distribution. It allows running trained machine learning models on top of the results returned by our queries. It supports feature extraction, normalization, parameterized machine learning models and query re-ranking on top of data indexed in Solr.
Learning to Rank & Solr
The first question that you may be actually asking is why Learning to Rank together with Streaming Expressions? The answer is really simple – because they are all part of Solr and using them together can help you improve search results relevance.
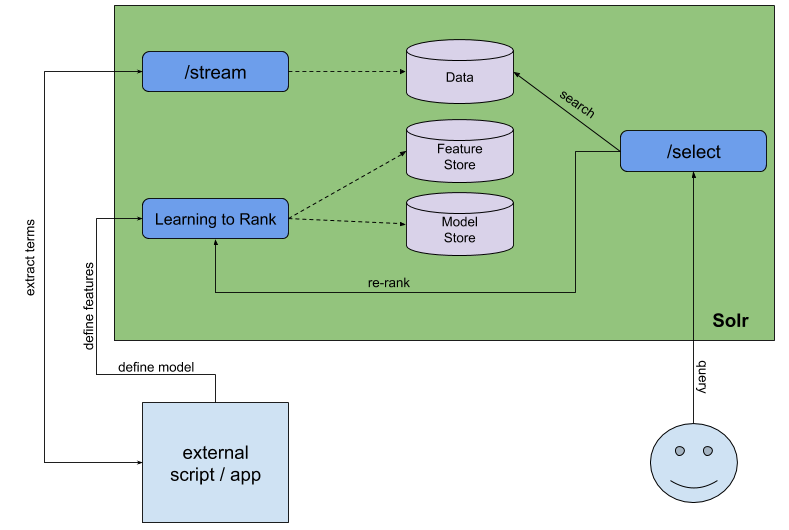
Scenario
Let’s assume that we have a video search site and we sell access to it. It doesn’t matter how ridiculous it sounds right now, it will allow us to reuse the same data as we used during the Activate conference talk with Radu (you can find the data in @sematext/activate). Each video is identified by a set of fields which include:
- Identifier of the video
- URL where the video is available
- Title
- Name and the date of the uploader
- Number of views and likes
- Tags
The tags themselves are usually not used for searching, however if we would like to improve relevancy of our search we can include those as well. However, we don’t want to search on them – what we want is to calculate how popular they are and run a rescoring algorithm on top of that information.
As we can see, there are two things that we need in order to achieve the hypothetical scenario. First, we need to get the information about the popularity of the tags. We can get that from our Solr data. The second thing is rescoring the data itself.
Streaming Expressions
Streaming Expressions in Solr is a stream processing language working on top of SolrCloud that provides a set of functions that can be combined together to perform parallel computing tasks. There is a vast number of tasks that you can achieve when using streaming expressions. From parallel searching and combining data from different sources like Solr collections and JDBC data sources to data reindexing and automatic collections update based on certain criteria. The list of functionalities is constantly growing, but just to give you some overview, we can divide the current state of streaming expressions into five categories:
Stream Sources
Various sources that you can use to fetch data. Starting from a collection as the data source, through JDBC, faceting, graph nodes, statistics computing, time series data and even logistic regression functions. With the list constantly being updated and extended we have really rich source of data for our streams.
Stream Decorators
Functions allowing us to do operations on the streams. There are features like merging streams, modify them, enrich, evaluate, select fields from tuples, rollup, join and so on. With more than 20 decorators at the time of writing we are given large variety of options when it comes to data modification.
Stream Evaluators
While the sources and decorators return stream of tuples, the evaluators return a value, array or map. They provide a number of functions, i.e. ones allowing operation over arrays, histograms, etc. It is constantly extended with new functions and with the newest Solr versions provide a set of statistical and multidimensional statistical calculations like Markov chains simulations.
Mathematical Expressions
A set of math based functions allowing matrix, vector, scalar math, statistical expressions, interpolations, linear regression and so on.
Graph Traversal
functions that in combinations with appropriate stream source allow for breadth-first graph traversal.
There are lots of possibilities, but we will of course not look into all of them. What we will do though is run a very simple setup that will take into consideration term frequency from the tags field of our documents.
The Data
For our purpose we will use a standalone SolrCloud instance with this collection configuration. Let’s clone the repo we prepared that has everything we need:
git clone git@github.com:sematext/activate.git
Next, we upload the configuration to Solr:
bin/solr zk upconfig -n blog -z localhost:9983 -d activate/stream/conf
We create a collection called blog using the uploaded configuration:
bin/solr create_collection -c blog -n blog -shards 1 -replicationFactor 1
Lastly, run the provided indexing script to index the data from the data directory:
cd activate; ./index.sh blog
Extracting Boost Terms
Now, let’s extract boost terms by using the following streaming expression:
curl --data-urlencode 'expr=select(
sort(
significantTerms(blog, q="*:*", field="tags", limit="100", minDocFreq="5", maxDocFreq=".5", minTermLength="3"),
by="score asc"
),
term as term,
mult(100,div(10, score)) as score
)' http://localhost:8983/solr/blog/streamLet’s take a second here and discuss what is happening in the above query. First we are sending the request to the /stream request handler. Next, we are using the select stream decorator that wraps another streaming expression and results in tuples containing a subset of documents. The first information we would like to return is a list of sorted significant terms where the sorting should be done on the term score in the ascending order. That means that we are listing the most common terms first. We run the significantTerms stream source on our collection using the match all query on the tags field with the limit of up to 100 terms. We also limit the terms that are taken into consideration – minimum document frequency is set to 5, which means that the term needs to be present in at least 5 documents, the maximum term frequency is set 50%, which means that the terms needs to be present in less than 50% of the documents to be returned. This removes garbage from our data, such as stop words. Finally, the minimum term length is set to 3 again to prune the data. The term itself is returned in the term property of each returned tuple.
We also need the score. The significantTerms stream source already returns a score for each term, but the score is the highest for the most uncommon terms. This is not what we are aiming for – we would like to have the highest score for the most common terms. To do that we will use a very simple approach. We can check that on our data the highest score for terms is around 7, so rounding that up to 10 and dividing the score by that will ensure that the lower the score of the term the higher the final score and this is what we are aiming for. Just to be sure that our search will reflect the scoring we multiple the score by 100 and return it.
So the distribution of the calculated scores will look like this:
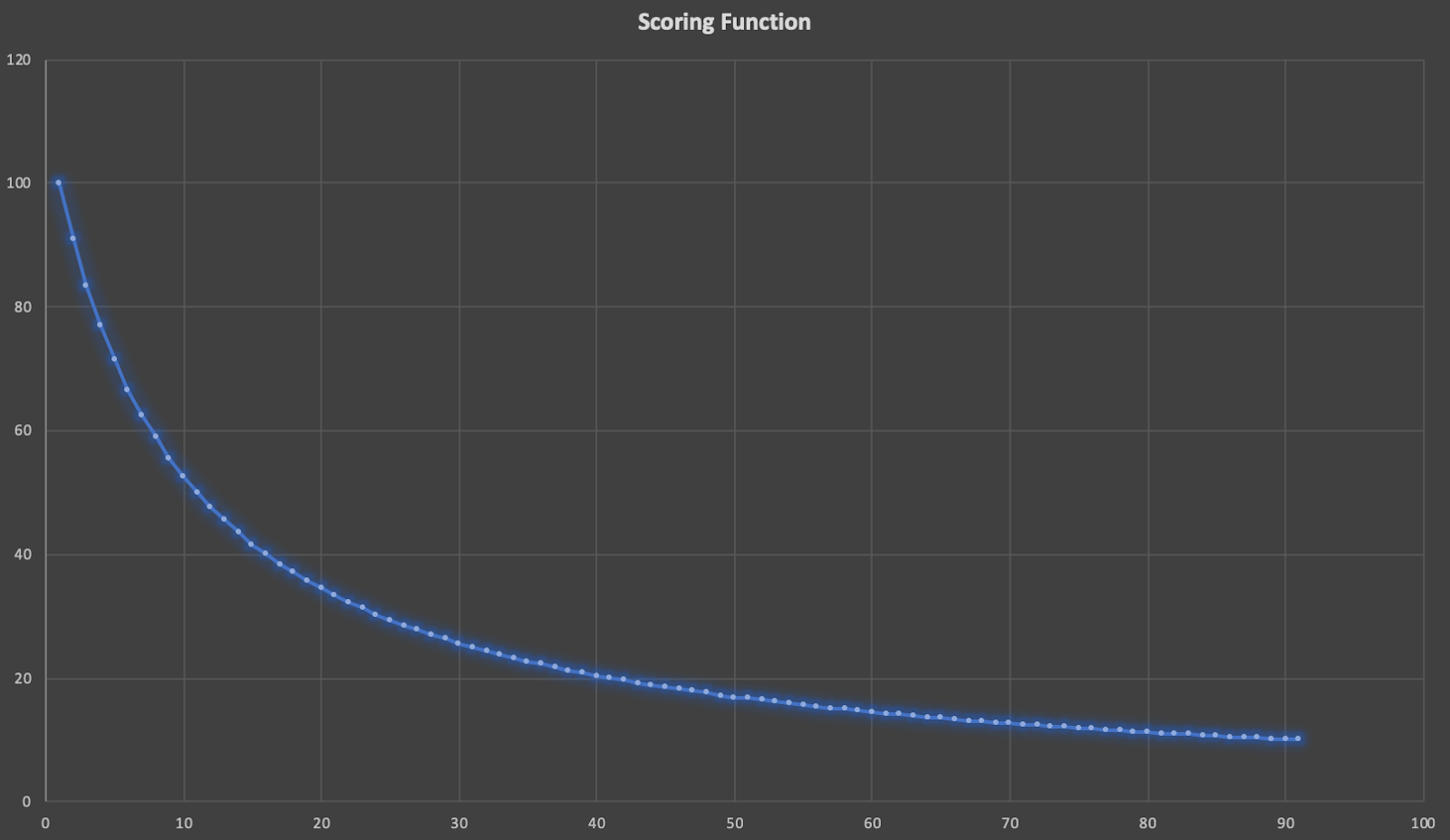
So, when the score of the term is 1, the final calculated score will be 100.
The result of the significant terms calculation for the above command is as follows:
{
"result-set":{
"docs":[{
"score":146.9042154840393,
"term":"elasticsearch"}
,{
"score":146.9042154840393,
"term":"solr"}
,{
"score":142.4158105019783,
"term":"logging"}
,{
"score":135.1941546914501,
"term":"sematext"}
,{
"score":134.6618587535265,
"term":"rsyslog"}
,{
"score":133.0680701196341,
"term":"tutorial"}
,{
"score":132.6952637344906,
"term":"logstash"}
,{
"score":132.6952637344906,
"term":"monitoring"}
,{
"score":132.6952637344906,
"term":"docker"}
,{
"EOF":true,
"RESPONSE_TIME":4}]}}Configuring Learning to Rank
Let’s now configure Learning to Rank. Actually, we already have that done, because we are using the configuration that has that prepared, but let’s discuss what needs to be done to have Solr Learning to Rank working.
First we need to load the additional contrib libraries. It is as simple as adding jar loading in the solrconfig.xml:
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-ltr-\d.*\.jar" />We also need a specialized cache added in the query section of the solrconfig.xml file:
<cache name="QUERY_DOC_FV" class="solr.search.LRUCache" size="4096" initialSize="2048" autowarmCount="4096" regenerator="solr.search.NoOpRegenerator" />
Next, the specialized query parser needs to be added. To do that we put the following definition into the solrconfig.xml file:
<queryParser name="ltr" class="org.apache.solr.ltr.search.LTRQParserPlugin"/>Finally, the features transformer needs to be present in the solrconfig.xml, which means that we needs the following part of the configuration added:
<transformer name="features" class="org.apache.solr.ltr.response.transform.LTRFeatureLoggerTransformerFactory"> <str name="fvCacheName">QUERY_DOC_FV</str> </transformer>
And that’s all 🙂
Building the Feature Store
For Learning to Rank to work we have to prepare the feature store. It will contain our features that will be used for documents reranking by our scoring model. In our case the features will be built on top of the terms that we extracted using the streaming expressions. Each feature is defined as follows:
{
"name" : "sol_tag",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"fq" : [ "{!terms f=tags}solr" ]
}
}To come up with a name for the feature we use the org.apache.solr.ltr.feature.SolrFeature as the class and give additional parameters that will help us identify which documents should be taken into consideration when running the feature, like in the above example we use the terms query parser to match the documents having solr tag. We do that to the give the documents matching the solr tag a higher score.
To keep it simple we will take three top terms from the results of our streaming expression and define them as features:
curl -XPUT 'localhost:8983/solr/blog/schema/feature-store' -H 'Content-type:application/json' --data-binary '[
{
"name" : "elasticsearch_tag",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"fq" : [ "{!terms f=tags}elasticsearch" ]
}
},
{
"name" : "solr_tag",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"fq" : [ "{!terms f=tags}solr" ]
}
},
{
"name" : "logging_tag",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"fq" : [ "{!terms f=tags}logging" ]
}
},
{
"name" : "score",
"class" : "org.apache.solr.ltr.feature.OriginalScoreFeature",
"params" : {}
}]'In addition to the first three terms we also took the original score of the document as a feature, so that we don’t lose the relevancy of the document itself. For that we used the org.apache.solr.ltr.feature.OriginalScoreFeature class. This is crucial, because we don’t want to only sort, we also want to remember which documents were really important and on topic.
There are also three additional features that are available out of the box in Solr. Those are org.apache.solr.ltr.feature.FieldLengthFeature that lets us use length of the field in our models, we have org.apache.solr.ltr.feature.FieldValueFeature letting us use field value in our models, and we have the org.apache.solr.ltr.feature.ValueFeature allowing us to use arbitrary value in the scoring model.
Building the Scoring Model
With the feature store built we can finally finish up the configuration by building the model for Learning to Rank. The model itself is identified by its name, class, features, and a set of parameters. We already have our features and as parameters we will define weight for each feature. The weight will be equal to the rounded score of each of the terms that we extracted using the streaming expression run earlier.
The final ranking model definition request will look as follows:
curl -XPUT 'localhost:8983/solr/blog/schema/model-store' -H 'Content-type:application/json' --data-binary '{
"class": "org.apache.solr.ltr.model.LinearModel",
"name": "tagsTrainingModel",
"features": [
{
"name": "elasticsearch_tag"
},
{
"name": "solr_tag"
},
{
"name": "logging_tag"
},
{
"name": "score"
}
],
"params": {
"weights": {
"elasticsearch_tag": 146,
"solr_tag": 146,
"logging_tag": 142,
"score": 1
}
}
}'We’ve used the org.apache.solr.ltr.model.LinearModel which uses the dot product to compute the score. An example of the linear model is the RankSVM model, which uses a function to describe the matches between a search query and the features of each possible result. Of course, this is not the only model that is available in Solr implementation of Learning to Rank. We also have the org.apache.solr.ltr.model.MultipleAdditiveTreesModel – one of the example implementations of that model is a LambdaMART. It uses gradient boosted decision trees for solving the ranking task. We can use the org.apache.solr.ltr.model.NeuralNetworkModel that, as it names suggest, computes document scores using a neural network and supports identity, relu, leakyrelu, sigmoid and tanh activation functions defining the output of the nodes in the defined neural network. Finally, we can also extend Solr and provide our own implementation of the Learning to Rank scoring model.
However, as previously mentioned, in our case we used the simplest approach – the org.apache.solr.ltr.model.LinearModel model. At a very high level it will take the defined features and apply the weight if the given feature matches the document.
The Query
Now that we have everything done we can use the model that we’ve prepared in our query. To do that we will use the re-rank query functionality of Solr and the Learning to Rank query parser we defined earlier. We will need to provide the name of the model that we would like to use and the number of documents that Solr will rerank based on the scores computed by the scoring model, e.g. let’s adjust 3 documents. In such case we would have to add the following parameter to the query: rq={!ltr model=tagsTrainingModel reRankDocs=3}, so for example a match all query would look like this:
http://localhost:8983/solr/blog/select?q=*:*&rq={!ltr model=tagsTrainingModel reRankDocs=3}Let’s compare the results of a simple query that is run without the re-ranking and the one above. So first, let’s run the following query:
http://localhost:8983/solr/blog/select?q=*:*&fl=id,tags,score&rows=5
The output of such query is as follows:
{
"responseHeader": {
"zkConnected": true,
"status": 0,
"QTime": 0,
"params": {
"q": "*:*",
"fl": "id,score,tags",
"rows": "5"
}
},
"response": {
"numFound": 37,
"start": 0,
"maxScore": 1,
"docs": [
{
"id": "1",
"tags": [
"business value",
"big data",
"search analytics"
],
"score": 1
},
{
"id": "10",
"tags": [
"elasticsearch",
"logs",
"logstash",
"rsyslog",
"json"
],
"score": 1
},
{
"id": "11",
"tags": [
"elasticsearch",
"solr",
"logs",
"performance",
"logstash",
"rsyslog",
"flume"
],
"score": 1
},
{
"id": "12",
"tags": [
"elasticsearch",
"scaling",
"routing",
"sharding",
"caching",
"monitoring"
],
"score": 1
},
{
"id": "13",
"tags": [
"big data",
"solr",
"elasticsearch"
],
"score": 1
}
]
}
}Because this is a match all query we have the score of each document equal to one. Now if we would like to calculate the score of the top three documents using our scoring model we would run the following query:
http://localhost:8983/solr/blog/select?q=*:*&fl=id,tags,score&rows=5&rq={!ltr model=tagsTrainingModel reRankDocs=3}We are again returning 5 results, but we are re-scoring the top three documents so that the results are as follows:
{
"responseHeader": {
"zkConnected": true,
"status": 0,
"QTime": 57,
"params": {
"q": "*:*",
"fl": "id,score,tags",
"rows": "5",
"rq": "{!ltr model=tagsTrainingModel reRankDocs=3}"
}
},
"response": {
"numFound": 37,
"start": 0,
"maxScore": 293,
"docs": [
{
"id": "11",
"tags": [
"elasticsearch",
"solr",
"logs",
"performance",
"logstash",
"rsyslog",
"flume"
],
"score": 293
},
{
"id": "10",
"tags": [
"elasticsearch",
"logs",
"logstash",
"rsyslog",
"json"
],
"score": 147
},
{
"id": "1",
"tags": [
"business value",
"big data",
"search analytics"
],
"score": 1
},
{
"id": "12",
"tags": [
"elasticsearch",
"scaling",
"routing",
"sharding",
"caching",
"monitoring"
],
"score": 1
},
{
"id": "13",
"tags": [
"big data",
"solr",
"elasticsearch"
],
"score": 1
}
]
}
}Look at the top three documents from the query. The first document has two features matched – the solr and elasticsearch values in the tags field. The second document has a single feature matched – the elasticsearch value in the tags field. Those two documents have their scores adjusted. The third document score is still equal to 1.0, because it doesn’t match any of the defined features (apart from the original score, of course). We can see that the more features match in the document the higher the score of the document, which is logical and what we would expect.
At first sight that approach has one big disadvantage – you can only rescore top N documents. But that is not actually bad. We should aim to present the most relevant documents on the first page anyway, maybe in the first few pages. So if our queries return the relevant documents on the first 10 pages of results and we return 10 documents per page we can easily rescore only top 100 documents. By doing that on a limited data set we will get the desired results. What’s more, by limiting the reranking to top 100 matches we will save hardware resources by not doing complicated scoring on possibly large number of documents.
Conclusion
This is only the beginning of the journey into the world of search results relevance ranking, scoring models, features extraction, and natural language processing. We’ve shown how to use Solr to extract the relevant terms and we came up with a simple streaming expression. We could refine this further by modifying the number of likes and the number of views to contribute to the term score, for example. We could also use the number of likes and the number of views and use it as separate features in our Learning to Rank scoring model. We could move entity extraction from the tags field in our data to any of the available NLP capable libraries to have a better and more controllable extraction and then use them to build the scoring model. As you can see, there are endless possibilities to go from here.
Do you find working with search exciting? If so, we’re hiring worldwide.
Need help improving your search relevancy? We can help! Have a look:
- Solr, Elasticsearch and Elastic Stack consulting
- Solr, Elasticsearch and Elastic Stack production support
- Solr, Elasticsearch and Elastic Stack training classes (online, on site, public, or private and tailored for your team)
- Monitoring, centralized logging, and tracing for not only Solr and Elasticsearch, but a number of other applications (e.g. Kafka, Zookeeper), infrastructure, and containers.
- Good luck on improving your search relevance! Before you go, don’t forget to download your Solr Metrics API Cheat Sheet:
 Solr Node, Jetty, JVM Metrics and more…
Solr Node, Jetty, JVM Metrics and more…
Solr Metrics API Cheat Sheet