Introduction
Launching a mobile App is no walk in the park, especially when it comes to your App’s store position and ratings. One of the trickiest parts is maintaining a good App store rating. An App’s store ratings are the key to its success. If you’re serious about your App succeeding in an oversaturated market, it is vital to implement strategies to both increase and maintain your App’s store ratings. Putting in the effort to boost your App’s rating is like giving it a spotlight, this spotlight can make all the difference to the success of your App in a highly competitive marketplace.
Note that monitoring your mobile App’s rating is just one example of monitoring numerical data in 3rd party sources. For example, you can also track your product’s rating on web sites or extract and dashboard any numerical data from a web page.
Why are App ratings important?
Store ratings hold significant power in the App world. When an App is given a low rating by an unhappy user, it’s like sending it on a downward spiral in the search rankings. The App gets shoved down the search results, buried under its outperforming and highly-rated competitors. This is akin to being stuck in a hidden treasure chest at the bottom of the ocean, nobody is finding it very easily. This subsequently has a ripple effect, as less exposure means fewer downloads, fewer downloads means less revenue and a direct blow to the wallet. An App’s fate is directly tied to its store rating, so a low rating can cast a shadow on the long term success of an App.
How to extract an App’s store ratings using Sematext
Monitoring an App’s store rating is like keeping a finger on the pulse of its success. It is vital to do so, because these store ratings directly correlate to a user’s general perception of the App. By keeping a close eye on these ratings, developers can get real-time feedback on what the users like or don’t like about the App. This is a crucial component in identifying and understanding where improvements need to be made. Essentially, a higher rating can significantly impact an App’s visibility and downloads, so monitoring it is imperative in tweaking the App store optimization (ASO) strategy and boosting its organic search ranking.
Armed with this knowledge, we will now explore how to use a Synthetic Browser Monitor to extract an App’s store ratings in both Google Play and Apple App Store, while also creating custom dashboards in Sematext to visualize the extracted data for further analysis.
Extracting metrics via User Journey Scripts
When creating a new Browser Monitor and selecting the option to Monitor a User Journey, there is a button named Browse Examples which contains several example User Journey Scripts for various different scenarios. For our purpose, we will use the example scripts Extract Google Play Store metrics for monitoring an App’s Google Play store rating and Extract Apple Store metrics for monitoring an App’s Apple Store rating.
Extracting Google Play store rating
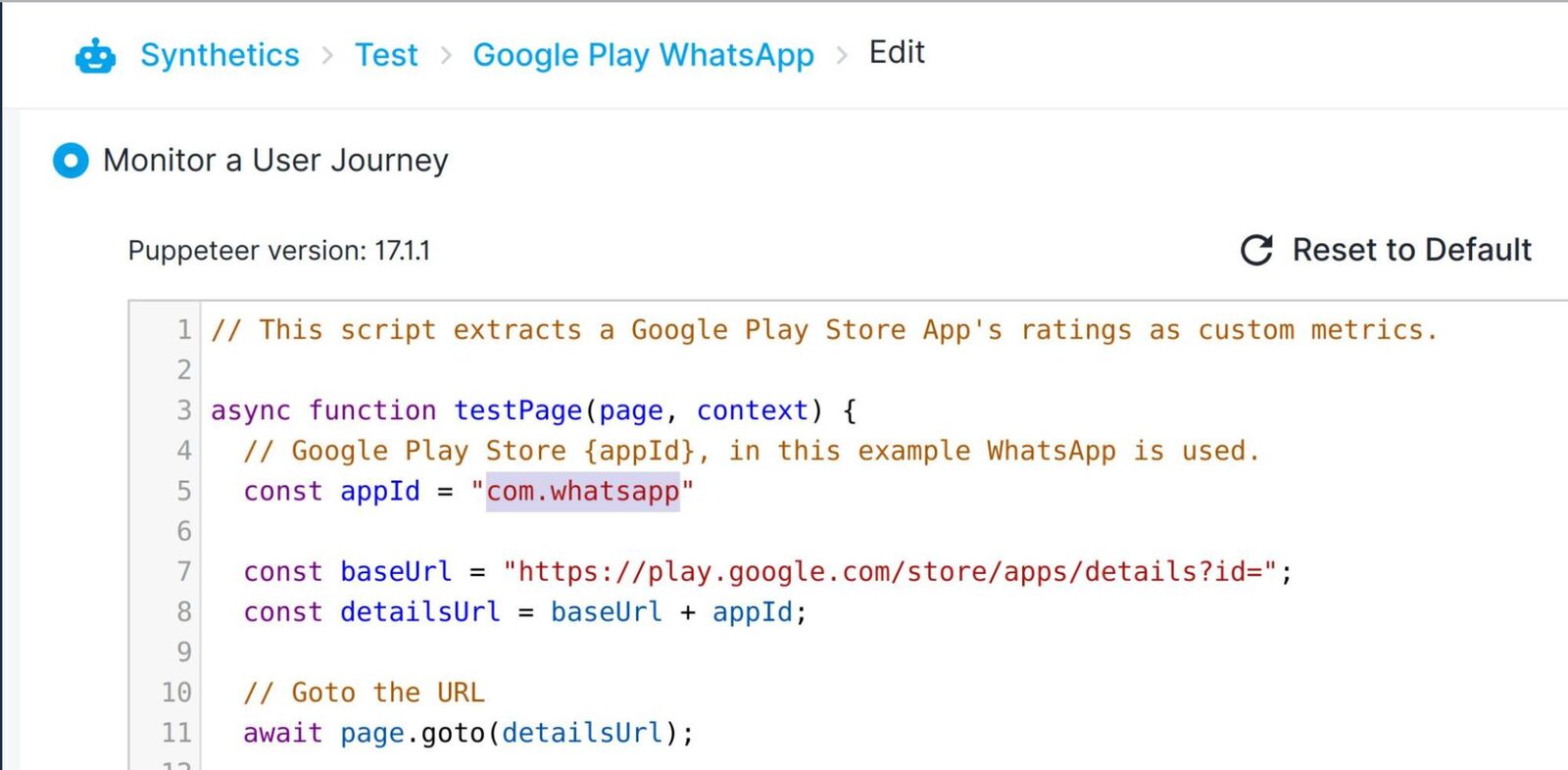
We will use the Extract Google Play Store metrics script to extract the Play Store rating. It is first necessary to configure the appId in the script to the Google Play store App ID of your App. We will be monitoring WhatsApp’s ratings in this guide, so we will leave the default com.whatsapp as the appId.
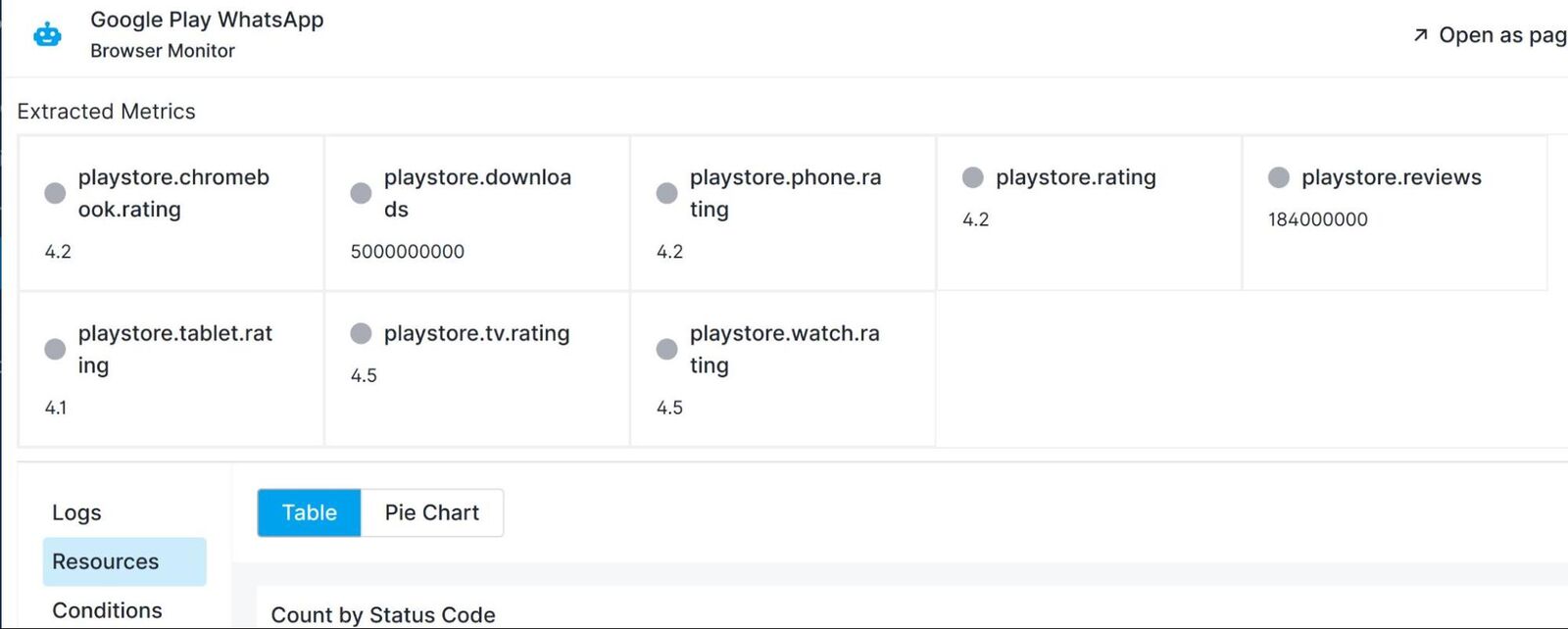
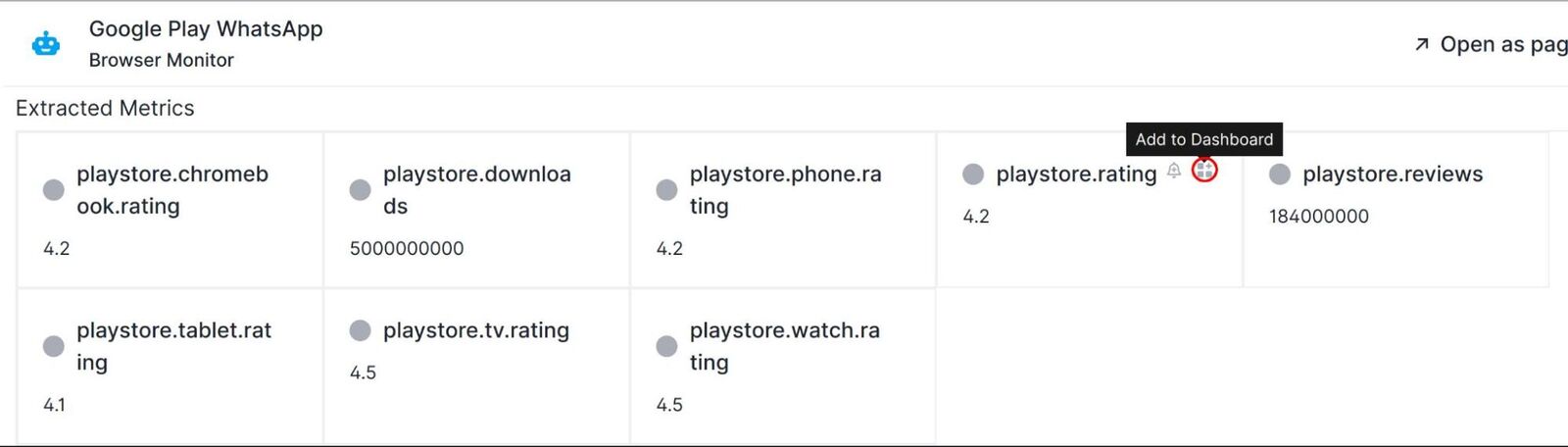
After saving the monitor and running it, the monitor run results show a successful run. Opening the run details we can see that the App’s store ratings for the different available device types and several other statistics were extracted as custom metrics:
Extracting Apple App Store rating
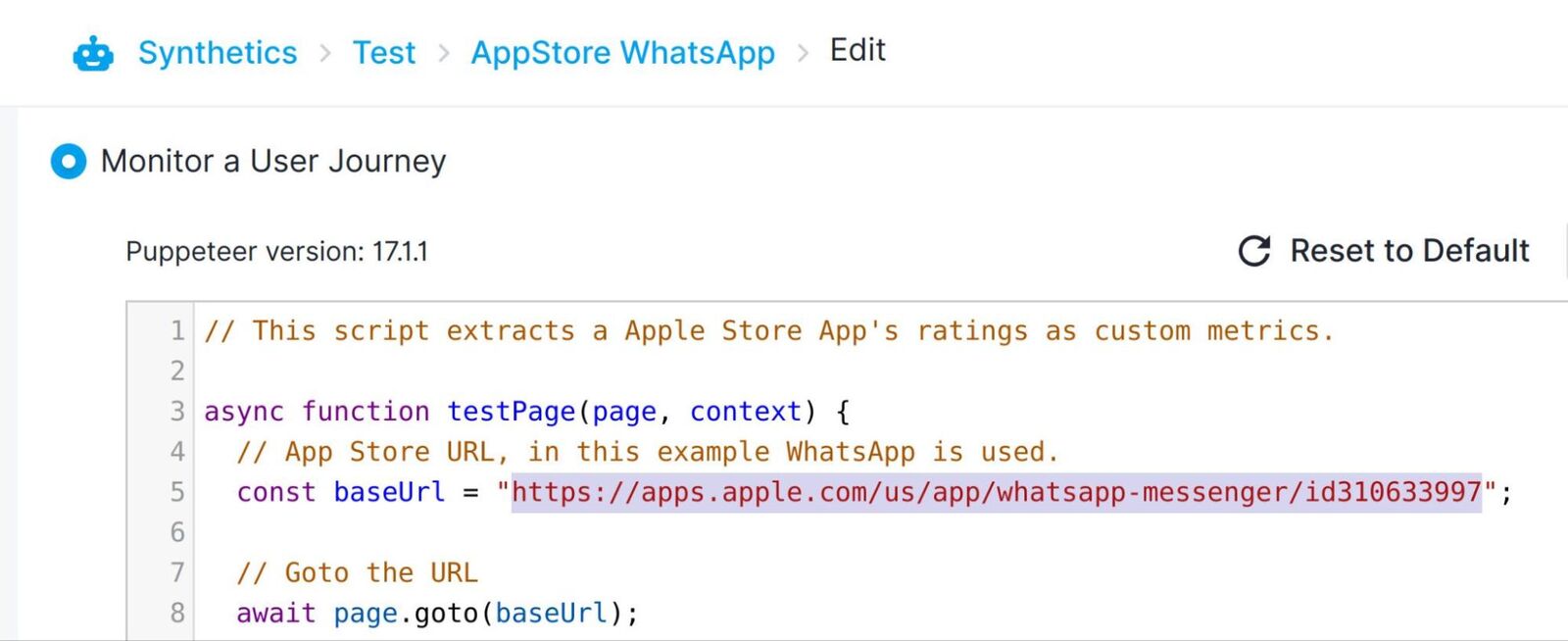
As with the Google Play store, we will use one of the example scripts, but this time for the Apple Store. For this we will use the Extract Apple Store metrics script to extract the App Store rating. As before, we will need to configure the script to point to our App. Unlike the Play Store however, it is necessary to provide the full URL to your App from the Apple App Store Preview website. As we are using WhatsApp for this guide, the Apple App Store Preview URL is “https://apps.apple.com/us/app/whatsapp-messenger/id310633997”, so we will leave this as the default.
After again saving the monitor and running it, we can see the monitor run results are now showing a successful run. If we open the run details overview, we can see that the App’s overall App Store rating and other statistics were extracted as custom metrics:
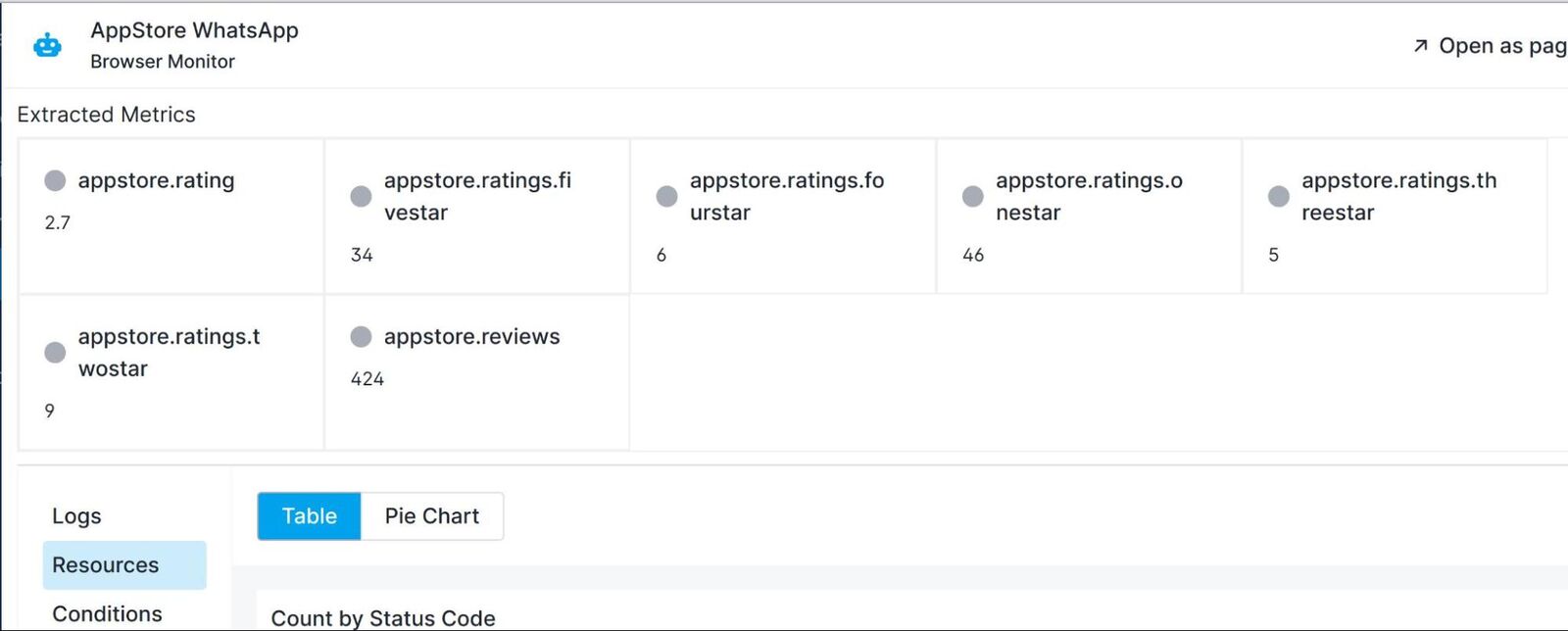
Visualizing the Extracted Data
With Sematext Dashboards, it is easy to add custom dashboards to visualize these metrics.
The easiest way to add the metrics to a custom dashboard however, is by using the Add to Dashboard button shown when hovering over the top-right corner of a custom metric in the run result overview page:
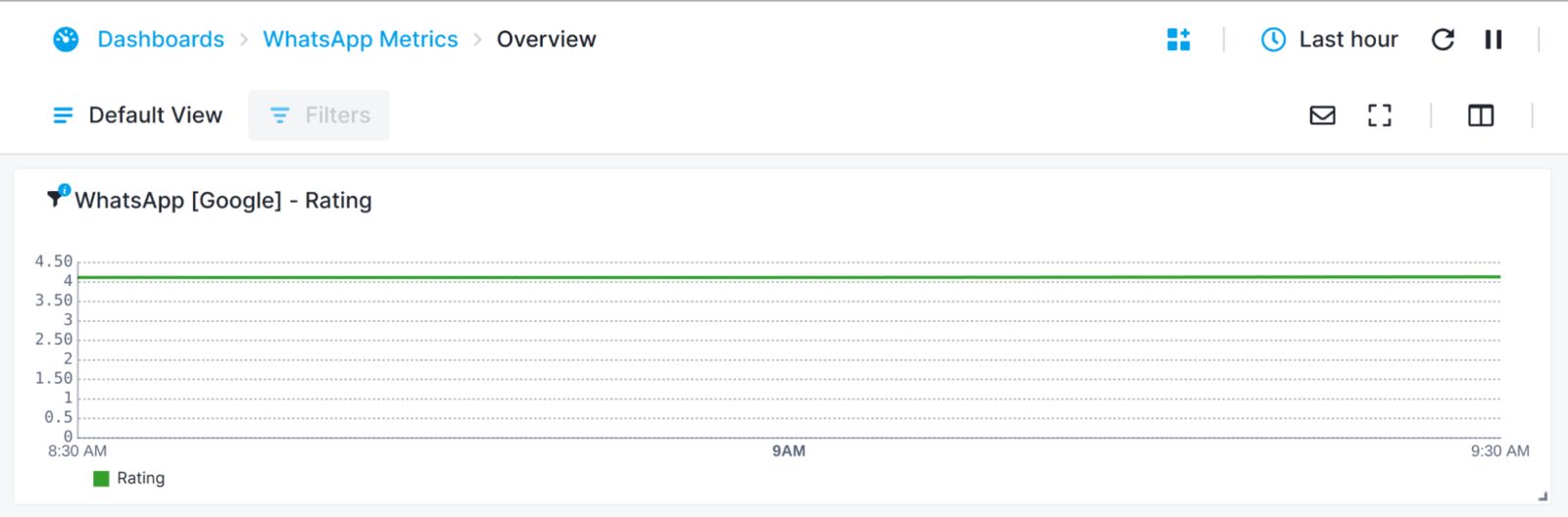
On the Add to Dashboard page, we will leave the Timeseries Chart option as this is the chart format we would like to use to display the rating. The Rollup by option is set to avg by default, we will change this to max. Also, as the lowest possible monitor execution interval for a Browser Monitor is 5m, we will also need to change the Granularity of our axis to correctly reflect this, here I will set this to 30 min. Now we will name the component and save it, adding it to our custom dashboard:
The same process can be repeated for any other custom metrics, until your custom dashboard is setup to your preference:
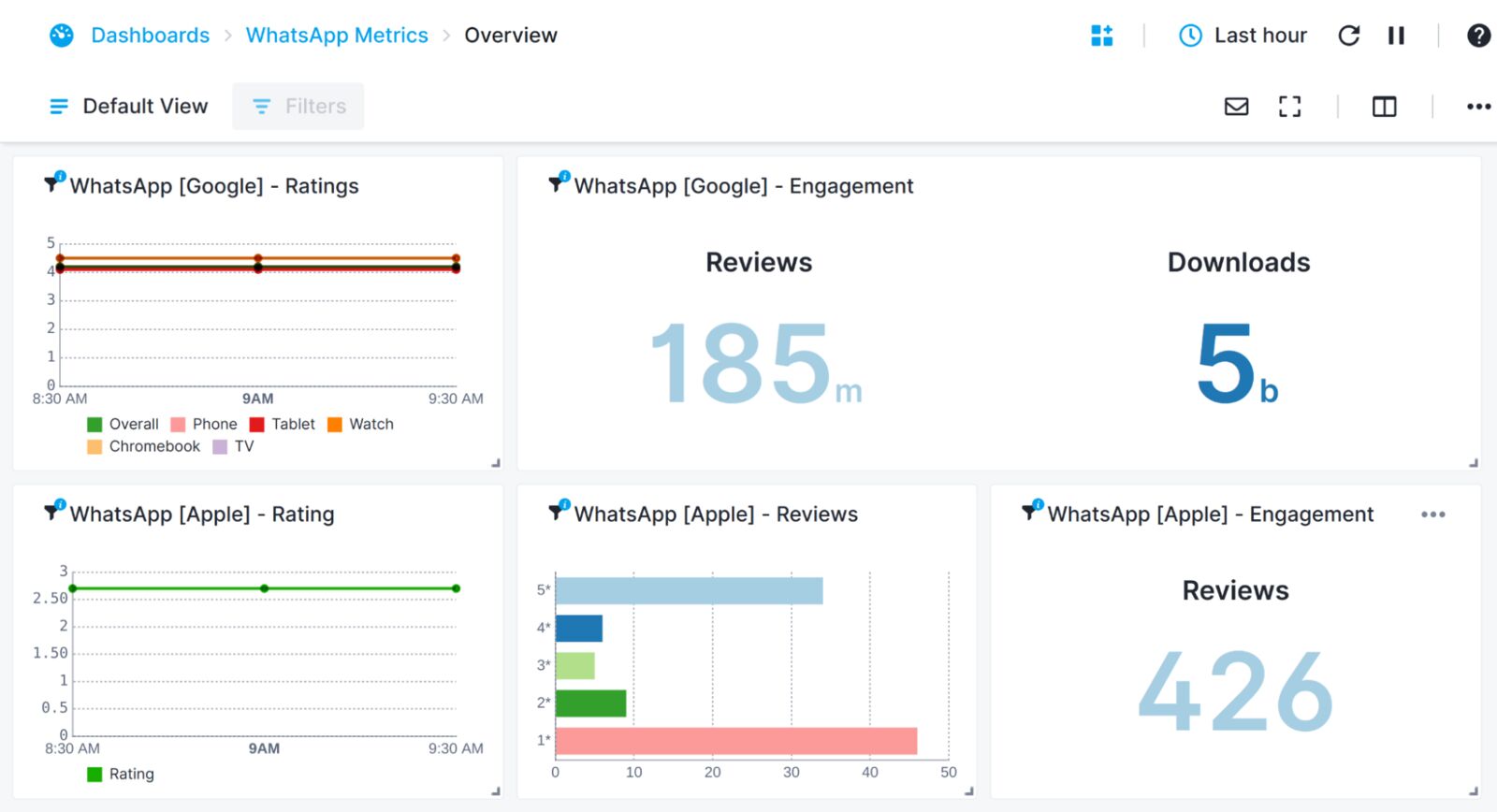
**Note: The Play Store and Apple Store ratings are unique for each country/region, the ratings may differ depending on the Synthetics Endpoint in use and the store ratings of that country. We recommend creating a separate monitor for each region, or selecting and monitoring just a single region.
Getting alerted when App rating drops
Now we will create an alert, which will notify us as soon as the App’s rating drops below 4.
For this, we will create a Threshold Alert on the rating metric. Hovering over the top-right corner of the chart, then clicking the Create alert rule button, will display the New Alert Rule window:
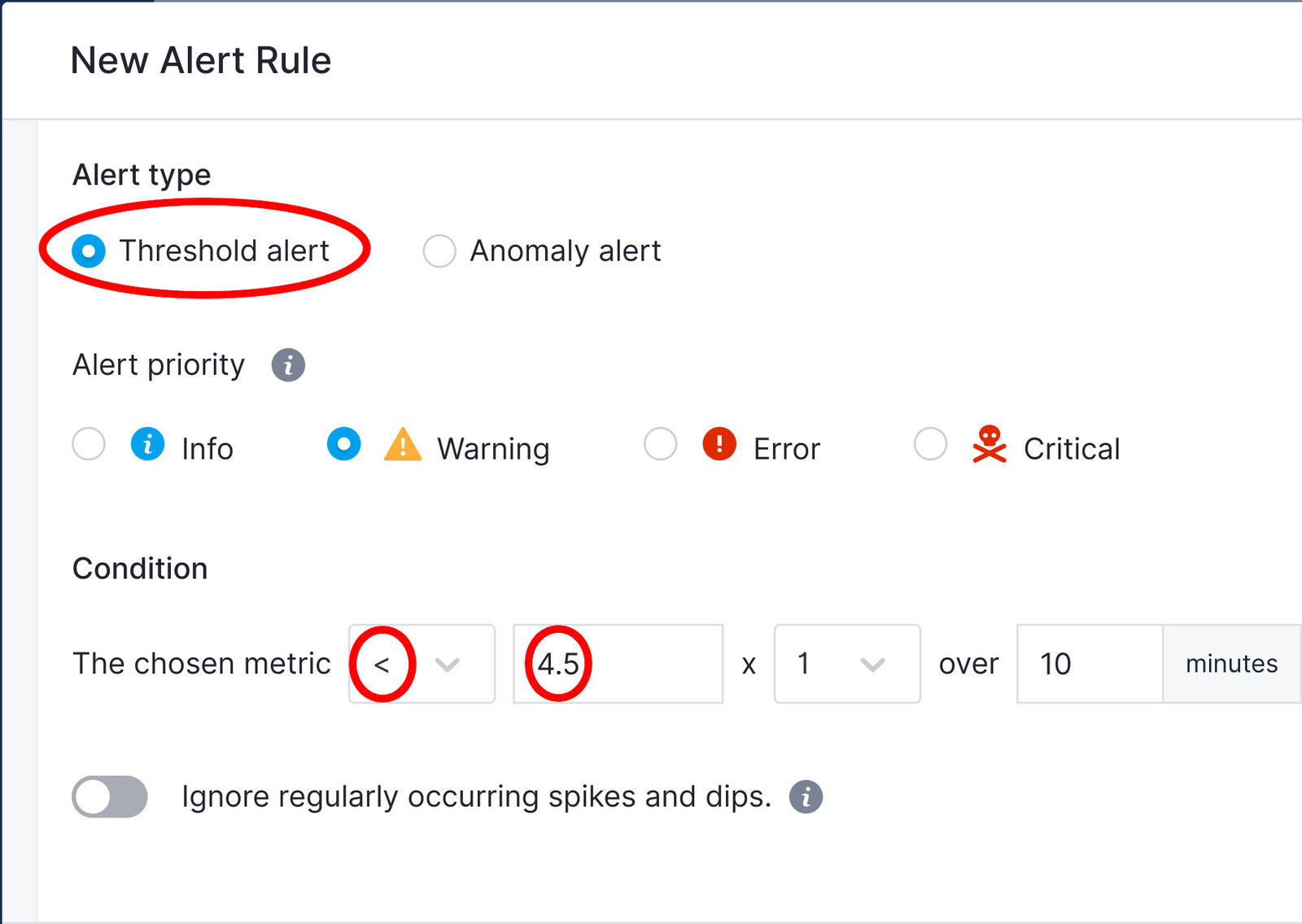
Now we will select Threshold Alert for the Alert Type. Under Condition, we will change the comparison operator to the lower than < symbol and in the text edit box we enter 4.5 as the value. Next, modify any other options as required and save the alert.
We will now be alerted immediately, as soon as the store rating drops below our chosen value of 4.5.
Getting Alerted when App ratings change
Now we will create an alert, which will notify us as soon as the App’s rating changes, regardless of whether it goes up or down. This is useful when your App’s rating is very constant and doesn’t really normally change and you want to know about any change in the rating without having to specify a threshold and then update it when the rating changes.
We will create an Anomaly Alert this time on the same rating metric as previously. As before, hover over the top-right corner of the chart, clicking the Create alert rule button, to display the New Alert Rule window.
This time we will select Anomaly Alert for the Alert Type. Modify any other options as required and save the alert.
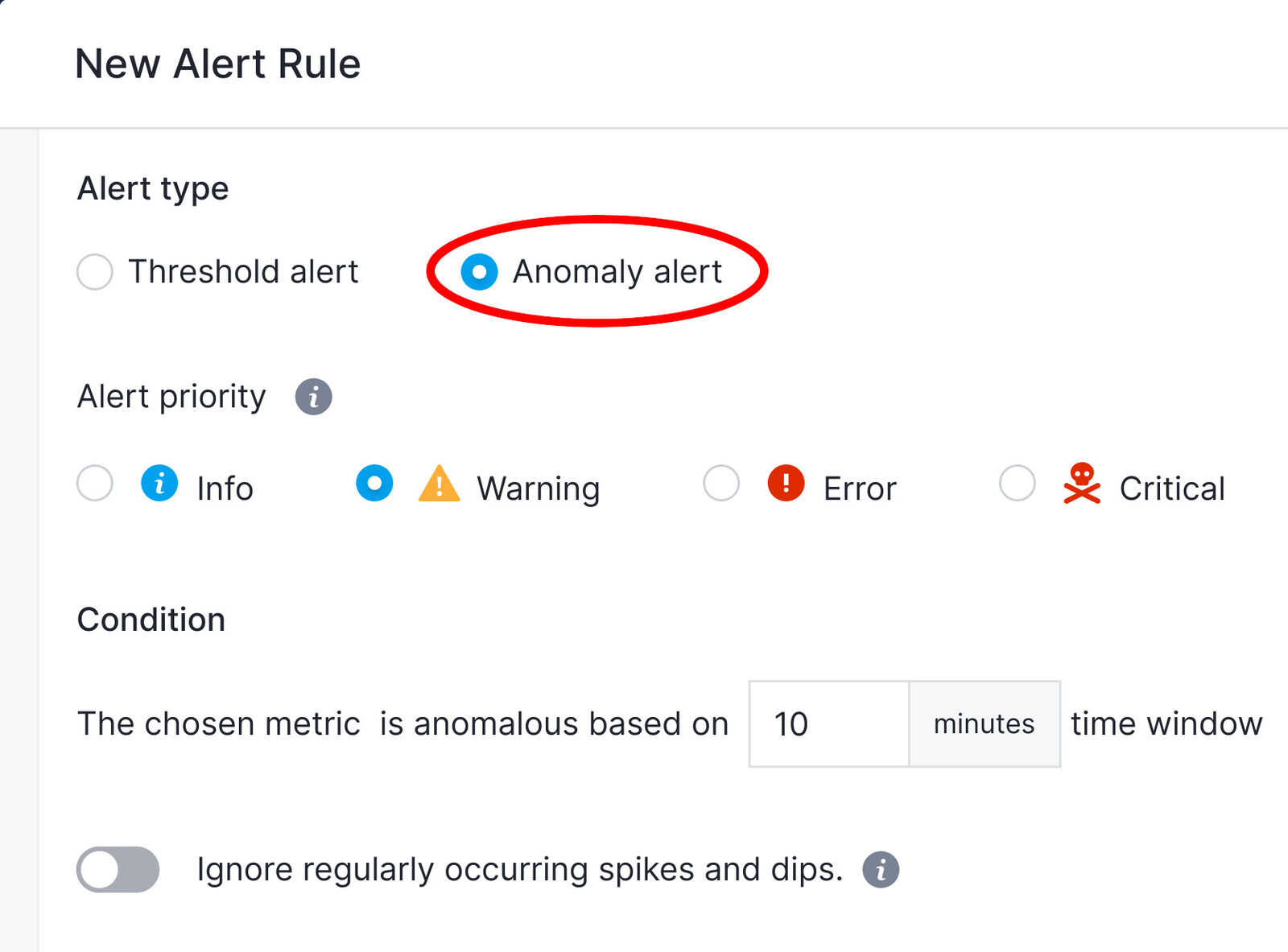
That’s all. We will now be notified immediately anytime the App rating changes.
Summary
In conclusion, Sematext Cloud provides a powerful way of extracting metrics from webpages, API endpoints, or browser APIs, charting them, and setting up alerting rules. You can track changes in another website or API or your own. When you monitor your own websites and APIs, and combine these with metrics and logs of services that are hosting these applications, you gain full stack visibility into your whole infrastructure.