Overview
Alerts are used to notify you when one or more pre-defined conditions in your metrics, logs, experience, or synthetics data are met.
For example, you might want to be notified when available disk space reaches a certain threshold – metrics alert, when the number of logs with severity: warning gets too high – logs alert, when your users start experiencing high response times – experience alert, or when a website or API monitor detects downtime or slow response times – synthetics alert.
Alert Types¶
Sematext Cloud includes multiple types of alerts that integrate with PagerDuty, Slack, email, and other 3rd party services.
- Threshold alerts are the classic threshold based alerts. They are triggered when a certain pre-defined threshold is met.
- Heartbeat alerts are triggered when Sematext Cloud stops receiving data from your server, container, application, etc.
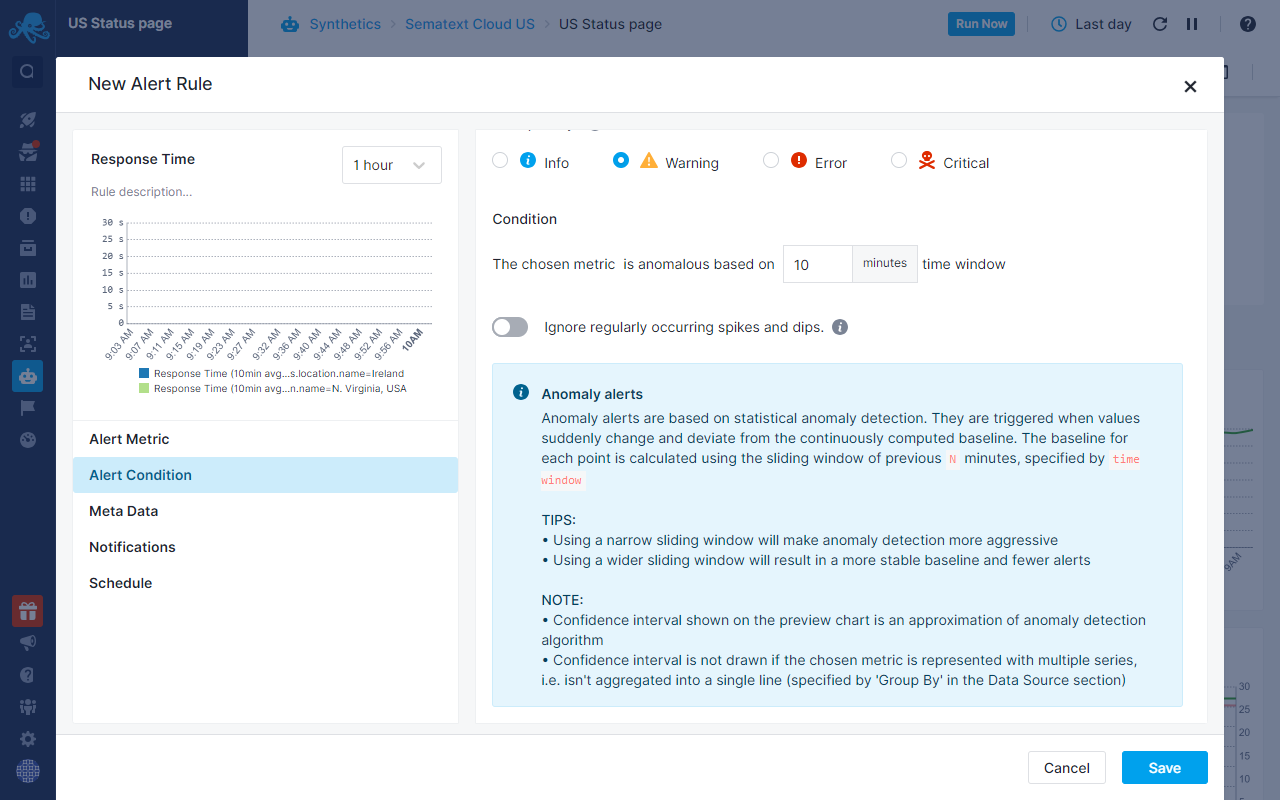
- Anomaly alerts are based on statistical anomaly detection. They are triggered when values suddenly change and deviate from the continously computed baseline.
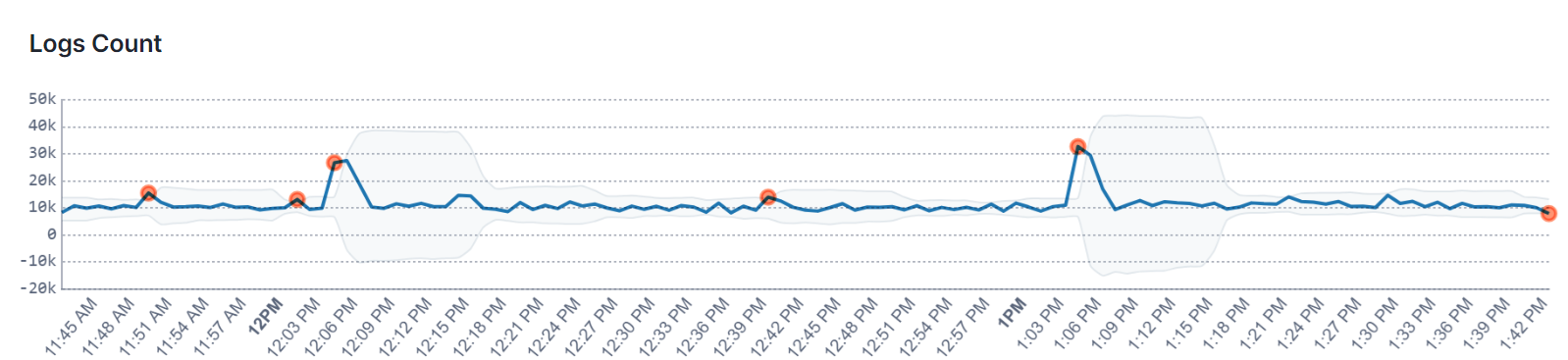
When an anomaly alert is triggered, you'll be able to observe spikes and dips within the alert details flyout upon clicking on the alert event. The chart also features a confidence band that illustrates the range of certainty around the expected values.
Alert Sources¶
Alerts can operate on three different sources of data:
- Metrics alerts work with infrastructure metrics
- Logs alerts are based on various types of logs
- Experience alerts are concerned with real user monitoring data - RUM
- Synthetics alerts monitor website and API performance through synthetic monitoring checks
| Alert type | Metrics | Logs | Experience | Synthetics |
|---|---|---|---|---|
| Threshold | yes | yes | yes | yes |
| Anomaly | yes | yes | yes | yes |
| Heartbeat | yes | no | no | no |
You can manage Alert rules interactively via the UI, or you can manage alerts via the API.
Alert Rules¶
Alert rules define the conditions under which alerts are triggered. They enable you to customize monitoring and other aspects based on your specific needs. For more information on creating and managing alert rules, check out the Alert Rules documentation.
Alert Events¶
Alert events represent the specific occurrences of triggered alerts within your Apps. For more information on how alert events work and how to manage them, visit the Alert Events documentation.
Alert Notifications¶
Alert notifications inform you when an alert is triggered. You can configure various notification channels to ensure that the right team members are alerted promptly. For detailed information on setting up alert notifications, refer to the Alert Notifications documentation.