
XDP or Express Data Path arises due to the pressing need for high-performance packet processing in the Linux kernel. Several kernel bypass techniques (DPDK being the most prominent one) aim to accelerate network operations by moving packet processing to user space.
This means ditching the overhead induced by context switches, syscall transitions or IRQ requests between the kernel-user space boundary. The operating system hands over the control of the networking stack to user space processes that directly interact with NIC through their own drivers.
Even though this approach results in a significant performance boost, it brings a series of drawbacks including reinventing the TCP/IP stack along with other networking functions in the user space or dropping the battle-tested kernel features that arm programs with powerful resource abstraction and security primitives.
The mission of XDP is to achieve programmable packet processing in the kernel while still retaining the fundamental building blocks of the networking stack. In fact, XDP represents a natural extension of eBPF instrumentation capabilities. It adopts the programming model built around maps, supervised helper functions and sandboxed bytecode that’s checked and loaded into the kernel in a safe fashion.
The key point of the XDP fast processing path is that the bytecode is attached at the earliest possible point in the network stack, right after the packet hits the network adapter receive (RX) queue. In this stage of the network stack none of the kernel packet traits are yet built which favors the immense speed gains in the packet processing path.
If you’ve missed my previous blog post about eBPF essentials, I’d encourage you to give it a read first. To highlight the position of XDP in the networking stack, let’s see the life of a TCP packet since it arrives on the NIC until it hits the destination socket in user space. Keep in mind this is going to be a high level overview. We’ll just scratch the surface of this complex beast which is the kernel networking stack.
Ingress packet flow through the network stack
Once the network card receives a frame (after applying all the checksums and sanity checks), it will use DMA to transfer packets to the corresponding memory zone. This means the packet is directly copied from the NIC’s queue to the main memory region mapped by the driver. When the ring buffer reception queue’s thresholds kick in, the NIC raises a hard IRQ and the CPU dispatches the processing to the routine in the IRQ vector table to run the driver’s code.
Since the driver execution path has to be blazingly fast, processing is deferred outside of the driver IRQ context by the mean of soft IRQs (NET_RX_SOFTIRQ). Given that IRQs are disabled during the execution of the interrupt handler, the kernel prefers to schedule long-running tasks out of the IRQ context to avoid the loss of any events that could occur while interrupt routine is busy. The device’s driver starts the NAPI loop and per-cpu kernel threads (ksoftirqd) consume packets from the ring buffer. The responsibility of the NAPI loop is primarily related to triggering soft IRQs (NET_RX_SOFTIRQ)to be processed by softirq handler that in turn sends up data to the network stack.
A new socket buffer (sk_buff) is allocated by the net device driver to accommodate the flow of inbound packets. The socket buffer represents the fundamental data structure for abstracting packet buffering/manipulation in the kernel. It also underpins all the upper layers in the network stack.
The socket buffer’s structure has several fields that identify different network layers. After consuming buffer sockets from CPU queues, the kernel fills the metadata, clones sk_buff and pushes it upstream into subsequent network layers for further processing. This is where the IP protocol layer is registered in the stack. The IP layer performs some basic integrity checks and hands over the packet to netfilter hooks. If the packet is not dropped by the netfilter, the IP layer inspects the high-level protocol and give the processing to the handler function for the previously extracted protocol.
Data is eventually copied to user space buffers where sockets are attached. Processes receive data either via the family of blocking syscalls (recv, read) or proactively via some polling mechanism (epoll) .
XDP hooks are triggered right after NIC copies the packet data to the RX queue, at which point we can effectively prevent allocations of various meta-data structures including sk_buffers. If we consider the simplest possible use case such as packet filtering in high-speed networks or nodes that are subject of DDoS attacks, traditional network firewall (iptables) solutions would inevitably swamp the machine due to the amount of workload introduced by each stage in the networking stack.
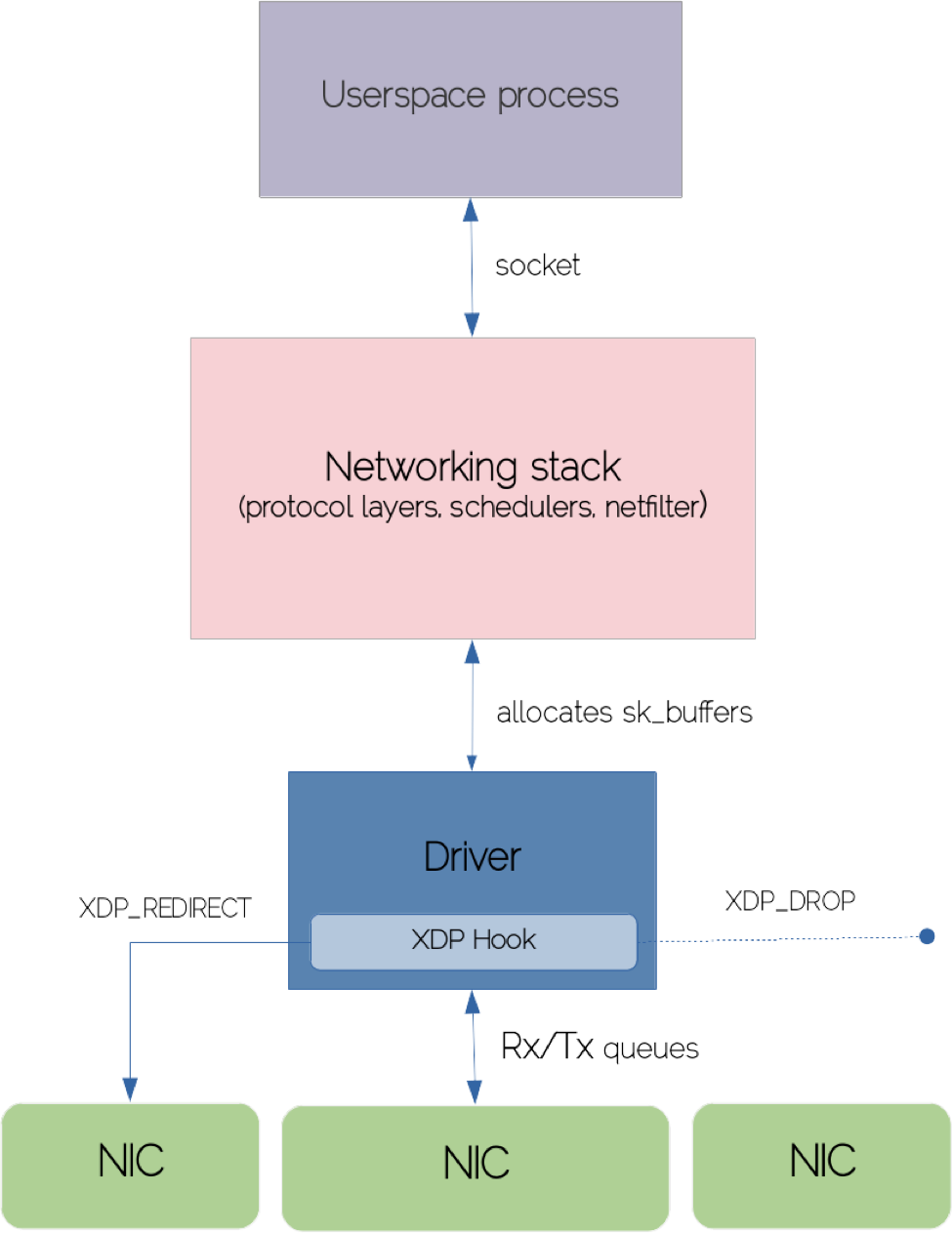
XDP hook in the networking stack
Specifically, iptables rules, which are scheduled in their own softirq tasks but also evaluated sequentially, would match at the IP protocol layer to decide whether the packet from a specific IP address is about to be dropped. On the contrary, XDP would directly operate on a raw Ethernet frame obtained from the DMA-backed ring buffer, so the dropping logic can occur prematurely, saving the kernel from immense processing that would lead to network stack latency and eventually to complete resource starvation.
XDP constructs
As you might already know, the eBPF bytecode can be attached on various strategic points like kernel functions, sockets, tracepoints, cgroup hierarchies or user space symbols. Thus, each type of eBPF program operates within particular context – the state of the CPU registers in case of kprobes, socket buffers for socket programs, and so on. In XDP parlance, the backbone of the resulting eBPF bytecode is modeled around XDP metadata context (xdp_md). XDP context contains all the needed data to access the packet at its raw form.
To better comprehend the key blocks of the XDP program, let’s dissect the following stanza:
#include <linux/bpf.h>
#define SEC(NAME) __attribute__((section(NAME), used))
SEC("prog")
int xdp_drop(struct xdp_md *ctx) {
return XDP_DROP;
}
char __license[] SEC("license") = "GPL";
This is the minimal XDP program that once attached on a network interface drops every packet. We start by importing the bpf header that brings in the definitions of various structures including the xdp_md structure. Next, we declare the SEC macro to place maps, functions, license metadata and other elements in ELF sections that are introspected by eBPF loader.
Now comes the most relevant part of our XDP program that deals with packet’s processing logic. XDP ships with a predefined set of verdicts that determine how the kernel diverts the packet flow. For instance, we can pass the packet to the regular network stack, drop it, redirect the packet to another NIC and such. In our case, XDP_DROP yields an ultra-fast packet drop. Also note that we’ve anchored the prog section in our function that eBPF loader is expecting to encounter (the program will fail to load if different section name is found, however we can instruct ip to use a non-standard section name). Let’s compile the program above and give it a try.
$ clang -Wall -target bpf -c xdp-drop.c -o xdp-drop.o
The binary object can be loaded into the kernel with different userspace tools (part of iproute2 suite), tc or ip being most widely utilized. XDP supports veth (virtual ethernet) interfaces, so an instant way to see our program in action is to offload it to an existing container interface. We’ll spin up a nginx container and launch a couple of curls before and after attaching the XDP program on the interface. The first attempt of curling the nginx root context results in a successful HTTP status code:
$ curl --write-out '%{http_code}' -s --output /dev/null 172.17.0.4:80
200
Loading the XDP bytecode can be accomplished with the following command:
$ sudo ip link set dev veth74062a2 xdp obj xdp-drop.o
We should see the xdp flag activated in the veth interface:
veth74062a2@if16: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp/id:37 qdisc noqueue master docker0 state UP group default link/ether 0a:5e:36:21:9e:63 brd ff:ff:ff:ff:ff:ff link-netnsid 2 inet6 fe80::85e:36ff:fe21:9e63/64 scope link valid_lft forever preferred_lft forever
The subsequent curl requests will hang for a while before failing with an error message like below, which effectively confirms the XDP hook is working as expected:
curl: (7) Failed to connect to 172.17.0.4 port 80: No route to host
When we’re done with our experiments the XDP program can be unloaded via:
$ sudo ip link set dev veth74062a2 xdp off
Programming XDP in Go
The previous code snippet demonstrated some basic concepts, but to leverage the super powers of XDP we are going to craft slightly more sophisticated piece of software using the Go language – a small tool built around a sort of canonical use case: dropping packets for particular blacklisted IP addresses. The full source code along with instructions on how to build the tool are available in the repository right here. As in the previous blog post, we utilize the gobpf package that provides the pillars for interacting with the eBPF VM (loading programs into the kernel, accessing/manipulating eBPF maps and much more). A plenty of eBPF program types can directly be written in C and compiled to ELF object files. Unfortunately, XDP ELF-based programs are not covered yet. As an alternative, attaching XDP programs is still possible via BCC modules at the cost of dealing with libbcc dependencies.
Nevertheless, there is an important limitation in BCC maps that prevents them from being pinned on the bpffs (in fact, you can pin maps from user space but during the bootstrap of the BCC module it happily ignores any pinned objects). Our tool needs to inspect the blacklist map, but also have the ability to add/remove elements from it after the XDP program is attached on the network interface and the main process exits.
That was enough motivation to consider supporting XDP programs in ELF objects, so we submitted the pull request with hopes of incorporating it in the upstream repo. We think this is a valuable addition to favor the portability of XDP programs similarly to how kernel probes can be distributed across machines even if they don’t ship with clang, LLVM and other dependencies.
Without further ado, let’s skim through the most important snippets starting with the XDP code:
SEC("xdp/xdp_ip_filter")
int xdp_ip_filter(struct xdp_md *ctx) {
void *end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
u32 ip_src;
u64 offset;
u16 eth_type;
struct ethhdr *eth = data;
offset = sizeof(*eth);
if (data + offset > end) {
return XDP_ABORTED;
}
eth_type = eth->h_proto;
/* handle VLAN tagged packet */
if (eth_type == htons(ETH_P_8021Q) || eth_type ==
htons(ETH_P_8021AD)) {
struct vlan_hdr *vlan_hdr;
vlan_hdr = (void *)eth + offset;
offset += sizeof(*vlan_hdr);
if ((void *)eth + offset > end)
return false;
eth_type = vlan_hdr->h_vlan_encapsulated_proto;
}
/* let's only handle IPv4 addresses */
if (eth_type == ntohs(ETH_P_IPV6)) {
return XDP_PASS;
}
struct iphdr *iph = data + offset;
offset += sizeof(struct iphdr);
/* make sure the bytes you want to read are within the packet's range before reading them */
if (iph + 1 > end) {
return XDP_ABORTED;
}
ip_src = iph->saddr;
if (bpf_map_lookup_elem(&blacklist, &ip_src)) {
return XDP_DROP;
}
return XDP_PASS;
}
It might look a bit intimidating, but for instance let’s ignore the code block responsible for handling VLAN tagged packets. We start by accessing packet data from the XDP metadata context and cast the pointer to the ethddr kernel structure. You also may notice several conditions that check byte boundaries within the packet. If you omit them, the verifier will refuse to load the XDP bytecode. This enforces rules that guarantee to run XDP programs without causing mayhem in the kernel if code references invalid pointers or violates safety policies. The remaining part of the code extracts the source IP address from the IP header and checks its presence in the blacklist map. If lookup is successful, the packet is dropped.
The Hook structure is in charge of attaching/detaching XDP programs in the network stack. It instantiates and loads the XDP module from object file and calls into AttachXDP or RemoveXDP methods.
The blacklist of IP addresses is managed through standard eBPF maps. We call UpdateElement and DeleteElement to register or remove entries respectively. Blacklist manager also contains a method for listing available IP addresses in the map.
The rest of the code glues all the pieces together to give a nice CLI experience that users can exploit to perform XDP program attaching/removal and the manipulation of the IP blacklist. For further details, please head to the sources.
Conclusions
XDP is slowly emerging as the standard for fast packet processing in the Linux kernel. Throughout this blog post I’ve explained the fundamental building blocks that comprise the packet processing ecosystem. Although the networking stack is a complex subject, creating XDP programs is relatively painless due to the programmable nature of eBPF/XDP.