
If you’re using rsyslog for processing lots of logs (and, as we’ve shown before, rsyslog is good at processing lots of logs), you’re probably interested in monitoring it. To do that, you can use impstats, which comes from input module for process stats. impstats produces information like:
– input stats, like how many events went through each input
– queue stats, like the maximum size of a queue
– action (output or message modification) stats, like how many events were forwarded by each action
– general stats, like CPU time or memory usage
In this post, we’ll show you how to send those stats to Elasticsearch (or Logsene — essentially hosted ELK, our log analytics service) that exposes the Elasticsearch API), where you can explore them with a nice UI, like Kibana. For example get the number of logs going through each input/output per hour:
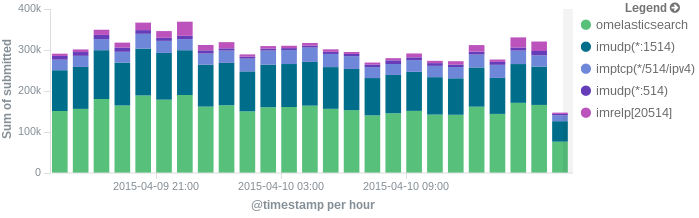
More precisely, we’ll look at:
– the useful options around impstats
– how to use those stats and what they’re about
– how to ship stats to Elasticsearch/Logsene by using rsyslog’s Elasticsearch output
– how to do this shipping in a fast and reliable way. This will apply to most rsyslog use-cases, not only impstats
Configuring impstats
Before starting, make sure you have a recent version of rsyslog. You can find the latest version (8.9.0 at the time of this writing), as well as packages for various distributions here. Many distributions still ship ancient versions like 5.x, which probably have impstats, but some of the features (like Elasticsearch output) may not be available.
Once you’re there, load the impstats module at the beginning of your config:
module( load="impstats" interval="10" # how often to generate stats resetCounters="on" # to get deltas (e.g. # of messages submitted in the last 10 seconds) log.file="/tmp/stats" # file to write those stats to log.syslog="off" # don't send stats through the normal processing pipeline. More on that in a bit )
At this point, if you restart rsyslog, you should see stats about all the inputs, queues, actions, as well as overall resource usage. For example, the stats below come from an rsyslog that takes messages over TCP and sends them over to Elasticsearch in Logstash-like format:
Thu Apr 9 16:45:36 2015: omelasticsearch: origin=omelasticsearch submitted=11000 failed.http=0 failed.httprequests=0 failed.es=0 Thu Apr 9 16:45:36 2015: send-to-es: origin=core.action processed=10405 failed=0 suspended=0 suspended.duration=0 resumed=0 Thu Apr 9 16:45:36 2015: imtcp(13514): origin=imtcp submitted=6618 Thu Apr 9 16:45:36 2015: resource-usage: origin=impstats utime=2109000 stime=2415000 maxrss=53236 minflt=12559 majflt=1 inblock=8 oublock=0 nvcsw=164893 nivcsw=384355 Thu Apr 9 16:45:36 2015: main Q: origin=core.queue size=65095 enqueued=7149 full=0 discarded.full=0 discarded.nf=0 maxqsize=70000
Wait. What are these stats?
Here’s my take on each line:
1. omelasticsearch (output module to Elasticsearch) sent 11K logs to ES in the last 10 seconds. There were no connectivity errors, nor any errors thrown by Elasticsearch (like you would get if you tried to index a string in an integer field)
2. the “send-to-es” action (which uses omelasticsearch) took a bit less than 11K logs from the main queue to send them to omelasticsearch. I assume the rest of them were sent before this 10 second window. Not terribly useful, but if there was a connectivity issue with Elasticsearch, you’d see how long this action was suspended
3. the TCP input received 6.6K logs in the last 10 seconds
4. rsyslog used ~2 seconds of user CPU time (utime=2109000 microseconds) and ~2.5s of system time. It used 53MB of RAM at most. You can see what all these abreviations mean by looking at getrusage’s man page
5. the default (main) queue currently buffers 65K messages from the inputs (though it went as high as 70K in the last 10 seconds), 7K of which were taken in the last 10 seconds
Shipping Stats to Elasticsearch/Logsene
Now that we have these stats, let’s centralize them to Elasticsearch. If you’re using rsyslog to push to Elasticsearch, it’s better to use another cluster or Logsene for stats. Otherwise, when Elasticsearch is in trouble, you won’t be able to see stats which might explain why you’re having trouble in the first place.
Either way, we need four things:
– produce those stats in JSON, so we can parse them easily
– define a template for how JSON documents that we send to Elasticsearch will look like
– parse the JSON stats
– send those documents to Logsene/Elasticsearch using the defined template
Here’s the relevant config snippet for sending to Logsene:
module(
load="impstats"
interval="10"
resetCounters="on"
format="cee" # produce JSON stats
)
module(load="mmjsonparse")
module(load="omelasticsearch")
#template for building the JSON documents that will land in Logsene/Elasticsearch
template(name="stats"
type="list") {
constant(value="{")
property(name="timereported" dateFormat="rfc3339" format="jsonf" outname="@timestamp") # the timestamp
constant(value=",")
property(name="hostname" format="jsonf" outname="host") # the host generating stats
constant(value=","source":"impstats",") # we'll hardcode "impstats" as a source
property(name="$!all-json" position.from="2") # finally, we'll add all metrics
}
action(
name="parse_impstats" # parse the
type="mmjsonparse" # JSON stats
)
action(
name="impstats_to_es" # name actions so you can see them in impstats messages (instead of the default action 1, 2, etc)
type="omelasticsearch"
server="logsene-receiver.sematext.com" # host and port for Logsene/Elasticsearch
serverport="80" # set serverport="443" and add usehttps="on" for using HTTPS instead of plain HTTP
template="stats" # use the template defined earlier
searchIndex="LOGSENE_APP_TOKEN_GOES_HERE"
searchType="impstats" # we'll use a separate mapping type for stats
bulkmode="on" # use Elasticsearch's bulk API
action.resumeretrycount="-1" # retry indefinitely on failure
)
That’s all you basically need to be sending stats to Logsene/Elasticsearch: load the impstats, mmjsonparse and omelasticsearch modules, define the template, parse stats and send them over. Note that while impstats comes bundled with most rsyslog packages, you need to install rsyslog-mmjsonparse and rsyslog-elasticsearch packages to install the other two plugins.
Using a separate ruleset and configuring its queue
Before wrapping up, let’s address two potential issues. First is that, by default, impstats will send stats events to the main queue (all input modules do that by default). This will mix stats with other logs, which has a couple of disadvantages:
– you need to add a conditional to make sure only impstats events go to the impstats-specific destination
– if rsyslog is queueing lots of messages in the main queue, stats can land in Elasticsearch with a delay
To avoid these problems, you can bind impstats to a separate ruleset. Let’s call it “monitoring”. rsyslog will then process them separately from the main queue, which is associated to the default ruleset.
You can have as many rulesets as you want, and they’re typically used to separate different types of logs. For example to process local logs and remote logs independently. Like the default ruleset which has the main queue, any ruleset can have its own queue (also, each action, no matter the ruleset it’s in, can have its own queue – more info on that here, here and here). Why am I talking about queues? Because if stats are important, you want to make sure you are able to queue them, instead of losing them if Elasticsearch becomes unavailable for a while.
By default, the default ruleset comes with an in-memory queue of 10K or so messages. Additional rulesets have no queue by default, but you can add one by specifying queue options (you can find the complete list here).
While in-memory queues are fast, they are typically small and you’d lose their contents if you have to shut down or restart rsyslog. In the following config snippet will add a disk-assisted queue to the “monitoring” ruleset. A disk assisted queue will normally be as fast as an in-memory queue, and will spill logs to disk in a performance-friendly way if it’s out of space. You can also make rsyslog save all logs to disk when you shut it down or restart it.
module(
load="impstats"
interval="10"
resetCounters="on"
format="cee"
ruleset="monitoring" # send stats to the monitoring ruleset
)
# add here modules and template from the previous snippet
ruleset(
name="monitoring" # the monitoring ruleset defined earlier
queue.type="FixedArray" # we'll have a fixed memory queue for this ruleset
queue.highwatermark="50000" # at least until it contains 50K stats messages
queue.spoolDirectory="/var/run/rsyslog/queues" # at which point, start writing in-memory messages to disk
queue.filename="stats_ruleset"
queue.lowwatermark="20000" # until the memory queue goes back to 20K, at which point the memory queue is used again
queue.maxdiskspace="100m" # the queue will be full when it occupies 100MB of space on disk
queue.size="5000000" # this is the total queue size (shouldn't be reachable)
queue.dequeuebatchsize="1000" # how many messages from the queue to process at once (also determines how many messages will be in an ES Bulk)
queue.saveonshutdown="on" # save queue contents to disk at shutdown
){
# add here actions from the previous snippet
}
Summary
This was quite a long post, so let me summarize the features of rsyslog we touched on:
– impstats is an input module that can generate stats about rsyslog’s inputs, queues and actions, as well as general process statistics
– you normally want to write them to a file in a human-readable format for development/debugging or local performance tests
– for production, it’s best to write them in JSON, parse them in a separate ruleset and send them to Logsene/Elasticsearch, where you can search and graph them
– you can use disk-assisted queues to increase the capacity of an in-memory queue without losing performance under normal conditions. It can also save logs to disk on shutdown to make sure important stats are not lost
If you find working with logs and/or Elasticsearch exciting, that’s what we do in lots of our products, consulting and support engagements. So if you want to join us, we’re hiring worldwide.