
In this post you will learn how to control ElasticSearch shard placement. If you are coming to our ElasticSearch talk at BerlinBuzzwords, we’ll be talking about this and more.
If you’ve ever used ElasticSearch you probably know that you can set it up to have multiple shards and replicas of each index it serves. This can be very handy in many situations. With the ability to have multiple shards of a single index we can deal with indices that are too large for efficient serving by a single machine. With the ability to have multiple replicas of each shard we can handle higher query load by spreading replicas over multiple servers. Of course, replicas are useful for more than just spreading the query load, but that’s another topic. In order to shard and replicate ElasticSearch has to figure out where in the cluster it should place shards and replicas. It needs to figure out which server/nodes each shard or replica should be placed on.
Lets Start
Imagine the following situation. We have 6 nodes in our ElasticSearch cluster. We decided to have our index split into 3 shards and in addition to that we want to have 1 replica of each shard. That gives us 6 shards total for our index – 3 shards plus 3*1 replicas. In order to have shards evenly distributed between nodes we would ideally like to have them placed one on each node. However, until version 0.19.0 of ElasticSearch this was not always the case out of the box. For instance, one could end up with an unbalanced cluster as shown in the following figure.
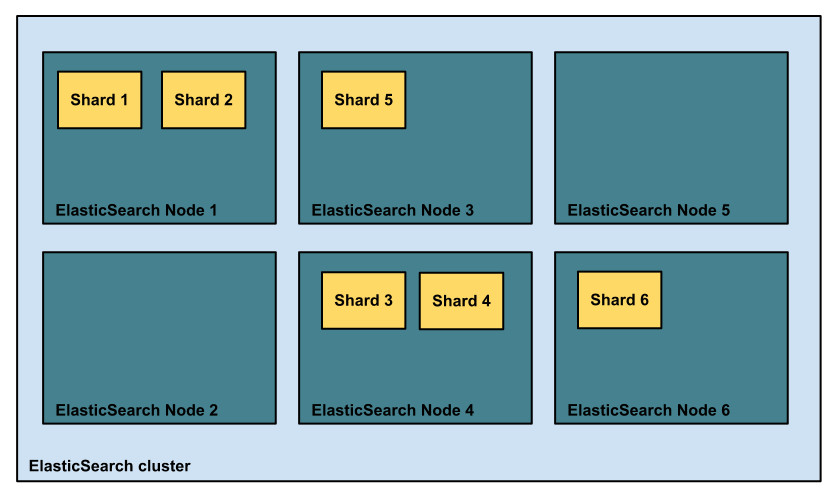
As you can see, this is far from perfect. Of course, one may say that rebalacing could be done to fix this. True, but as we’ve seen in our client engagements involving very large ElasticSearch clusters, shard/replica rebalancing is not something one should take lightly. It ain’t cheap of super quick – depending on your cluster size, index size, and shard/replica placement, rebalancing could take time and make your cluster sweat. So what can we do? Can we control it? Of course we can, otherwise we’d have nothing to write about. Moreover, not only can we control it, in complex and large ElasticSearch clusters it is arguable that one should control it. So how do we do it? ElasticSearch lets you control shard and replica allocation on cluster and index level and we’ll try to show you what you can achieve using ElasticSearch configuration and REST API.
Specifying the Number of Shards Per Node
The first thing we can control is the total number of shards that can be placed on a single node. In our simple 6-node deployment example we would set this value to 1, which would mean that we want a maximum of 1 shard of a given index on a single node. This can be handy when you want to distribute shards evenly in our example above. But we can imagine a situation where that is not enough.
Allocating Nodes for New Shards
ElasticSearch lets you specify nodes to include when deciding where shards should be placed. To use that functionality you need to specify additional configuration parameter that will let ElasticSearch recognize your nodes or group of nodes in the cluster. Lets get deeper into our above example and lets divide the nodes in 2 zones. The first 3 nodes will be associated with zone_one and the rest of the nodes will be associated with zone_two. So for the first 3 nodes you would add the following value to the ElasticSearch configuration file:
node.zone = zone_one
and for the other 3 nodes the following value:
node.zone = zone_two
The above specified attribute name can be different, of course – you can use anything you want as long as it doesn’t interfere with other ElasticSearch configuration parameters.
So we divided our cluster into two ‘zones’. Now, if we would like to have two indices, one placed on zone_one nodes and the the other index placed on zone_two nodes we would have to include an additional command when creating an index. To create an index on zone_one nodes we’d use the following command:
curl -XPUT 'localhost:9200/sematext1' -d '{
"index.routing.allocation.include.zone" : "zone_one"
}'
Then to create the second index on zone_two nodes we’d use the following command:
curl -XPUT 'localhost:9200/sematext2' -d '{
"index.routing.allocation.include.zone" : "zone_two"
}'
By specifying the cluster.routing.allocation.include.zone parameter we tell ElasticSearch that we want only nodes with the given parameter value to be included in shard allocation. Of course, we can have multiple includes specified during a single index creation. The following is also correct and will tell ElasticSearch to create an index on all nodes from our example:
curl -XPUT 'localhost:9200/sematext2' -d '{
"index.routing.allocation.include.zone" : "zone_one",
"index.routing.allocation.include.zone" " "zone_two"
}'
Remember that ElasticSearch will only use the nodes we specified for index creation. No other nodes will be used.
Excluding Nodes from Shard Placement
Just like we’ve included nodes for shard placement, we can also exclude them. This is done exactly the same way as with including, but instead of specifying cluster.routing.allocation.include parameter we specify cluster.routing.allocation.exclude parameter. Lets assume we have more than 2 zones defined and we want to exclude a specific zone, for example zone_one, from shard placement for one of our indices. We could specify the cluster.routing.allocation.include parameters for all the zones except zone_one or we can just use the following command:
curl -XPUT 'localhost:9200/sematext' -d '{
"index.routing.allocation.exclude.zone" : "zone_one"
}'
The above command will tell ElasticSearch to exclude zone_one from shard placement and place shards and replicas of that index only on the rest of the cluster.
IP Addresses Instead of Node Attributes
The include and exclude definitions can also be specified without using node attributes. You can use node IP address instead. In order to do that, you specify the special _ip attribute instead of attribute name. For example, if you would like to exclude node with IP 10.1.1.2 from shards placement you would set the following configuration value:
"cluster.routing.allocation.exclude._ip" : "10.1.1.2"
Cluster and Index Level Settings
All the settings described above can be specified on cluster level or on the index level. This way you can control how your shards are placed either globally for the whole cluster or in a different manner for each index. In addition to that, all the above setting can be changed during run-time using ElasticSearch REST API. For example, to include only nodes with IP 10.1.1.2 and 10.1.1.3 for the ‘sematext’ index, we’d use the following command:
curl -XPUT 'localhost:9200/sematext' -d '{
"index.routing.allocation.include._ip" : "10.1.1.2,10.1.1.3"
}'
To specify this at the cluster level we’d use the following command instead:
curl -XPUT 'localhost:9200/_cluster/settings' -d '{
"cluster.routing.allocation.include._ip" : "10.1.1.2,10.1.1.3"
}'
Visualizing Shard Placement
It’s 2012 and people like see information presented visually. If you’d like to see how your shards are placed in your ElasticSearch cluster, have a look at Scalable Performance Monitoring, more specifically SPM for ElasticSearch. This is what shard placement looks like in SPM:

What you can see in the screenshot above is that the number of shards and their placement was constant during the selected period of time. OK. But, more importantly, what happens if ElasticSearch is rebalancing shards and replicas across the cluster. This is what SPM shows when things are not balanced and when shards and replicas are being moved around the cluster:

The Future
Right now the situation with shard placement is not bad although it is not ideal either. On the other hand, the future is bright – in ElasticSearch 0.20 new shard placement mechanism is expected, so let’s cross our fingers, because we may get an even better search engine soon. Right now, what you can do, is plan and control where your index shards and replicas are placed by using ElasticSearch shard allocation control which do its job well.
We’re Hiring
If you are looking for an opportunity to work with ElasticSearch, we’re hiring. We are also looking for talented engineers to join our SPM development team.