
Half of the world, Sematext included, seems to be using Kafka.
Kafka is the spinal cord that connects various components in SPM and Logsene. If Kafka breaks, we’re in trouble (but we have anomaly detection all over the place to catch issues early). In many Kafka deployments, ours included, the most recent data is the most valuable. Consider the case of Kafka in SPM, which processes massive amounts of performance metrics for monitoring applications and servers. Clearly, in a performance monitoring system you primarily care about current performance numbers. Thus, if SPM’s Kafka pipeline were to break and we restore it, what we’d really like to avoid is processing all data sequentially, oldest to newest. What we’d prefer is processing new metrics data first and then processing older data using any spare capacity we have in order to “fill the gap” caused by Kafka downtime.
Here’s a very quick “video” that show this in action:
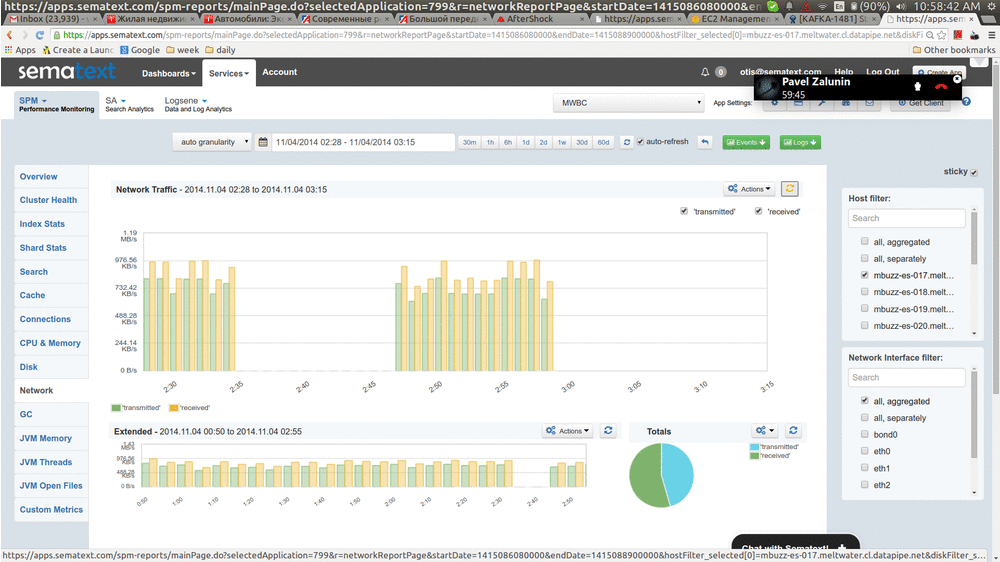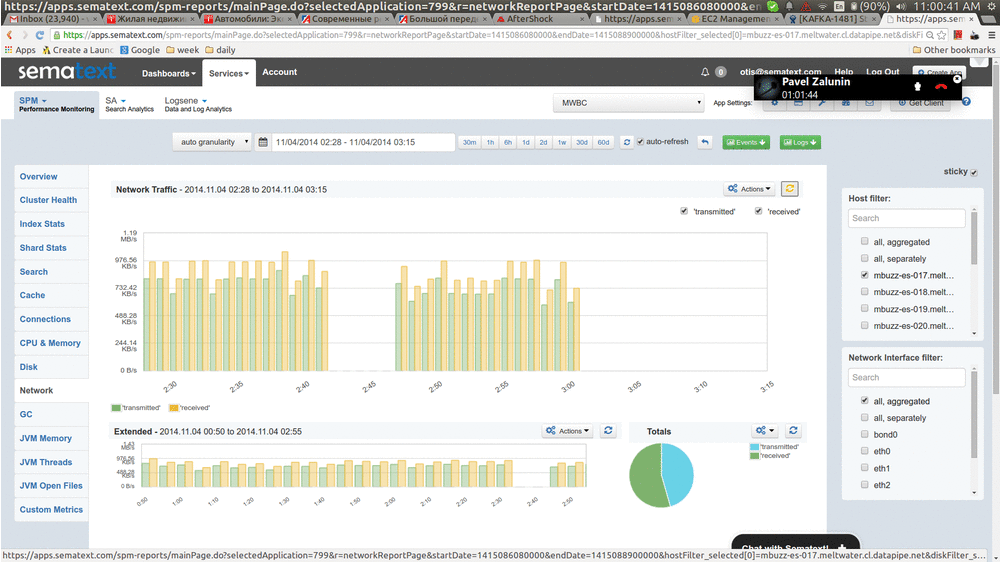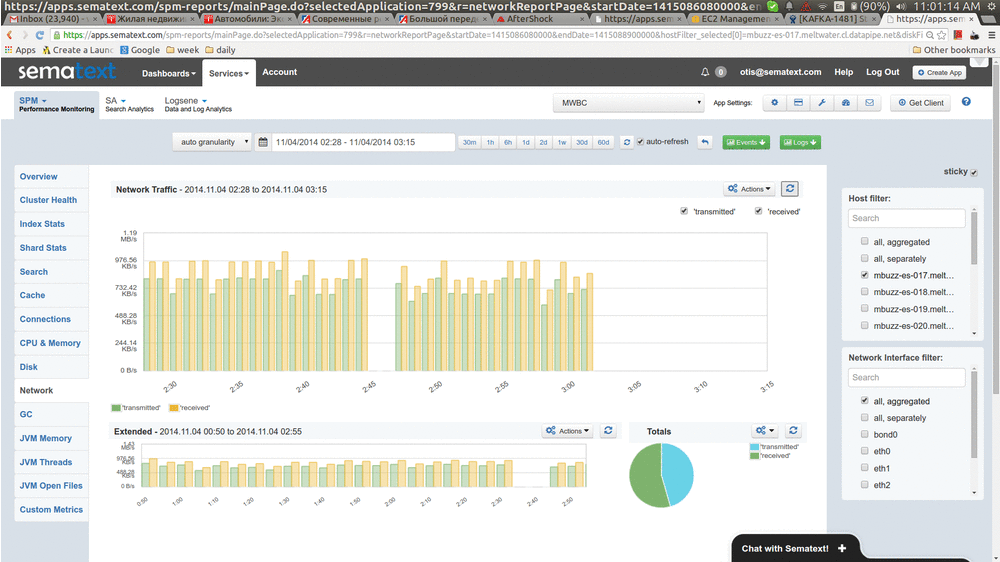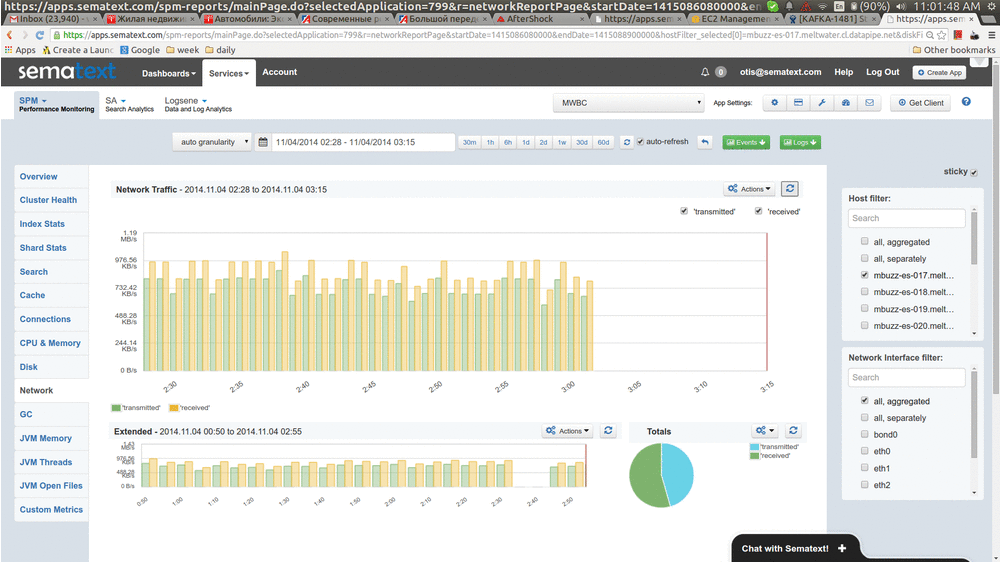
How does this work?
We asked about it back in 2013, but didn’t really get good tips. Shortly after that we implemented the following logic that’s been working well for us, as you can see in the animation above.
The catch up logic assumes having multiple topics to consume from and one of these topics being the “active” topic to which producer is publishing messages. Consumer sets which topic is active, although Producer can also set it if it has not already been set. The active topic is set in ZooKeeper.
Consumer looks at the lag by looking at the timestamp that Producer adds to each message published to Kafka. If the lag is over N minutes then Consumer starts paying attention to the offset. If the offset starts getting smaller and keeps getting smaller M times in a row, then Consumer knows we are able to keep up (i.e. the offset is not getting bigger) and sets another topic as active. This signals to Producer to switch publishing to this new topic, while Consumer keeps consuming from all topics.
As the result, Consumer is able to consume both new data and the delayed/old data and avoid not having fresh data while we are in catch-up mode busy processing the backlog. Consuming from one topic is what causes new data to be processed (this corresponds to the right-most part of the chart above “moving forward”), and consuming from the other topic is where we get data for filling in the gap.
If you run Kafka and want a good monitoring tool for Kafka, check out SPM for Kafka monitoring.