
In this presentation from Lucene/Solr Revolution 2015, Sematext engineers — and Solr and centralized logging experts — Radu Gheorghe and Rafal Kuć talk about searching and analyzing time-based data at scale.
Documents ranging from blog posts and social media to application logs and metrics generated by smartwatches and other “smart” things share a similar pattern: timestamps among their fields, rarely changeable, and deletion when they become obsolete. Because this kind of data is so large it often causes scaling and performance challenges.
In this talk, Radu and Rafal focus on these challenges, including: properly designing collections architecture, indexing data fast and without documents waiting in queues for processing, being able to run queries that include time-based sorting and faceting on enormous amounts of indexed data (without killing Solr!), and many more.
Here is the video:
…and here are the slides:
[slideshare id=54028436&doc=lucenerevolution2015-2-151016143435-lva1-app6891]
Here’s a Taste of What You’ll See
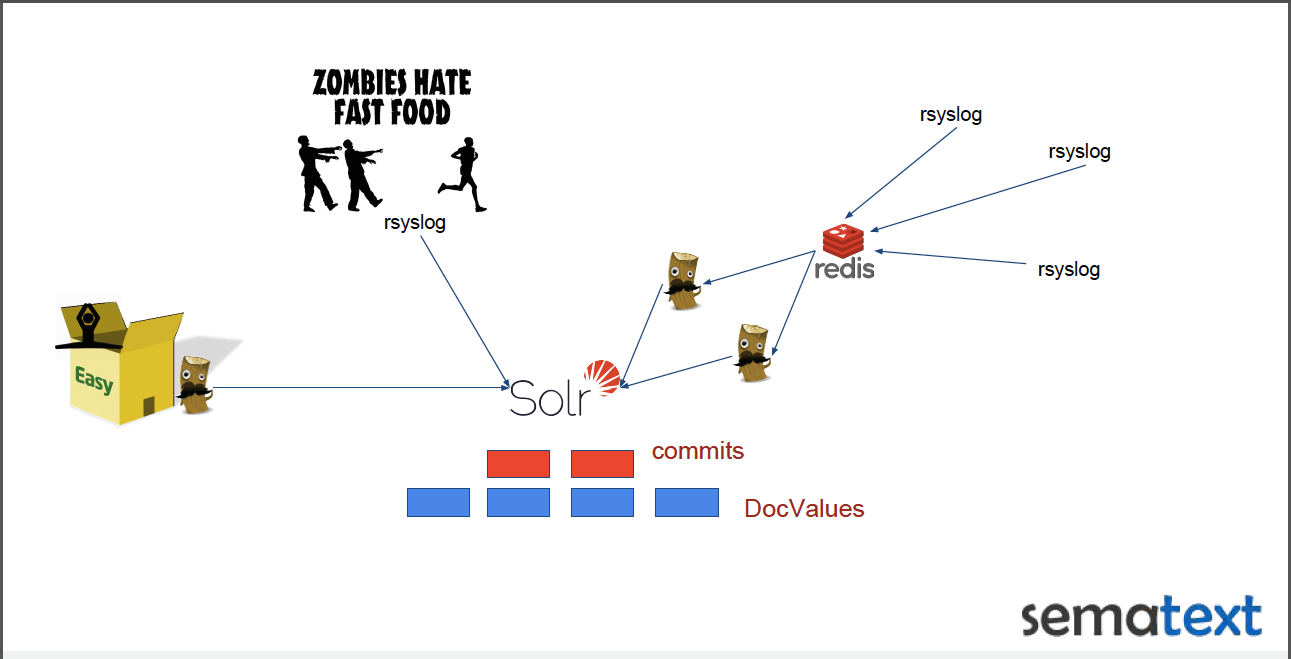
How do Logstash, rsyslog, Redis, and fast-food-hating zombies (?!) relate? You’ll have to check out the presentation to find out…
Solr “One-stop Shop”
Sematext is your “one-stop shop” for all things Solr: Expert Consulting, Production Support, Solr Training, and Solr Monitoring with SPM.
Log Analytics – We Can Help
If your log analysis and management leave something to be desired, then we’ve got you covered there as well. There’s our centralized logging solution, Logsene. And we also offer Logging Consulting should you require more in-depth support.
Questions or Feedback?
If you have any questions or feedback for us, please contact us by email or hit us on Twitter. We love talking Solr — and logs!