
This recipe shows how to send CloudTrail logs (which are .gz logs that AWS puts in a certain S3 bucket) to a Logsene application, but should apply to any kinds of logs that you put into S3. We’ll use AWS Lambda for this, but you don’t have to write the code. We’ve got that covered.
The main steps are:
0. Have some logs in an AWS S3 bucket 🙂
1. Create a new AWS Lambda function
2. Paste the code from this repository and fill in your Logsene Application Token
3. Point the function to your S3 bucket and give it permissions
4. Decide on the maximum memory to allocate for the function and the timeout for its execution
5. Explore your logs in Logsene 🙂
Create a new AWS Lambda function
To start, log in to your AWS Console, then go to Services -> Lambda:
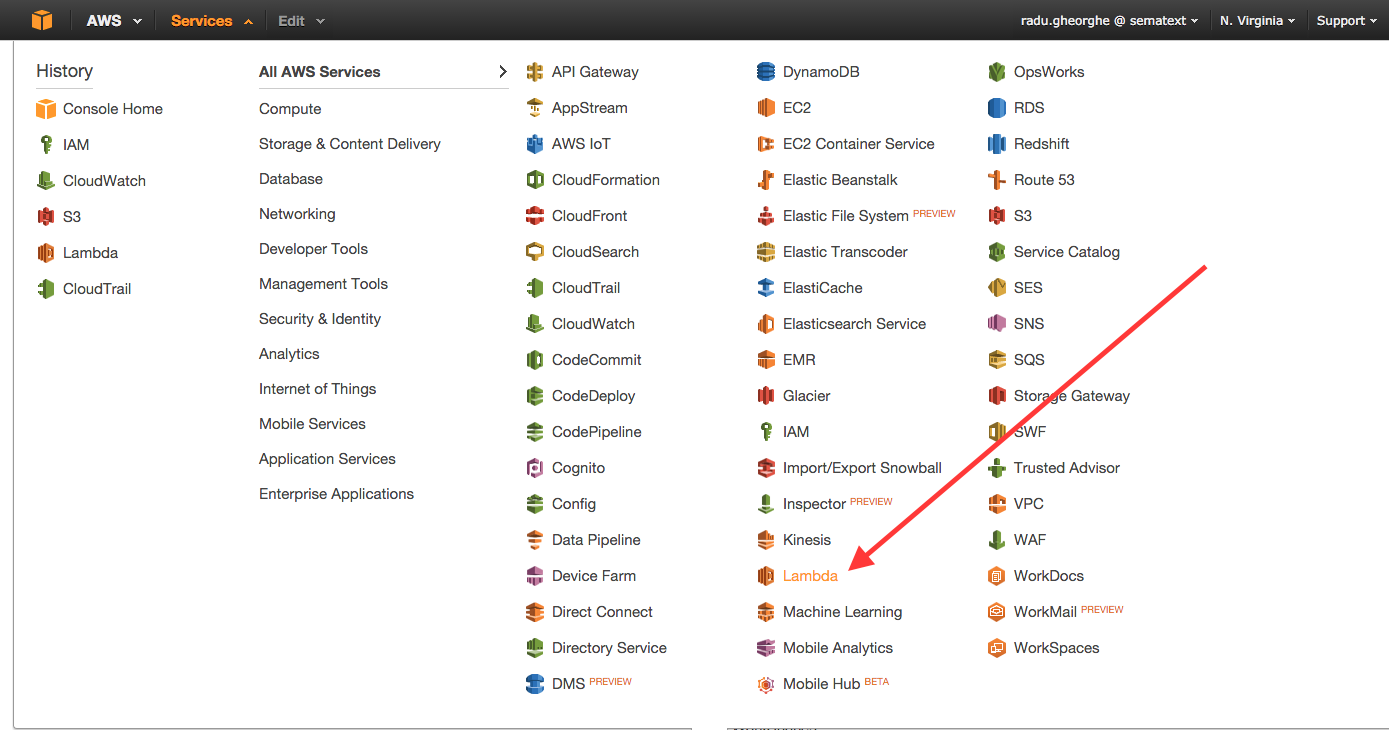
From there you’d start creating a function. If you don’t have another function, you’d just click on Get Started Now and it gets you there.

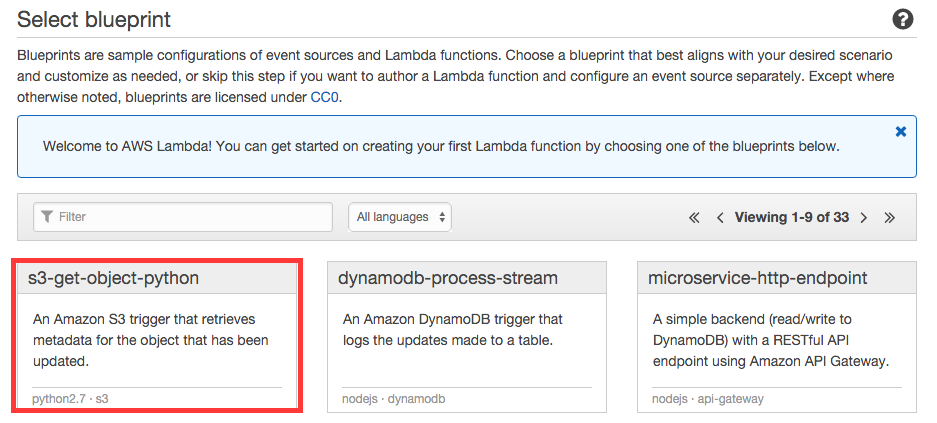
Then the first step is to select a blueprint for your function. Take s3-get-object-python.
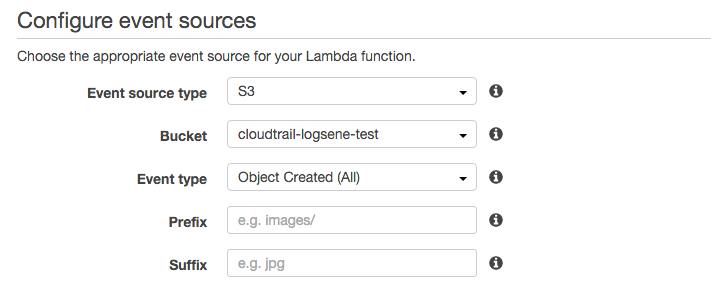
The next step is to select a source. Here you’d make sure the source type is S3, select the bucket to fetch logs from and pick Object Created (All) as the event type. This will make the function run whenever a new object is created in that bucket.
Paste the code and provide your token
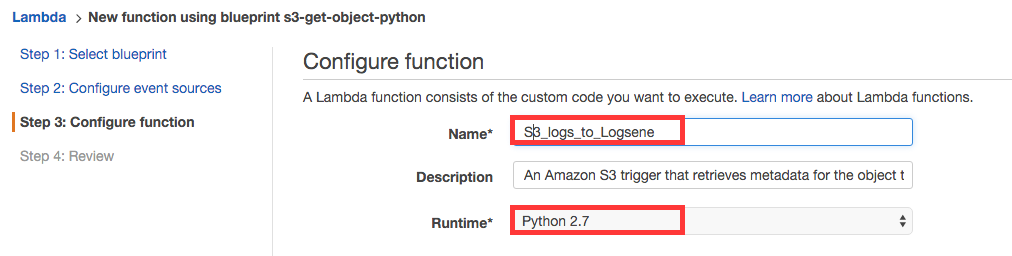
The main step is to provide the details of your function. You’d give it a name and leave the runtime as Python 2.7:
Then paste the whole contents of s3_to_logsene.py and use it to replace all existing function code. Also replace the dummy token with the Application Token of the Logsene application you want to use:
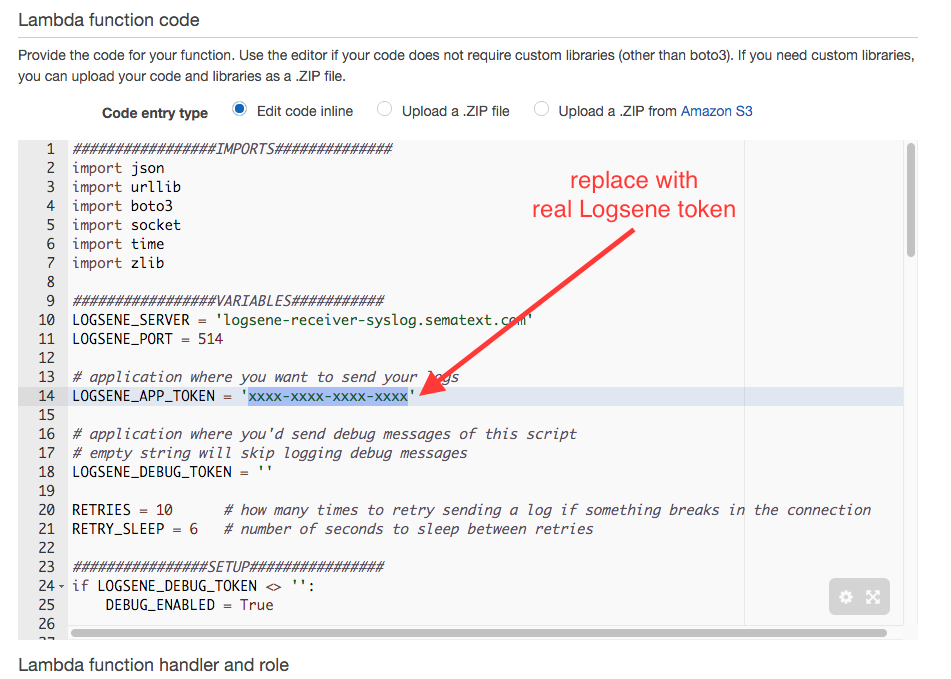
To find the Logsene Application Token, go to your Sematext Account, then in the Services menu select Logsene, and then the Logsene application you want to send your logs to. Once you’re in that application, click the Integration button and you’ll see the application token.

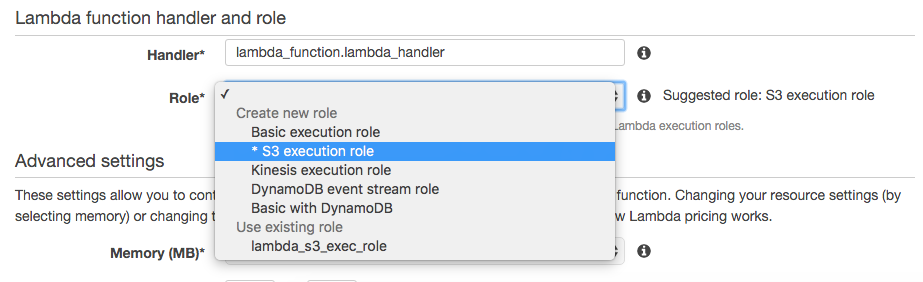
Give the function permissions
After the code, leave the handler to the default lambda_function.lambda_handler and select a role that allows this function to access the S3 bucket in order to fetch logs. If you don’t have one already, select S3 execution role from the dropdown, and you’ll be redirected to the IAM window, where you can accept the provided values and return.
Memory and timeout, then “go”
Finally, you need to decide on how much memory you allow for the function and how long you allow it to run. This will influence costs (i.e. like keeping the equivalent general-purpose instance up for that time). Normally, runtime is very short (sub-second) so even large resources shouldn’t generate significant costs.
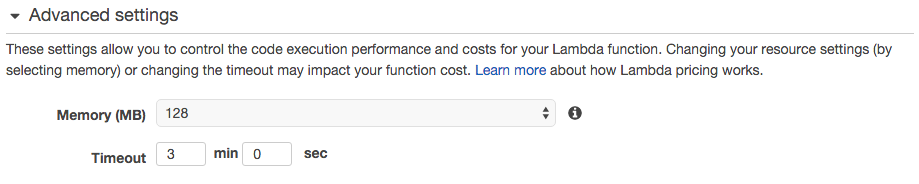
The default 128MB of RAM should be enough to load typical CloudTrail logs, which are small. You’d need more memory if you upload larger logs. As for timeout, selecting 4-5 minutes should be enough to give some resiliency in case of a network issue (i.e. allow the function to retry – which can be configured in the function code).
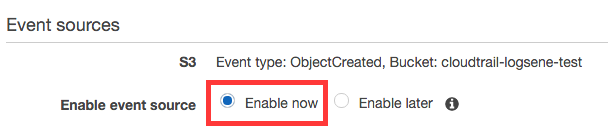
To enable the function to run when a new object is put, you’d need to enable the source at the last step.
Exploring CloudTrail logs with Logsene
As logs get uploaded to the S3 bucket, the function should upload their contents to Logsene. You can use the native UI to explore those logs:
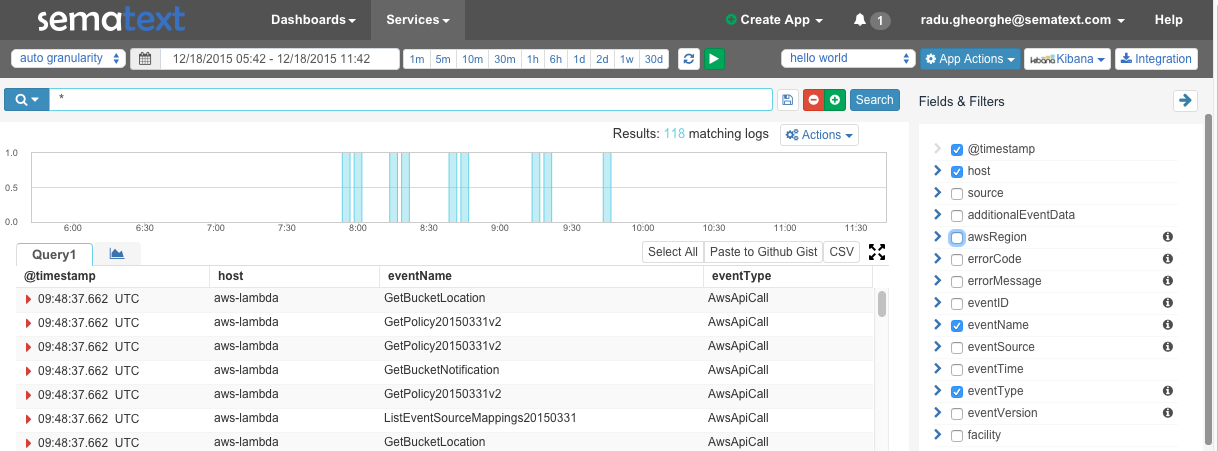
And because CloudTrail logs get parsed out of the box, you can also use Kibana 4 to generate visualizations. Like breaking down events by their type:
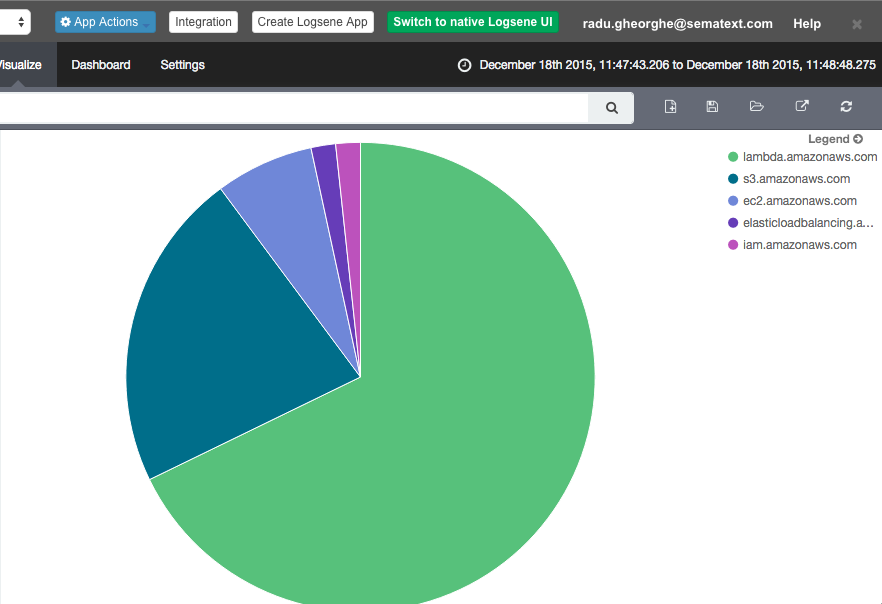
Happy Logsene-ing!