
With the recent release of Solr 6.0, we got a host of new functionalities users have been anxiously waiting for. We’ve got the Parallel SQL over MapReduce that we recently blogged about, the new default similarity model, changes to the default similarity model configuration, the graph query and the cross-data center replication. We will slowly discuss all of the features of new Solr version, but today we will look at the cross-data center replication functionality, how it works, how to set it up and what to keep in mind when using it.
Starting with cross data center replication
The cross-data center replication uses a specialized transaction log. When using the standard replication in SolrCloud, Solr stores up to 100 entries in transaction log and uses that information to synchronize replicas with the leader. If the replicas are too far behind the leader (i.e., the transaction log is not enough to synchronize) then the full replication of the changed segments is performed. This is different from how cross-data center replication works. In cross-data center replication the modified version of the update log stores an unlimited number of entries and uses that information to synchronize the source collection which we index data to, with the target collection that works as a copy of the source. The idea behind the logic is that the so called replicator configured in the source collection periodically reads the data from the update log and sends the updates in batches to target collection(s).
The data flow is as follows:
- Shard leader in the source collection receives an indexing command
- The indexing command is processed and indexed
- Data is replicated to local cluster replicas using standard SolrCloud replication
- If the indexing was successful, the indexing command entries are written to the update log
- The update log entries are persisted to the disk
- If step 5) was successful, the replicator mechanism checks the update log
- If new entries are found a batch is created
- The batch is sent to the appropriate target collection
- Data are received by the target collection leaders and are replicated to replicas using standard SolrCloud replication
This is the basic data flow when using the cross-data center replication. Keep in mind that the operations in points 1 – 5 are synchronous and the ones in 6 – 9 are done asynchronously by using a separate background thread. This is done to enable batching and optimize the way updates are sent through the network to ensure maximum scalability.
New in Solr 6: Cross-Data Center Replication – https://t.co/mo4tRvfgxk #solrcloud #solr #solr6
— Sematext Group, Inc. (@sematext) April 20, 2016
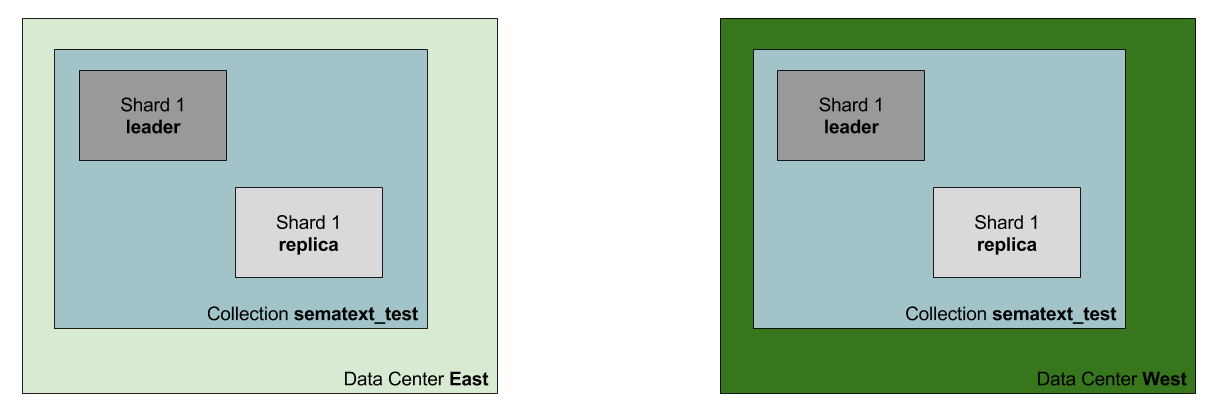
Our collection layout
For the purpose of the this post, we decided to set up a cross-data center replication between two data centers. The source one, to which we will index data is called East and the target one which will receive data using replication is called West. Each data center will have a single SolrCloud cluster with dedicated ZooKeeper ensemble, so that each cluster is not dependent on the other.
Each cluster will also have a single collection called sematext_test comprised of one leader shard and one replica:
Setting up source collection
The source collection, is the one that will be used as the source of truth for the replication data. The data from that collection will be replicated to target collections that are located in other data centers. To make things work we need to do two things:
- include a special /cdcr handler in the solrconfig.xml file
- modify the updateHandler configuration to use a modified version of the update log
The modified parts of the solrconfig.xml file for the source collection should look like this:
<requestHandler name="/cdcr" class="solr.CdcrRequestHandler">
<lst name="replica">
<str name="zkHost">10.1.2.1:7983</str>
<str name="source">sematext_test</str>
<str name="target">sematext_test</str>
</lst>
<lst name="replicator">
<str name="threadPoolSize">1</str>
<str name="schedule">1000</str>
<str name="batchSize">128</str>
</lst>
<lst name="updateLogSynchronizer">
<str name="schedule">60000</str>
</lst>
</requestHandler>
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog class="solr.CdcrUpdateLog">
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
</updateHandler>
First, we have the /cdcr handler configuration. We start by including the replica section, which points our source collection to the target one. Yes, our source collection will push the data to the target collection. We need to provide three things:
- zkHost – the address of ZooKeeper instance of the target collection. This is important. This is not the local cluster ZooKeeper, but the target one. So we need to ensure that the source SolrCloud instance is able to connect to the target SolrCloud cluster and its ZooKeeper ensemble
- source – the name of the source collection
- target – the name of the target collection
The second section provides the configuration for the replicator functionality. This functionality is responsible for monitoring cross-data center replication update log (every schedule milliseconds), create batches (with batchSize number of entries) and send them. It is suggested to use one thread per replica (controlled by threadPoolSize property).
The third section of the /cdcr handler configuration is the update log synchronizer, which is configured by a single schedule (specified in milliseconds) property. This configuration section controls how often non-leader nodes need to synchronize their update log entries with their leaders to clean up the entries that should be removed.
Keep in mind that the only required part of the /cdcr handler configuration is the replicator part with its configuration properties. All the rest of the /cdcr handler configuration can be omitted.
Finally, we have the modification of the default updateHandler section. What we need to do is configure the updateLog entry with the class=”solr.CdcrUpdateLog” section. This is crucial, because the default update log configuration stores 100 entries, because this is what is needed to synchronize replicas in SolrCloud. In cross-data center replication situation we need an infinite update log and because of that we need to change the implementation.
Setting up target collection
The second step of preparation for the cross-data center replication is configuring the target collection. What we need to do is:
- disable cross-data center replication buffering
- modify the /update handler and provide new default update chain
- define the new update chain
- modify the updateHandler in the same way as in the source collection.
The modified section of the solrconfig.xml looks as follows:
<requestHandler name="/cdcr" class="solr.CdcrRequestHandler">
<lst name="buffer">
<str name="defaultState">disabled</str>
</lst>
</requestHandler>
<updateRequestProcessorChain name="cdcr-proc-chain">
<processor class="solr.CdcrUpdateProcessorFactory"/>
<processor class="solr.RunUpdateProcessorFactory"/>
</updateRequestProcessorChain>
<requestHandler name="/update" class="solr.UpdateRequestHandler">
<lst name="defaults">
<str name="update.chain">cdcr-proc-chain</str>
</lst>
</requestHandler>
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog class="solr.CdcrUpdateLog">
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
</updateHandler>
First we have the /cdcr handler configuration. It is very simple – we just need to disable the buffering functionality. We do that because we only need to buffer update log entries infinitely on the source collection, not on the target ones. That’s why we include the above configuration.
We also need to provide a modified update request processor chain that includes the solr.CdcrUpdateProcessorFactory processor before the solr.RunUpdateProcessorFactory. This is needed for cross-data center replication to work on the target collection. We called our modified update request processor chain cdcr-proc-chain. We include that chain in our /update handler configuration using the defaults section and the update.chain property.
Finally, the same modification needs to be done to the default updateHandler section. The modification is exactly the same as the one in the source collection, so let’s not go over that for the second time.
Starting replication on empty collections
Let’s see how to start the cross-data center replication when you have empty collections, ones that you are just about to create. This is simpler than starting the cross-data center replication when you already have data. That’s because the replication mechanism relies on information stored in the update log and it won’t replicate the whole collections automatically by doing binary segments copy, just like the standard replication.
The following steps should be taken to start the cross-data center replication on source and target collections:
- Start ZooKeeper ensemble on the target cluster
- Start the target SolrCloud cluster
- Import configuration files to ZooKeeper for the target cluster (should contain cross data center replication handler already configured)
- Create collection on the target SolrCloud cluster
- Start ZooKeeper ensemble on the source cluster
- Start the source SolrCloud cluster
- Import configuration files to ZooKeeper for the source cluster (should contain cross data center replication handler already configured)
- Create collection on the source SolrCloud cluster
- Start cross data center replication by running the START command on the source data center
- Disable buffer by running the DISABLEBUFFER command on the target data center
After doing the above, the replication should be setup and working, so we can start indexing the data.
Starting replication of collection that has data
A slightly different approach to the one presented above should be taken when the data is already there and we need to setup cross-data center replication. We need to schedule a maintenance window and do a few steps before the ones that were mentioned above. The steps for the operation are as follows:
- Stop any indexing to SolrCloud
- Stop SolrCloud in the source data center and in the target data center
- Upload modified configuration to ZooKeeper in the source data center
- Upload modified configuration to ZooKeeper in the target data center
- Copy the data directories from source to the target, for example the leader shard data from the source data center in our case should be copied to leader shard in the target data center
- Start SolrCloud in the target data center
- Start SolrCloud in the source data center
- Start cross-data center replication by running the START command on the source data center
- Disable buffer by running the DISABLEBUFFER command on the target data center
After doing the above, the replication should be set up and working and we can enable indexing again. As you can see, the operation requires more manual work and this is one of the issues when setting up cross-data center replication in existing SolrCloud clusters at the moment. The good thing is that we only need to do this once and we are good.
Doing a simple test
To do a simple test of whether the cross-data center replication works, we’ll index two documents to our source data center and Solr running there. To do that we will run the following command:
curl -XPOST -H 'Content-Type: application/json' 'http://10.1.1.1:8983/solr/sematext_test/update' --data-binary '{
"add" : {
"doc" : {
"id" : "1",
"text_ws" : "First test document"
}
},
"add" : {
"doc" : {
"id" : "2",
"text_ws" : "Second test document"
}
},
"commit" : {}
}'
Keep in mind that we don’t have any automatic commits specified in the solrconfig.xml file (neither soft or hard), so we need to take care of the commits ourselves as we did in the above command.
Next, we can test if we have any data in our source collection by running the following command:
curl -XGET '10.1.1.1:8983/solr/sematext_test/select?q=*:*&indent=true'
The response from Solr is our two documents that we recently indexed:
<?xml version="1.0" encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<bool name="zkConnected">true</bool>
<int name="status">0</int>
<int name="QTime">2</int>
<lst name="params">
<str name="q">*:*</str>
<str name="indent">true</str>
</lst>
</lst>
<result name="response" numFound="2" start="0">
<doc>
<str name="id">1</str>
<str name="text_ws">First test document</str>
<long name="_version_">1531242066424627200</long></doc>
<doc>
<str name="id">2</str>
<str name="text_ws">Second test document</str>
<long name="_version_">1531242066472861696</long></doc>
</result>
</response>
Next, let’s check if the data has been replicated properly to the target collection in another data center. To do that we need to first run the commit command and then run the query:
curl -XPOST -H 'Content-Type: application/json' 'http://10.1.2.1:8983/solr/sematext_test/update' --data-binary '{
"commit" : {}
}'
curl -XGET '10.1.2.1:8983/solr/sematext_test/select?q=*:*&indent=true'
The response should be identical to the one returned by the source collection and look like this:
<?xml version="1.0" encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<bool name="zkConnected">true</bool>
<int name="status">0</int>
<int name="QTime">0</int>
<lst name="params">
<str name="q">*:*</str>
<str name="indent">true</str>
</lst>
</lst>
<result name="response" numFound="2" start="0">
<doc>
<str name="id">1</str>
<str name="text_ws">First test document</str>
<long name="_version_">1531242066424627200</long></doc>
<doc>
<str name="id">2</str>
<str name="text_ws">Second test document</str>
<long name="_version_">1531242066472861696</long></doc>
</result>
</response>
As you can see, everything works as it should. Perfect 🙂 Our replication process can be visualized as follows:
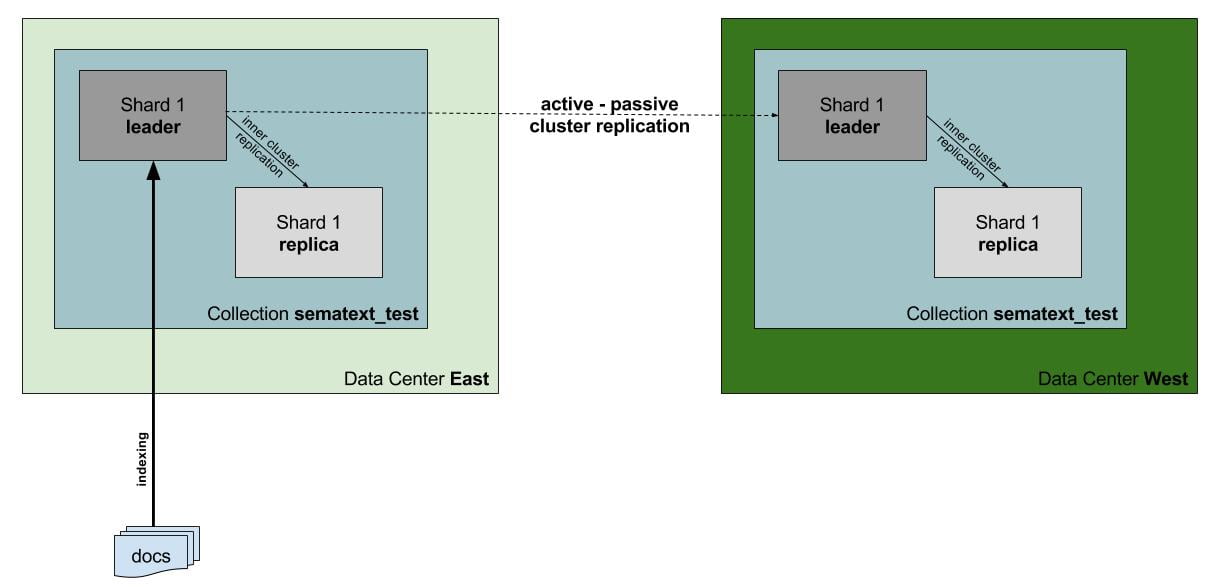
When the update command is received by the leader shard in the source collection it is processed, indexed and written to the update log. Then, the replicator sends the data to the appropriate leader in the target collection and again it is processed and indexed. This is done for all the leaders in the source collection (in our case we had just one).
Limitations
Last but not least, there are limitations to the cross-data center replication feature in SolrCloud. First of all, the current state of the cross-data center replication uses an active – passive approach. This basically means that there is only one source collection and it can’t be changed dynamically. So when our source collection fails or the data center in which the source collection is hosted is not available, we won’t be able to index data. Of course, we will still be able to search through the data, so no issues there. Keep in mind there there is work planned to overcome this limitation in the future releases of Solr 6.x, so something to look for if you are interested in cross-data center replication.
The second limitation is related to the connectivity between data centers. When having a large number of indexing operations we are limited by bandwidth between data centers. If we index enough data to exhaust the network, our target data centers and collections in them will fall behind. This is a physical limitation and something we have to deal with, because we need to transfer the data one way or another.
API
Finally, the last thing about the cross-data center replication is that similarly to the standard replication handler, the cross-data center replication handler supports an API that we can divide into two categories – control and monitoring.
When it comes to monitoring, the cross-data center replication handler API lets us:
- retrieve statistics about the queue for each target and the update log (core_name/cdcr?action=QUEUES)
- retrieve statistics about the operations per second for each replica, which basically means performance of the cross-data center replication (core_name/cdcr?action=OPS)
- retrieve information about errors on cross-data replication mechanism (core_name/cdcr?action=ERRORS)
- retrieve the status of the functionality (collection_name/cdcr?action=STATUS)
When it comes to control over the cross-data center replication we are allowed to control the following using the API:
- start cross-data center replication (collection_name/cdcr?action=START)
- stop cross-data center replication (collection_name/cdcr?action=STOP)
- enable buffering (collection_name/cdcr?action=ENABLEBUFFER)
- disable buffering (collection_name/cdcr?action=DISABLEBUFFER)
Summary
As you can see, with the release of Solr 6 we’ve got a viable solution to cross-data center replication when using SolrCloud. Of course, it has its limitations and we need to be aware of them, designing our software with them in mind. The good thing is that we now have the ability to have the data available in multiple data centers at near real time and can avoid being negatively impacted by issues affecting even the whole data center.
For the configuration of the source and target collection that we’ve used when writing this post, please go to the following Dropbox links:
- source collection configuration – https://www.dropbox.com/sh/xiyx47fa7amri0f/AAAUCAORMTBT202ZYjSM1J9pa?dl=0
- target collection configuration – https://www.dropbox.com/sh/32ttjbl5s729nwl/AABxvLdaqxr6kWixRHPZ2mgqa?dl=0