
With the release of Solr 7 the community around it produced yet another great version of this search engine. As usual, there is an extensive list of changes, bug fixes and improvements that were introduced in version 7. Just to mention a few of the changes like deprecation of Trie field types and introduction of Point types which are faster and use less memory, API to define cluster balancing rules for SolrCloud, JSON as the default response format and new replica types. These are just a few goodies from Solr 7. You can learn more about Solr 7.x features in our Solr classes. What we will focus on in this blog post is another great, new feature – new replica types.
Replication in Solr 6.x and Older
Until Solr 7 we really didn’t have much choice around replication. There were really only two options: either use near real time replication in SolrCloud and control the impact of commits by using auto commits, or simply use the legacy master – slave architecture with all its pros and cons. There are multiple problems with the replication approach taken by SolrCloud until Solr 7 – each replica, no matter the type, could become a leader. Don’t get me wrong, this is very good from high availability and fault tolerance perspective – the more shards we have, the more resilient our SolrCloud cluster is. However, that comes with a price. Leader shards and their replicas need to be in sync at all times. So all updates must be routed to all shards.
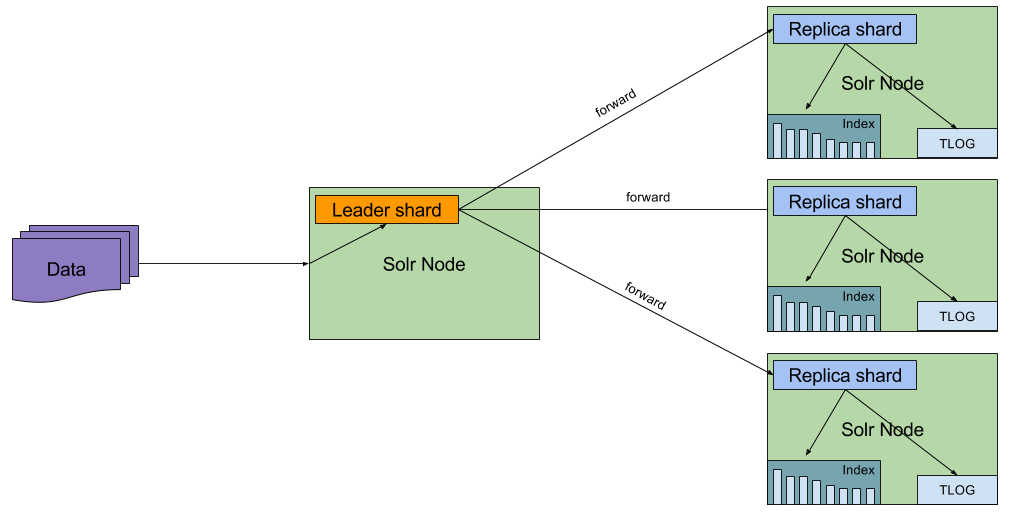
Also, remember that not only was data forwarded to each replica and put into the transaction log, but each replica was also indexing the same data as the leader shard. That meant that each replica would potentially do the same analysis process, same writing data to the segment, same segment merge, etc. That feels expensive and redundant, doesn’t it?
This is one of the reasons why many of our Solr consultancy clients often hesitate to switch from the legacy master – slave architecture to SolrCloud. In some cases, especially those involving very heavy reads, SolrCloud was not as efficient as master – slave. Imagine you indexed a few documents every second or even every minute. What SolrCloud would do is distribute the documents to all the relevant shards, each shard would potentially do some segment merging, caches may have been invalidated, and so on. All that negative impacts query performance. What if we could copy binary segment files, like in Solr master – slave architecture, but inside SolrCloud?
Introducing Solr 7 Replica Types
Solr 7 in its SolrCloud mode supports a wider spectrum of use cases in a more performant way by introducing new ways of synchronizing data between leaders and their replicas. Those of us who will start using Solr 7 now will have new options:
- NRT replicas, the default behavior which we just described – the old way of handling replication in SolrCloud.
- TLOG replicas, which uses the transaction log and binary replication.
- PULL replicas, which only replicates from leader and uses binary replication.
Let’s skip NRT replicas, as this is the old replication behaviour, and focus on new SolrCloud replication types – TLOG and PULL.
TLOG Replicas in Solr 7
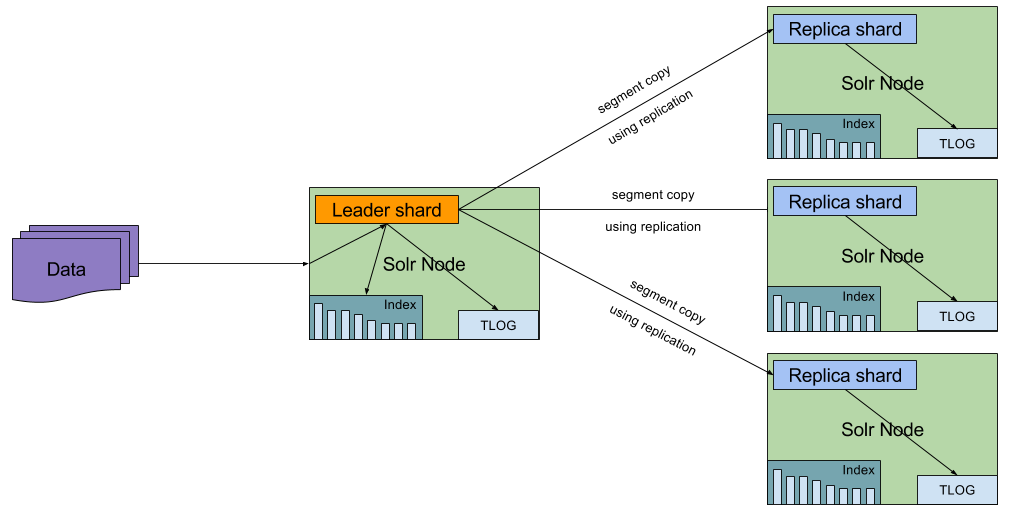
The TLOG replicas or, as we can call it, transaction log based replicas, are different. Instead of indexing data just like the leader, they only write data to transaction log and copy the binary segments using the replication handler. That means that we save our replicas the need to index data. This saves CPU cycles. What’s more though is that we also eliminate the need to flushing data to disk, which means that avoid segment merges, which can be potentially very, very expensive, (more about this in my recent Lucene Solr Revolution talk – Optimize is (Not) Bad For You). In general, the TLOG replica type helps us speed up indexing because Solr doesn’t need to index the same data on each replica. Instead, it just copies the already indexed data – the segments – and simply reopens an index searcher on that data.
When it comes to leaders and leader election, the TLOG replica type shards can become leaders and participate in leader election. That means that when something happens to our leader shard the TLOG replicas can take its role without any data loss by replaying the contents of the transaction log over the copied segment. When the TLOG replica becomes a leader it will behave just like the NRT replica type, so it will write data both to the transaction log and to the inverted index itself for near real time indexing and searching. That is true until it again becomes a replica again which makes it follow the transaction log replication rules.
So far we’ve covered only the pros of the TLOG replica type, but there are also downsides. Because TLOG replicas do not index data and use binary replication of segments they are not as near real time as NRT replication. That basically means that between indexing the data on the leader shard and having it available and visible on TLOG replica there will be some delay. How much delay? Let’s have a look at some relevant Solr logs:
2017-10-09 12:10:42.252 INFO (qtp581374081-16) [c:blog s:shard1 r:core_node1 x:blog_shard1_replica_t1] o.a.s.c.S.Request [blog_shard1_replica_t1] webapp=/solr path=/replication params={qt=/replication&wt=javabin&version=2&command=indexversion} status=0 QTime=0 2017-10-09 12:10:42.253 INFO (indexFetcher-25-thread-1) [c:blog s:shard1 r:core_node2 x:blog_shard1_replica_t2] o.a.s.h.IndexFetcher Master's generation: 1 2017-10-09 12:10:42.253 INFO (indexFetcher-25-thread-1) [c:blog s:shard1 r:core_node2 x:blog_shard1_replica_t2] o.a.s.h.IndexFetcher Master's version: 0 2017-10-09 12:10:42.253 INFO (indexFetcher-25-thread-1) [c:blog s:shard1 r:core_node2 x:blog_shard1_replica_t2] o.a.s.h.IndexFetcher Slave's generation: 1 2017-10-09 12:10:42.253 INFO (indexFetcher-25-thread-1) [c:blog s:shard1 r:core_node2 x:blog_shard1_replica_t2] o.a.s.h.IndexFetcher Slave's version: 0 2017-10-09 12:10:49.251 INFO (qtp581374081-56) [c:blog s:shard1 r:core_node1 x:blog_shard1_replica_t1] o.a.s.c.S.Request [blog_shard1_replica_t1] webapp=/solr path=/replication params={qt=/replication&wt=javabin&version=2&command=indexversion} status=0 QTime=0 2017-10-09 12:10:49.252 INFO (indexFetcher-25-thread-1) [c:blog s:shard1 r:core_node2 x:blog_shard1_replica_t2] o.a.s.h.IndexFetcher Master's generation: 1 2017-10-09 12:10:49.252 INFO (indexFetcher-25-thread-1) [c:blog s:shard1 r:core_node2 x:blog_shard1_replica_t2] o.a.s.h.IndexFetcher Master's version: 0 2017-10-09 12:10:49.252 INFO (indexFetcher-25-thread-1) [c:blog s:shard1 r:core_node2 x:blog_shard1_replica_t2] o.a.s.h.IndexFetcher Slave's generation: 1 2017-10-09 12:10:49.252 INFO (indexFetcher-25-thread-1) [c:blog s:shard1 r:core_node2 x:blog_shard1_replica_t2] o.a.s.h.IndexFetcher Slave's version: 0
This is the actual replication taking place. We can see that Solr uses the notion of master and slave (not to be confused with master-slave architecture) and this is what actually happens – Solr tries to fetch data from the leader shard (master in the above log) and copy the binary segments to the TLOG replica type (slave in the above log). The poll time from replica to the master is set to half of the autoCommit property value or, if autoCommit is not defined, 50% of the autoSoftCommit. If both are not present it is set to 1500 milliseconds. For example, with the default configuration we will see polling every 7 seconds:
2017-10-09 12:42:22.204 INFO (recoveryExecutor-2-thread-1-processing-n:192.168.1.15:8983_solr x:blog_shard1_replica_t2 s:shard1 c:blog r:core_node2) [c:blog s:shard1 r:core_node2 x:blog_shard1_replica_t2] o.a.s.h.ReplicationHandler Poll scheduled at an interval of 7000ms
PULL Replicas in Solr 7
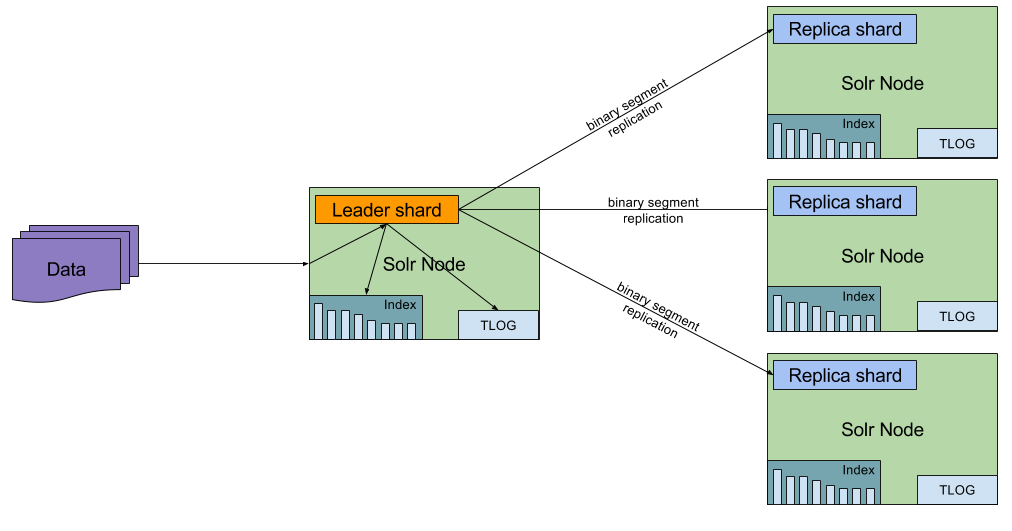
The second type of replication introduced in Solr 7 is the PULL type. This replica type doesn’t index data locally, doesn’t maintain the transaction log, and only pulls the data from the leader. This means that this replica type can’t become a leader when something happens to the leader shard.In other words, if we want fault tolerance we have to use NRT or TLOG replica types. However, this means that when performance is all that we care about the PULL replicas are for us. In other words, if you can live with replicas being unable to become a leader, and if you can tolerate the delay between data being indexed and it being searchable we get the best performance – similar to the master – slave, but we also have all the goodies that comes with SolrCloud, so the possibility of using Collections API, dynamically adding shards, and so on.
Using New Replica Types
The best thing about new replica types is that you are not limited to a single replica type when you create your collection. Yes, you read that well – you can use mixed replica types within a single collection. The Solr Collections API and its create action lets us use the following parameters:
- nrtReplicas
- tlogReplicas
- pullReplicas
All these parameters take numeric values that specify the number of replicas of a given type that should be created. For example, to create 6 physical shards – two of type NRT, two of type TLOG and two of type PULL, we’d run (keep in mind we had to add maxShardsPerNode here, because our example cluster was very minimalistic – it had a single node):
http://localhost:8983/solr/admin/collections?action=CREATE&name=blog&numShards=1&maxShardsPerNode=6&nrtReplicas=2&tlogReplicas=2&pullReplicas=2
We can also add replicas dynamically, on demand, by using the ADDREPLICA command:
http://localhost:8983/solr/admin/collections?action=ADDREPLICA&collection=blog&shard=shard1&node=192.168.1.15:8983_solr&type=tlog
As you can see, Solr 7 added a new parameter to the ADDREPLICA command – type. It can take one of the following values:
- nrt – use that value for near real time replicas, this is also the default value,
- tlog – use that value for transaction log based replicas,
- pull – use that value for pull replicas.
Need a Solr monitoring solution? Try Sematext cloud!
Monitor all key Solr metrics from Request Rate & Latency to Warmup time, and more. Plus, Sematext Cloud is the first monitoring AND log management solution in one.
Conclusion
To summarize, Solr 7 introduces two new and powerful replication types one can use when running SolrCloud. They reduce the CPU and disk IO of data replication, but make search a little less real-time. As we’ve shown, you can use multiple replication types at once, and you have the flexibility of choosing replication type on a per collection and even per replica basis. These new replica types let you scale your SolrCloud deployments even further and make better use of your infrastructure.
Want to know more? We cover this and a lot more in our Online Solr Classes.