
What Are Anomalies?
Anomalies mean outliers or inconsistent data points, which are values that stand out significantly in our dataset. This means that anomalies expect a baseline to be predefined, that is, an expected or established “norm.”
Anomalies can be destructive and describe issues, but not always. For example, a spike in the customer behavioral dataset could mean shifting customer demands or can be due to a very successful marketing campaign. However, these data points are always worth investigating as they help you better understand the landscape and prevent unseen events.
What Is Anomaly Detection?
Anomaly detection, or outlier analysis, is the data mining process of identifying data points that fall outside or deviate from the norm, established baseline, or expected pattern in a dataset. This detection process is vital because anomalies like these are often an indicator of unusual behavior, such as potential fraudulent attempts, security breaches, or cyber security intrusions.
Why Is Anomaly Detection Important?
Organizations leverage data mining techniques to detect anomalies and monitor data points—inputs and outputs—moving across their IT infrastructure and systems. Fundamentally, anomaly detection helps organizations address security leaks, avoid data exposure, and set alerts against unusual behavior that deviates from the established pattern. This is valuable when identifying critical incidents and potential opportunities.
However, as mentioned earlier, anomalies don’t always mean an issue. Thus, the importance of anomaly detection tends to differ within and between industries and use cases. Regardless they’re helpful when trying to identify, investigate and trace the root cause of spikes or outliers.
Let’s dive into some areas where anomaly detection comes in handy.
Network Behavior
Network behavior anomaly detection is sweeping your network’s packets, bandwidth, bytes, traffic volume, flow, and protocol for any suspicious activities that could be malicious or with the intent to compromise network operations. Detecting unusual network traffic, suspicious high-volume data transfers, or unexpected jumps within the “quiet” hours” is an essential part of today’s cybersecurity systems.
Network behavior anomaly detection takes on the chosen configuration of the organization and how sensitive the situation can be.
Application Performance
Today’s performance anomalies are the core of business problems because they can break your infrastructure’s operational performance and productivity. These problems can creep in and cause gradual performance problems such as server outages, degradation, and sudden CPU utilization spikes within your applications and infrastructures. Anomaly detection helps find these issues before they cause any significant outrage that can affect your end users.
Application performance anomaly detection aims to reduce three key incident metrics;
- The mean time to detect (MTTD) is when an anomaly occurs.
- The mean time to investigate (MTTI) is the cause of the issue.
- And the mean time to resolution (MTTR) is about how long it takes to resolve the issue.
These metrics provide context behind the application’s health and are helpful when trying to understand how to reduce unnecessary costs and inefficiencies.
[product_banner type=”infrastructure-monitoring”]Capture anomalies in your infrastructure and application performance and logs and get alerted in your favorite tools.[/product_banner]
Web Application Security
Web applications are used today in almost all aspects of our everyday life, especially with the rise of cloud technology. Thus, they’re one of the most attacked vendors and targets in various industries today. One common vulnerability is HTTP request-related vulnerabilities. Here attackers try to exploit the inconsistency in how frontend and backend servers process requests.
The anomaly-based detection system looks for anomaly behavior by analyzing web logs from web servers and defining users’ behaviors. Once a regular behavior pattern has been defined, anything that falls outside is tagged as intrusive. Using these anomaly detection systems, you can monitor web applications, and alerts can be issued whenever an attack attempt is found.
Security Breaches
Anomaly detection can also be used to identify potential security breaches or vulnerabilities within an organization’s systems and networks. By security breaches, we mean malware, insider threats, or social engineering tricks like phishing attacks. Anomaly detection techniques can help to detect and prevent these breaches by identifying unusual patterns of behaviour that may indicate an attack. For example, spikes in failed login attempts followed by a successful login and someone accessing or requesting data they have never used before.
The anomaly detection algorithms will be activated in response to this. In addition, the activity will be flagged as suspicious, and the security team will be alerted. It is crucial to understand that for the systems to identify the anomalies that are most crucial to the organization, they must be correctly configured and trained using historical data.
Product Quality
Creating a physical product goes beyond manufacturing and launching a product. Issues are bound to happen within various stages of the production pipeline. Anomaly detection can ensure quality across the product creation pipeline and help detect defects quickly. Manual quality assurance process involves traditional tests, which are easily prone to error. Anomaly detection techniques provide a less time-consuming, error-prone way to accurately identify and classify defective products without disrupting production. You can also employ these techniques to pinpoint pain points in the process.
Digital products are no different. Anomaly detection can be used to monitor a product lifecycle and ensure users have a great experience. By tracking various metrics within the product lifecycle, the team can make sense of any metrics and detect incidents like leaky funnels or any unexpected changes that warrant an investigation.
Types of Anomalies
Anomalous data are like breadcrumbs that help the team identify an issue’s root cause as fast as possible. However, before you can make the most of the insight generated, you need to understand the type of anomalies or outliers you’re handling.
Fundamentally speaking, there are three types of anomalies.
Global
Global anomalies, also known as point anomalies, are data point values far from the expected pattern of the dataset. For example, think of an unusually high transaction amount from a dataset of credit card transactions or a high spike in user activity that hasn’t been recorded before from a particular geographical area. This kind of anomaly is often a sign of fraudulent activity.
Contextual
Also known as conditional anomalies, are anomalies whose value appears anomalous in one context but doesn’t appear anomalous in another context. Here the value seems normal in the global range context but is anomalous in the seasonality context point of view. This is very common in time series data because values are recorded within a specific period. For example, a higher-than-normal spike in user activity might feel anomalous. But when you consider the promotional offer or discount your marketing team announced, this spike might not seem so anomalous anymore.
Collective
Collective anomalies are anomalous data points viewed as a set or in a collection. These data points appear normal when looked at globally, contextually, or individually within a specific time series. However, when combined with another time series dataset, their anomalous nature becomes more apparent—for example, seeing high traffic during hours outside the seasonal nature of your business.
Think of it all this way.
A sudden high number of new users onboard your application in a day is a global anomaly as you are yet to record this number of new users in your startup’s history. Now it is up to you to investigate whether this recent increase in users is due to your marketing effort or users trying to take advantage of your referral bonus.
A contextual would be seeing a sudden surge in email message patterns from users of your marketing automation and email marketing platform. If this happens outside your high volume and promotional periods like Black Friday and Christmas, it could signify phishing attempts from compromised accounts. Now collective anomalies would be getting orders all day. While this isn’t rare, it will be unusual to see this activity from everyone at all hours, odd hours included, and from customers who rarely make purchases all of a sudden all day long.
Types of Anomaly Detection Techniques
Anomaly detection processes revolve around various statistical and Machine Learning (ML) methodologies. Machine learning is a subset of artificial intelligence focused on feeding data to computer models so they can accurately predict the outcome by understanding and learning from the data. This learning can be supervised, semi-supervised, or unsupervised.
Organizations use these models and algorithms to refine their predictive capacity, enhance root cause analysis, and detect anomalies accurately. However, to do this accurately, you must pick a suitable ML model.
Supervised
Here, fully labeled training and test data sets are used to build and train ML models to classify data accurately or predict outcomes. First, the dataset’s attributes column is labeled as normal and anomalous. This is then used to define “normal” and detect abnormal patterns in unseen data.
This model works best with unbalanced classes and on the assumption that the anomalies are well-known and already labeled. Thus, it is hard to detect anomalies yet to be identified. Common supervised methods are Bayesian networks, decision trees, k-nearest neighbors, and SVMs.
Semi-Supervised
Unlike supervised ML models, semi-supervised models are trained on labeled and unlabeled datasets. This train-as-you-go approach has some benefits. First, it dramatically reduces expenses on manual annotation. Also, because it is trained on unlabelled data, predictions are much more accurate once the model learns what normal is and what deviates from it. A few common semi-supervised methods are co-training, Graph-Based semi-supervised learning, and Semi-Supervised Support Vector Machines.
Unsupervised
The unsupervised anomaly detection ML algorithm is trained on unlabeled data; thus, no manual labeling is required. It works on the assumption that only a tiny percentage of the available data is anomalous. Here models like GMMs, k-means, hypothesis tests-based analysis, and Gaussian mixture are used to detect and classify anomalous data.
Unsupervised anomaly detection is the most flexible regarding new unidentified datasets. Primarily, you built the model to identify anomalies based on characteristics rather than any predetermined normalcy values. However, while this model sounds great, because of its complexity, it is often tagged as a black box. It is also seen as less trustworthy because we don’t know how and why attributes are labeled anomalies.
Popular Machine Learning Anomaly Detection Methods
With the large volume of data, rapid change, and the complexity of today’s distributed cloud landscape, anomaly detection can be time-consuming and inaccurate if done manually. In addition, it will also mean manually defining what is normal for each application and constantly adjusting your baseline to meet the ever-changing needs of today’s environment. This is where automated anomaly detection systems come in. It is the only way to monitor various infrastructures and metrics at scale.
Automated anomaly detection adopts AL and ML techniques to get a holistic picture of what’s happening within the data. In addition, the process ensures real-time detection and alerting are error-free. Also, depending on the tool employed, the whole process can be done through an inbuilt, intuitive, easy-to-use graphical user interface (GUI) that easily integrates with existing workflow.
Let’s look at various ML anomaly detection methods and how they work.
Clustering-Based
Clustering-based uses cluster-based algorithms like the K-means algorithm to cluster data points and capture the anomalous data points. The “K” here means a cluster of similar data points. This ML model works on the assumption that normal data points cluster together and data points farther than the average distance within a cluster (local centroids) are anomalous. This average distance (baseline) is created using the training set. This baseline is then used to create new clusters and identify new anomalous data on new data. Anomalous data here tends to belong to tiny or no clusters. This model, however, doesn’t work well with time series data because it uses a fixed set of clusters.
Distance-Based
Distance-based anomaly detection takes account of the distance between data points in the dataset. Thus any data points that fall outside the defined radius of an object’s neighborhood or don’t match enough data points within a particular neighborhood are considered an anomaly. This distance is defined as the reasonable neighborhood of the object. One area for improvement with this model is that it is based on a single value of a custom parameter. Thus, there can be inaccurate output if the dataset has dense and sparse data point regions.
Density-Based
Density-based anomaly detection compares a data point value’s local density to its neighbors’ local densities at a given point. This helps the algorithm see how well a data point fits into the density of the locality. Thus anomalies data point appears far away and sparsely from the established reachability distance. ML algorithms like the k-nearest neighbor and local outlier factor (LOF) algorithm are some of the most popular density-based anomaly detection. K-nearest neighbor classifies data based on distance metrics like Euclidean, Hamming, Manhattan, or Minkowski distance, while LOF uses the relative density of data.
Classification-Based
Classification-based anomaly detection models are majorly dominated by supervised anomaly detection. Here, data points are labeled into normal and anomaly classes based on feature types predefined by the model. K-nearest neighbors algorithm (KNN) and support vector machine-based (SVM) are examples of classification-based anomaly detection models.
Support Vector Machine-Based
Support vector machine-based (SVM) anomaly detection is a supervised ML algorithm that uses hyperplanes in multi-dimensional space to divide data points into classes. Data points within those hyperplanes (boundary) are considered normal, while others are labeled anomalies. Its ability to create subplanes with distinct boundaries that divide the data points into these two groups significantly impacts its accuracy in detecting abnormalities. SVM can also be used on unlabelled data using SVM extensions.
Anomaly Detection Use Cases
Anomaly detection models are applied to tackle business problems like ensuring data protection, malware detection, or finding future business opportunities. While the use case might differ within industries, the end goal remains the same; identity, decrease response time to threats and trace the root cause of anomalies.
Let’s look at anomaly detection from the lens of various industries.
- Banking and financial: Financial transaction records capture the flow of monetary and non-monetary assets between parties. As a result, these records have specific patterns. Unfortunately, fraudulent activity tends to deviate from these patterns, and anomaly detection models are used to identify them. Fraudulent activities here range from high-risk invoices, duplicate payments, and know-your-customer (KYC) fraud to wire transfer, insurance, check, and credit card fraud. The models here are, however, real-time, time-sensitive, and high-risk, as false positives can disrupt the user experience, and delays can be costly for everyone.
- Health monitoring: Anomaly detection is used to enhance patient care by identifying anomalous data in patient care data, physiological variables, health reading, and medical image analysis. These data can help to make more accurate diagnostics and prevent potentially fatal errors in treatment plans. Accurate anomaly detection indirectly reduces manual work and cognitive load on health professionals while assisting them in taking action more swiftly. Like in the financial use case, these models are sensitive and high risk, as false positives can be just as detrimental to the patient.
- Cybersecurity and intrusion detection: Security is crucial for every business today. Anomaly detection is used to detect potential security threats across the organization’s network packet signatures and infrastructure. This helps block out malware, suspicious events, and unauthorized data transfer. These models also flag and alert against real-time anomalies in consumer spending or behavioral activities. The challenge here is the adaptive nature of the malicious behavior and the fact that you need to be more proactive against threats.
- Internet of Things (IoT): When applying anomaly detection to the Internet of Things (IoT), the end goal is to tackle how to protect this customer’s asset from being exploited. ML models use data generated from IoT devices to analyze behavioral patterns of users to identify anomalies from IoT threats at the network and data center level. Common IoT threats are man-in-the-middle attacks and Hide and seek (HNS).
- eCommerce: Anomaly detection is vital for eCommerce businesses to identify unusual patterns and behaviors. Integrating with eCommerce monitoring allows businesses to address issues and optimize operations proactively. Anomaly detection algorithms analyze customer behavior, detect spikes in website traffic, monitor transactions, and detect fraud. This leads to improved customer experience, efficient supply chain and inventory management, and reduced costs. In addition, by continuously using anomaly detection in eCommerce, product seasonality can be anticipated and better aligned to deliver a better online shopping experience for customers.
- SaaS: While SaaS applications have grown in popularity among businesses over time, it has become a target for attacks. The attacks are due to the data available on these applications, from intellectual property to personally identifiable information. Organizations can leverage anomaly detection models to combat these threats and identify malicious authentication events and behavior from application logs. These models allow the team to proactively act on time-sensitive issues and get notified about application irregularities.
Anomaly Detection Alerts with Sematext
Sematext Cloud is a full-stack monitoring solution that helps you get visibility into all components of your infrastructure. It comes with out-of-the-box dashboards that you can easily customize to fit your use case, and advanced alerting capabilities for logs, metrics and anomalies to notify you when values suddenly change and deviate from the norm.
The baseline for each point is calculated using the sliding window of previous N minutes, specified by time window. Sliding time window is configurable, giving you the ability to choose how aggressive the anomaly detection should be. Picking a wider sliding window will result in a less sensitive baseline and fewer alerts.
Creating anomaly alerts is simple with a few clicks. First, you pick the metric that you want to watch for sudden changes. And then, you pick the Anomaly alert as an Alert type.
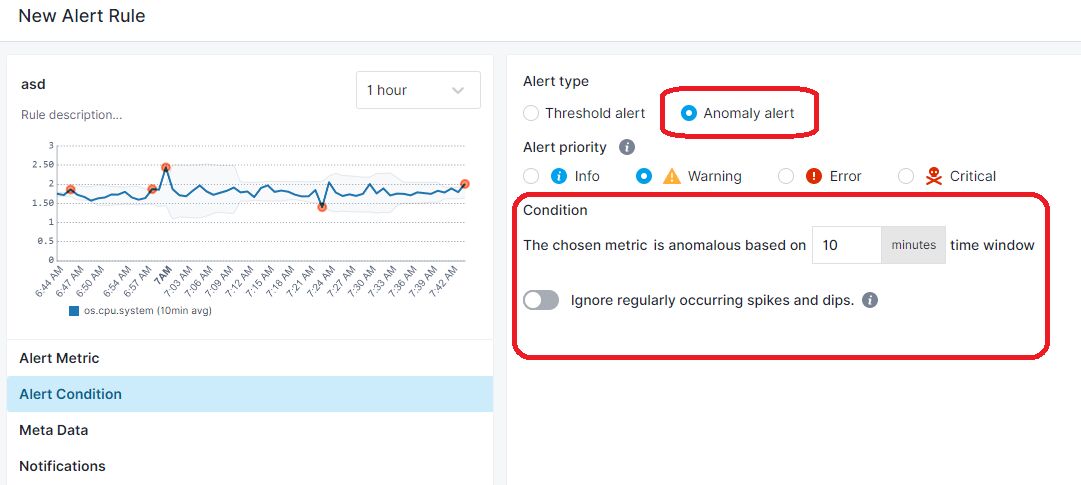
You also have the option to ignore outliers that are caused by constantly occurring spikes and dips to avoid having false/positive alerts.
When you set an anomaly alert, based on the sliding window Sematext Cloud immediately notifies you when there is something out of the ordinary and also notifies you when the value goes back within the normal range, “things are OK again, you can go back to sleep”.

You have the option to choose from various notification hooks and decide which channel you want to be notified when the alert is triggered. Notification hook channels include third party integrations that lets you create incidents with priority when an anomaly is detected.
Start the 14-day free trial and see yourself how Sematext can help you detect anomalies to ensure the smooth running of your system.
Frequently Asked Questions
Why do we need anomaly detection?
We need anomaly detection for identifying unusual patterns or events that may indicate a problem, allowing IT teams to detect issues early and take action before they become critical. It can also help organizations optimize resource allocation, deliver a better customer experience, comply with regulatory requirements, and enhance security by identifying suspicious or malicious activity.
What is anomaly vs outlier detection?
Anomaly and outlier detection are both techniques used to identify unusual data points in a dataset, but they have different meanings.
Anomaly detection refers to the identification of data points or patterns that deviate significantly from the norm or expected behavior. Anomalies may be indicative of a problem, such as a fault or an intrusion, and may require further investigation or action.
Outlier detection, on the other hand, refers to the identification of data points that are significantly different from other data points in the same dataset. Outliers may be caused by measurement errors, random variation, or other factors, and may not necessarily indicate a problem.