
With Solr 9 the Autoscaling Framework was removed – for being too complex and not terribly reliable – and instead we have Replica Placement Plugins. Unlike Autoscaling, replica placement only happens when you create a collection or add a new replica. Hence the name: it’s about where to place these new replicas.
In this article, we’ll look at the available replica placement plugins, what you can use them for and how to use them.
Before we get started, keep in mind that Sematext offers a full range of services for Solr!
Out-of-the-box Plugins
As of Solr 9.1, we have four implementations, all ending in PlacementFactory. We’ll just call out the prefixes here:
- Simple: this is the default, backwards-compatible behavior. It will simply round-robin through nodes. If you have more replicas for the same shard than you have nodes, it will allocate two copies on the same node (and that makes no sense). Thankfully, it’s the only placement plugin that does this.
- Random: as the name suggests, for each replica it will choose a random node.
- MinimizeCores: for each replica it tries to put it on the node with fewer cores.
- Affinity: this is MinimizeCores on steroids. Meaning you can give additional constraints, like allocating replicas of a collection on specific nodes, or on nodes with enough free space. You can also give recommendations, like allocating different copies of the same shard on different availability zones. We’ll talk about all of them in detail later.
Use Cases
Here’s a table of which plugin I’d use for which use-case:
| Plugin | Use-Case |
| Simple | Small, static clusters. The number of shards per collection is always a multiplier of the number of nodes => the distribution will always look OK. |
| Random | Logs or other time-series data in a large cluster: you keep adding collections with fewer shards than the number of nodes, but the last collection adds much more load than the rest => you don’t want to favor nodes with less existing load (disk, number of shards). |
| MinimizeCores | Multi-tenant search where you can always add tenants along with nodes. In this case, you’ll want to populate the newer nodes with the newer tenants. |
| Affinity | Similar use-cases as Simple and MinimizeCores, but where you need the extra functionality. For example, if your cluster is spread out to entities that are likely to fail together (e.g. availability zones). |
Now let’s get into more details about each of these use-cases and how the placement plugins can help.
Flat Cluster
Let’s assume all your nodes are equal and you may have one or more collections that need to be served by all nodes. This is the ideal use-case when you want to avoid hotspots by keeping your cluster balanced.
Here, the default (Simple) placement plugin works just fine. Here’s an example of a collection with 4 shards and replicationFactor 3 (so 12 shards in total), nicely spread out on a 3-node cluster:
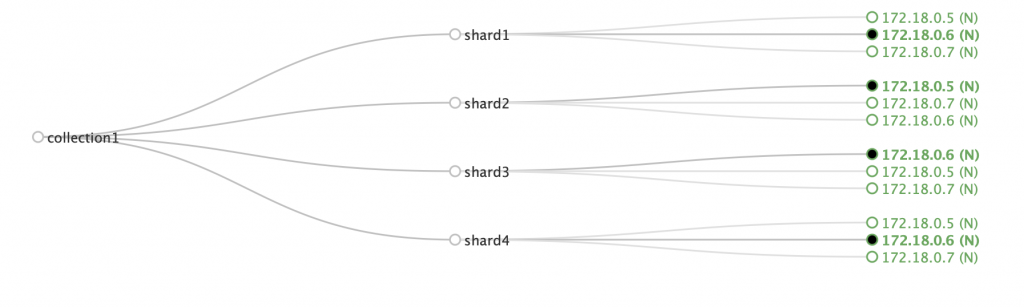
But if we try to create 3 collections of 4 shards each (2 leaders, 2 followers) on the same 3-node cluster, the Simple plugin shows its limits:
Notice how the node with the IP ending in 5 has a copy of each shard, while the other two nodes share the rest. Node 5 will be a hotspot here, not cool (pun intended).
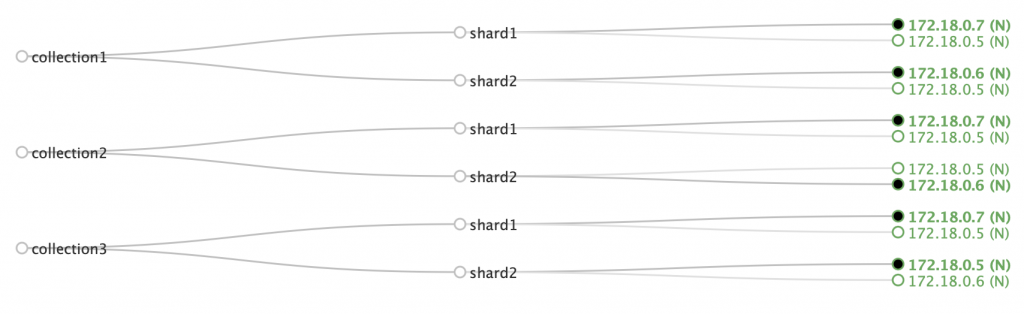
The Random plugin does a little better, with node 6 getting five shards, node 5 getting four and node 7 only three:
In other situations, it may do better or worse. But if you have hundreds of nodes and just a few shards per collection, we can expect the load to roughly balance out.
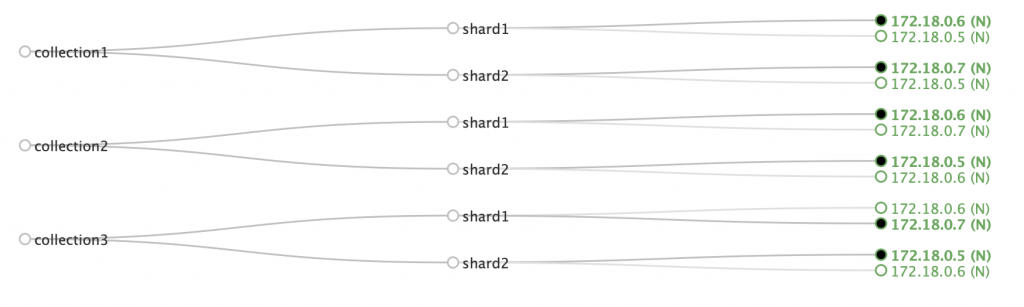
However, if the three collections in our example are equal in terms of load, we really want to balance shards across our three-node cluster. This is where MinimizeCores comes in (btw, Affinity will give you the same result):
We’ll still have hotspots if the collections aren’t equal in terms of load. In this was a real cluster, I’ll probably be better off to create the same collections with three shards instead of two. Then I’d have a balanced cluster even with the Simple plugin: proof that no placement plugin is a replacement for a good design (pun intended again).
Let’s go back to the non-ideal scenario and assume you can’t have a perfect balance by setting the number of shards per collection as a multiplier of the number of nodes. You may want to make sure you don’t run out of disk space. At this point, we’re in the territory of the Affinity plugin. To summarize it, the Affinity plugin can help you with the following:
- Disk space: don’t allocate replicas to nodes running out of disk space. Also, prefer allocating replicas to nodes with lots of free disk.
- Availability zone awareness: avoid allocating two copies of the same shard to what we’ll call an “availability zone”. This can be an actual availability zone in your favorite cloud provider or a rack or… anything that’s likely to fail all at once.
- Placing replica types: the typical use-case is separating writes from reads via TLOG and PULL replicas respectively. You may want different nodes serving those replicas. Affinity can help place a replica type to its corresponding nodes.
- Collection-to-node affinity: let’s say you have one or more collections that have to live on separate nodes from the other collections. Maybe the data is critical or some other reason. While you can store these special collections on a separate cluster altogether, you can also put them on separate nodes within the same cluster.
- Collection-to-collection affinity: say you have more nodes than shards in your collections, but you need some collections to be on the same nodes with each other. Typically, because you’ll need to do a join with a single-shard collection.
Now let’s expand on the implementation for each of these use-cases.
Account for Disk Space
If a node has little disk space, say under 50GB, I can make the Affinity plugin exclude that node from allocation:
curl -XPOST -H 'Content-Type: application/json' localhost:8983/api/cluster/plugin -d '{ "add":{ "name": ".placement-plugin", "class": "org.apache.solr.cluster.placement.plugins.AffinityPlacementFactory", "config": { "minimalFreeDiskGB": 50 } } }'
Notice a few things here:
- I hit the
/api/cluster/pluginto define the configuration. - I use the add command to define the configuration. If there is already a configuration defined (with the same name,
.placement-plugin, which is hard coded for this), you’d get an error. To update the configuration, changeaddtoupdate. If you want to remove the configuration and revert to default, send{"delete": ".placement-plugin"}. - The class is
org.apache.solr.cluster.placement.plugins.AffinityPlacementFactory. If I want to change to MinimizeCores, I’d sayorg.apache.solr.cluster.placement.plugins.MinimizeCoresPlacementFactoryand so on. - The config element is only needed for Affinity. That’s where I can set the disk usage limit. There is a default: 20GB as of Solr 9.1.
Here’s an example: I have two nodes in a cluster, one with more and one with less than 50GB. If I create a collection with 7 shards and replicationFactor=1, all the shards get allocated to the node with enough disk:
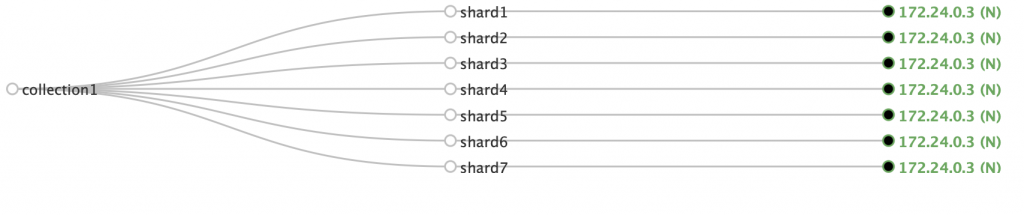
Affinity also allows you to set prioritizedFreeDiskGB. If a node has more than this much free disk, it will get the replica. Unless it breaks other rules, such as another copy of the same replica already being there. The default is 100GB. It’s useful when you add new nodes and want them to take load quickly.
prioritizedFreeDiskGB only works if replicas take more or less the same load (e.g. a multi-tenant system). If, on the other hand, new collections tend to take more load (e.g. time-series data), it will make new nodes become hotspots, as they’ll take most load.
Availability Zone Awareness
If you deploy Solr in a cloud environment, you’ll want to spread your cluster across availability zones (i.e. data centers with really good connection between them), so that if an availability zone goes down, your cluster will survive. But you’ll also have to make sure that none of the availability zones holds all the copies of one shard: otherwise if the AZ goes down, you lose the shard.
Availability zone awareness is baked into Affinity, so you don’t have to configure anything other than enabling it:
curl -XPOST -H 'Content-Type: application/json' localhost:8983/api/cluster/plugin -d '{ "add":{ "name": ".placement-plugin", "class": "org.apache.solr.cluster.placement.plugins.AffinityPlacementFactory" } }'
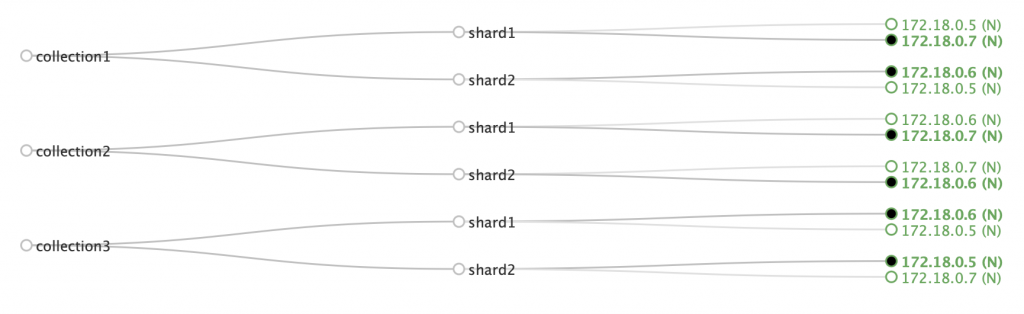
That said, your nodes need to have system properties (sysprops) to indicate their availability zone. For example, if you start a node with -Davailability_zone=zone1 and another node with -Davailability_zone=zone2, Solr will know they’re in different zones and will try to allocate different copies of the same shard to different zones. Here’s an example where nodes with IPs ending in 6 and 8 are in zone1, while 5 and 7 are in zone2:
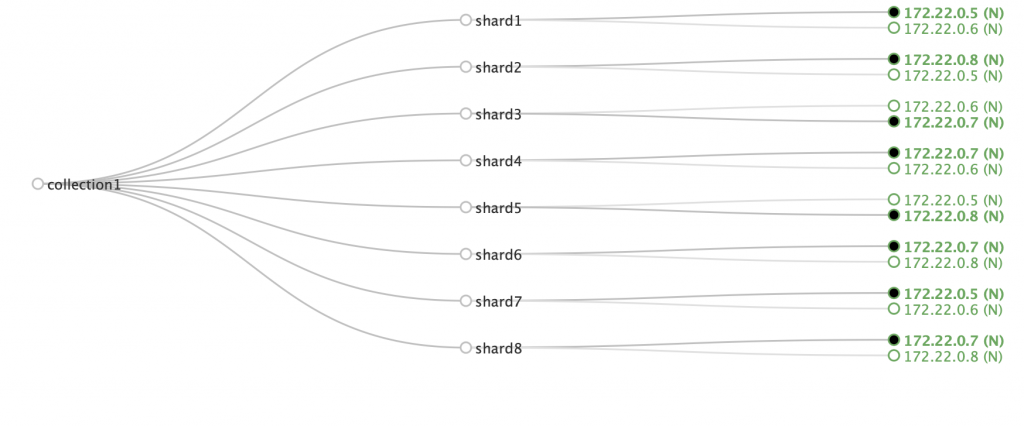
Notice how for each shard, you have one copy in an odd number node, the other copy in an even number node. This will work as long as the number of nodes in the availability zones is even (which is how they should be). Solr doesn’t enforce this rule like it does with disk space, for example. Here’s a cluster where nodes 5 and 6 are in zone1 and node 7 is in zone2:
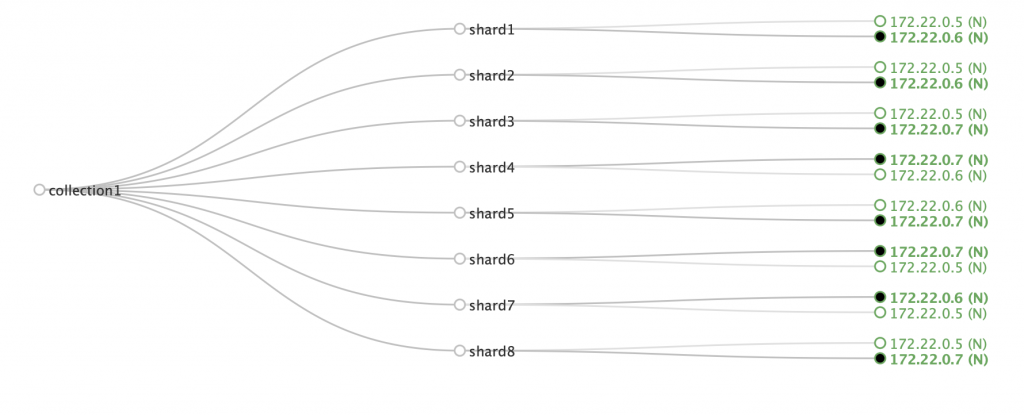
If zone1 goes down, you lose both copies of shards 1, 2 and 7.
Nodes Dedicated to Replica Types
The configurations so far work where you either have only NRT replicas (the default) or only TLOG replicas within the same collection. Sure, with TLOG replicas the leader takes more load and it would be nice to have that node more powerful than the followers, but you’d implement that outside placement plugins (e.g. by explicitly setting preferredLeader).
Instead, placement plugins can help you in a scenario where you have a few TLOG replicas (for fault-tolerant indexing) and as many PULL replicas as you want (to scale searches). In this situation, you might want to bind nodes to their respective replica types. This can be done via the replica_type system property in the same way you set availability zones: some will have the value tlog, some pull. You can also have nrt nodes, but you’ll only need them if some collections use NRT while others use TLOG+PULL.
You can also combine different rules. In the following example, I have 8 nodes across two availability zones. Within each availability zone, I have two TLOG nodes and two PULL. This is a local Docker setup, so here’s a quick proof:
% for CONTAINER in `docker ps | grep solr | awk '{print $1}'`; do docker inspect $CONTAINER | grep -e '"IPAddress": "172\|SOLR_OPTS'; done "SOLR_OPTS=-Dreplica_type=tlog -Davailability_zone=zone1", "IPAddress": "172.22.0.11", "SOLR_OPTS=-Dreplica_type=tlog -Davailability_zone=zone2", "IPAddress": "172.22.0.5", "SOLR_OPTS=-Dreplica_type=tlog -Davailability_zone=zone1", "IPAddress": "172.22.0.6", "SOLR_OPTS=-Dreplica_type=pull -Davailability_zone=zone1", "IPAddress": "172.22.0.9", "SOLR_OPTS=-Dreplica_type=pull -Davailability_zone=zone1", "IPAddress": "172.22.0.8", "SOLR_OPTS=-Dreplica_type=tlog -Davailability_zone=zone2", "IPAddress": "172.22.0.10", "SOLR_OPTS=-Dreplica_type=pull -Davailability_zone=zone2", "IPAddress": "172.22.0.7", "SOLR_OPTS=-Dreplica_type=pull -Davailability_zone=zone2", "IPAddress": "172.22.0.12",
Now if I create a collection with two shards, each of the shards with two TLOG replicas and two PULL replicas, Solr places:
- TLOG and PULL replicas on their respective nodes
- The two copies on each TLOG and PULL replica on different availability zones

Pretty cool, no? But wait, there’s more.
Before we move on, if you’re looking for a little help with running Apache Solr Cloud on Docker containers, then check out the short video below.
Sub-cluster: Collections on Specific Nodes
To store collections on specific nodes, you have another system property: node_type. Values are up to you, because you’ll use those values in the collectionNodeType configuration of the Affinity replica placement plugin. For example, if you have two collections: collection1 and collection3, and you labeled your nodes collection1_host and collection3_host, the configuration can look like this:
curl -XPOST -H 'Content-Type: application/json' localhost:8983/api/cluster/plugin -d '{ "add":{ "name": ".placement-plugin", "class": "org.apache.solr.cluster.placement.plugins.AffinityPlacementFactory", "config": { "collectionNodeType": { "collection1": "collection1_host", "collection3": "collection3_host", } } } }'
At this point, if you create the two collections, you’ll notice their replicas go to the correct nodes.
Co-locating Collections
Typically, co-locating is a sub-use-case of the previous use-case (where some collections are assigned to some nodes). For example, I have a 3-node cluster, one node hosting collection3 and two nodes hosting collection1. If I want to create collection2 and make sure it lands on the same nodes as collection1, I can add this collection2->collection1 mapping to the withCollection element:
"class": "org.apache.solr.cluster.placement.plugins.AffinityPlacementFactory", "config": { "withCollection": { "collection2": "collection1" }, "collectionNodeType": { "collection1": "collection1_host", "collection3": "collection3_host", } }
Now, after creating collection2, its shards are also on nodes with IPs ending in 3 and 4:
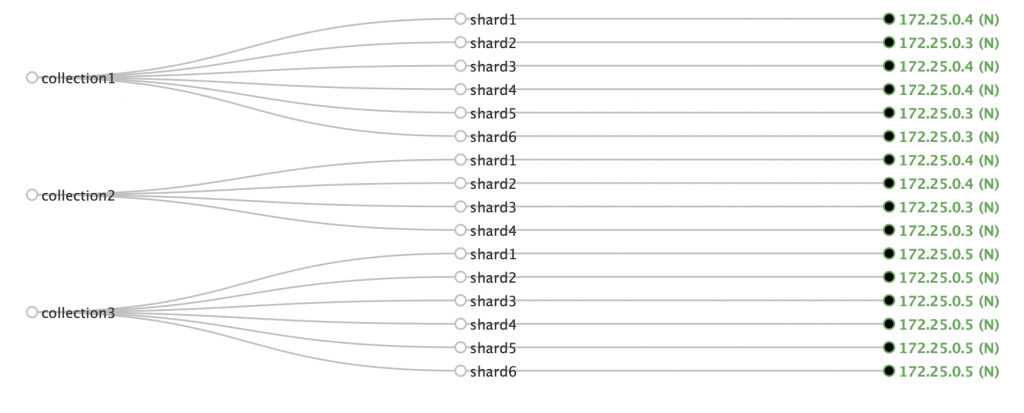
At this point, collection1 became a dependency for collection2. We can’t delete it unless we delete collection2 first. Otherwise, we get an error:
"Operation delete caused exception:": "org.apache.solr.cloud.api.collections.Assign$AssignmentException:org.apache.solr.cloud.api.collections.Assign$AssignmentException: org.apache.solr.cluster.placement.PlacementModificationException: colocated collection collection2 of collection1 still present",
Conclusion
The Replica Placement Plugins introduced in Solr 9 don’t have all the functionality of the old Autoscaling, but they cover the major use-cases:
- Simple clusters, where the total number of shards per collection divides by the number of nodes. This is normally the best design, but sometimes not possible due to other constraints.
- Clusters spread in different availability zones.
- Account for disk space and the number of existing replicas on nodes.
- Assign different replica types or different collections to different nodes.
For all but the first use-case, we’ll want to use the AffinityPlacementFactory plugin. For defining affinity (e.g. by availability zone or replica type), you can use predefined system properties (e.g. availability_zone and replica_type respectively).
Finally, if you’ve read all this, congratulations! And if you’re interested in more, do reach out, because we have:
- Solr Consulting, for when you need help with development or optimization around Solr.
- Solr Production Support, for putting out fires quickly.
- Solr Training, for learning more about Solr functionality like this.
Don’t need any of the above because you already know Solr? You might still want to reach out, because we’re hiring 🙂