When a data index is created in Elasticsearch, the data is divided into shards for horizontal scaling across multiple nodes. These shards are small pieces of data that make up the index and play a significant role in the performance and stability of Elasticsearch deployments.
A shard can be classified as either a primary shard or a replica shard. A replica is a copy of the primary shard, and whenever Elasticsearch indexes data, it is first indexed to one of the primary shards. The data is then replicated in all the replica shards of that shard so that both the primary and replica shards contain the same data.
Elasticsearch distributes the search load among the primary and replica shards, which enhances search performance. If the primary shard is lost, the replica can take its place as the new primary shard, so the replica provides fault tolerance as well.
The number of primary shards is fixed at index creation time and is defined in the settings. The number of replicas can be changed at any time without blocking search operations. However, this doesn’t apply to the number of primary shards, which should be defined before creating the index.
It is generally recommended to have at least one replica shard for each primary shard to ensure the availability and reliability of the cluster.
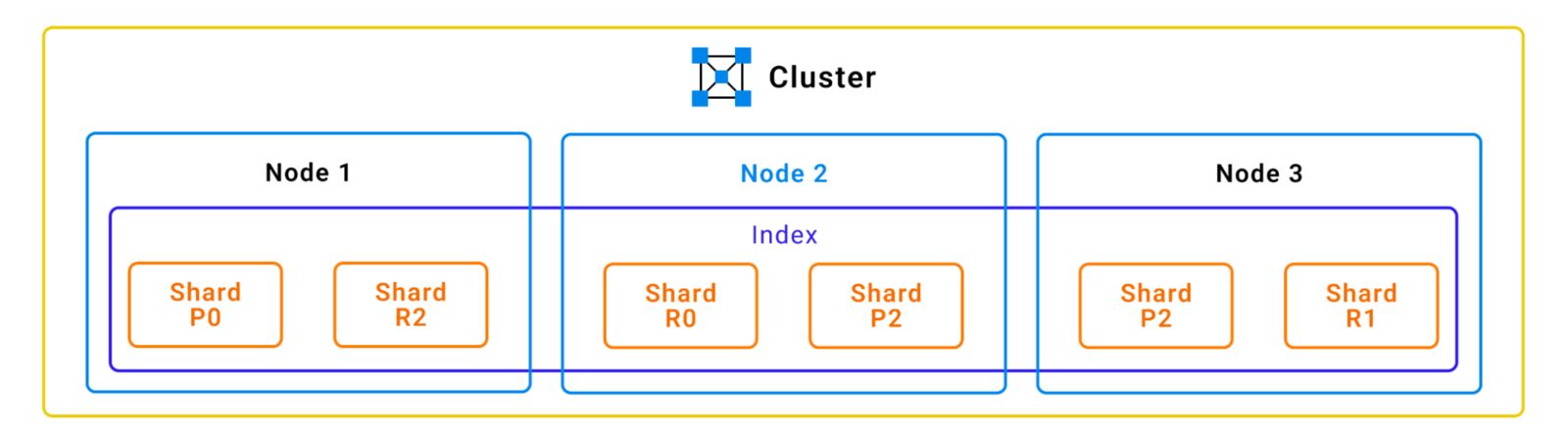
Primary shards and replica shards explanation. (Source)
If shards are not appropriately assigned or fail to be assigned, they end up in the unassigned state, which means the data allocated in the shard is no longer available for indexing and searching operations.
Why Shards Are Unassigned in Elasticsearch: Common Causes
Shards in Elasticsearch can go through different states during their lifetime:
- Initializing – This is the initial state before a shard is ready to be used.
- Started – This state represents when a shard is active and can receive requests.
- Relocating – This state occurs when a shard is in the process of being moved to a different node.
- Unassigned – This state occurs when a shard has failed to be assigned. The reason for this may vary, as explained below.
Ideally, you’d monitor these states over time, so you can see if there are periods of instability. Sematext Cloud can monitor that for you and alert on anomalies:
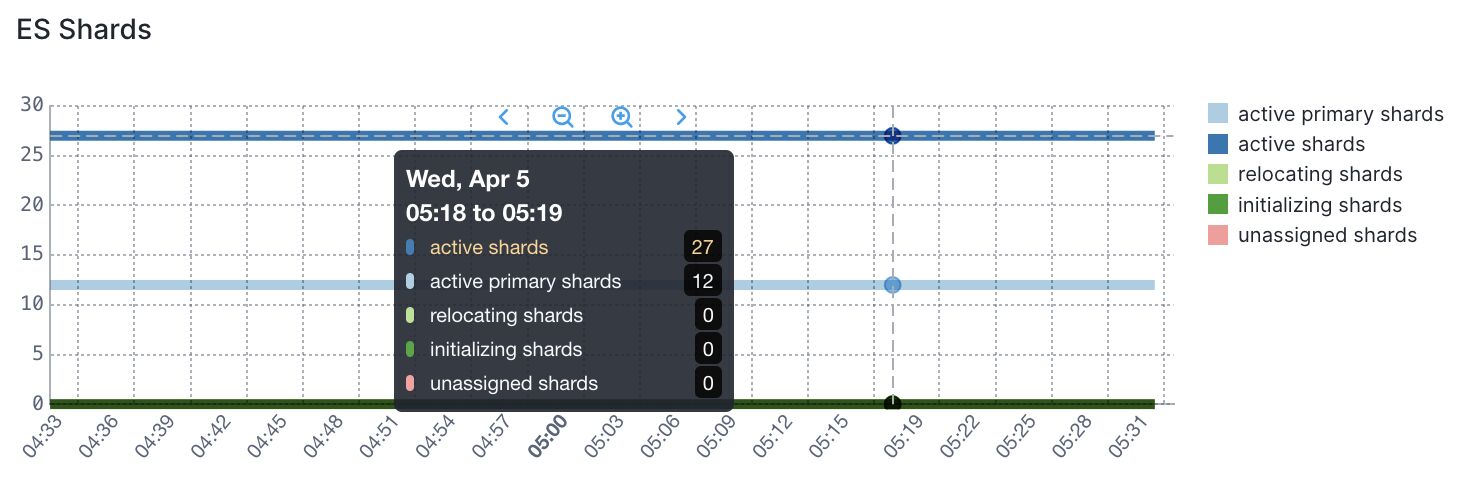
These are the most common cases for unassigned shards in Elasticsearch:
- More shards than available nodes
- Shard allocation being disabled
- Shard allocation failure
- A node leaving the cluster
- Network issues
How to Find Unassigned Shards in Elasticsearch
To find if the Elasticsearch cluster has unassigned shards, it is possible to leverage the Elasticsearch API.
Using the _cluster/health API, enter the following command:
GET _cluster/health
The output will show useful information about the status of the cluster and the state of the shards:
"cluster_name" : "wazuh",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 4,
"number_of_data_nodes" : 4,
"discovered_master" : true,
"active_primary_shards" : 280,
"active_shards" : 552,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 2,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
It is then possible to call the _cluster/allocation/explain endpoint to learn the reason for the current status which is yellow that means that primary shards are allocated but replica shards are not and hence, there are unassigned shards. For instance:
GET _cluster/allocation/explain
{
"index" : "my-index-000001",
"shard" : 0,
"primary" : true,
"current_state" : "unassigned",
"unassigned_info" : {
"reason" : "INDEX_CREATED",
"at" : "2022-11-04T18:08:16.600Z",
"last_allocation_status" : "no"
},
"can_allocate" : "no",
"allocate_explanation" : "Elasticsearch isn't allowed to allocate this shard to any of the nodes in the cluster. Choose a node to which you expect this shard to be allocated, find this node in the node-by-node explanation, and address the reasons which prevent Elasticsearch from allocating this shard there.",
Your One Stop Shop for Elasticsearch
| Platform | Open Source Stack | Community Help | Monitoring – Metrics, Logs. Health, Alerting SaaS | Training, Implementation & Maintenance | Production Support & Consulting |
|---|---|---|---|---|---|
| Elasticsearch | ✓ | ✓ | |||
| Elasticsearch + Sematext | ✓ | ✓ | ✓ | ✓ | ✓ |
How to Fix Unassigned Shards
The proper resolution of unassigned shard issues depends on the cause of the problem.
More Shards Than Available Nodes
Whenever the Elasticsearch cluster has more replicas than available nodes to allocate them to, or shards configuration restrictions, shards may become unassigned. The solution is either adding more nodes or reducing the number of replicas. For the latter, the Elasticsearch API can be used. For instance, to reduce the number of replicas in the .kibana index to zero you can use the following call:
PUT /.kibana/_settings
{
"index" : {
"number_of_replicas":0
}
}
To add more nodes to a cluster, follow these steps:
- Install Elasticsearch on the new nodes and make sure to use the same version of Elasticsearch that is running on the already deployed nodes.
- Configure the new nodes to join the existing Elasticsearch cluster. To do so, it is necessary to configure the name of the cluster, and the seed hosts option should be configured with the IP address or DNS of at least a running Elasticsearch node in the elasticsearch.yml configuration file.
- Start the Elasticsearch process on the new nodes.
More information can be found here: https://www.elastic.co/guide/en/elasticsearch/reference/current/important-settings.html
After adding the new node, the Elasticsearch master node will balance the shards automatically. However, it is possible to manually move the shards across the nodes of the cluster with the Elasticsearch API. Here there is an example of the _cluster/reroute endpoint and the move operation; in this case, Elasticsearch will move the shard “0” with the index “my_index” from “node1” to “node2”:
POST _cluster/reroute
{
"commands": [
{
"move": {
"index": "my_index",
"shard": 0,
"from_node": "node1",
"to_node": "node2"
}
}
]
}
It is possible to update the settings of the indices to decrease the number of replicas of the already indexed data. This will remove unassigned replicas and recover the cluster’s normal state, but there will not be a backup of the primary shards in case of failure and hence, it is possible to face data loss.
Here is an example of the endpoint call used to reduce the number of replicas to 0.
PUT /myindex/_settings
{
"index" : {
"number_of_replicas" : 0
}
}
Shard Allocation Disabled
It is possible that shard allocation may be disabled. When this occurs, it is necessary to re-enable allocation in the cluster by using the _cluster/settings API endpoint. Here is an example of the endpoint call:
PUT _cluster/settings
{
"transient" : {
"cluster.routing.allocation.enable": true
}
}
After enabling the allocation, Elasticsearch will automatically allocate and move the shards as needed to balance the load and ensure that all the shards are allocated to a node. However, if this still fails, the reroute endpoint can be used again to finish the operation:
POST _cluster/reroute?retry_failed=true
Shard Allocation Failure
Shard allocation failure is one of the most frequent issues when it comes to unassigned shards. Whenever a shard allocation failure occurs, Elasticsearch will automatically retry the allocation five times before giving up. This setting can be changed so that more retries are attempted, but the issue may persist until the root cause is determined.
The failure may happen for a few reasons.
Shard allocation failed during allocation and rebalancing operations due to a lack of disk space
Elasticsearch indices are stored in the Elasticsearch nodes, which can fill up the server’s disk space if no measures are taken to avoid it. To prevent this from happening, Elasticsearch has established disk watermarks that represent thresholds to ensure that all nodes have enough disk space.
Whenever the low watermark is crossed, Elasticsearch will stop allocating shards to that node. Elasticsearch will aim to move shards from a node whose disk usage is above the high watermark level. Additionally, if this watermark is exceeded, Elasticsearch can reach the “flood-stage” watermark, when it will block writing operations to all the indices that have one shard (primary or replica) in the node affected.
While it is possible to increase the Elasticsearch thresholds, there is a risk that the disk will completely fill up, causing the server to be unable to function properly.
To avoid running out of disk, you can delete old indices, add new nodes to the cluster, or increase disk space on the node.
The _cluster/settings API endpoint can be used to change the thresholds. Set the cluster.routing.allocation.disk.watermark.low and cluster.routing.allocation.disk.watermark.high settings in the request body.
Here is an example of the command to set the low watermark to 80% and the high watermark to 90% using the Elasticsearch API:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "80%",
"cluster.routing.allocation.disk.watermark.high": "90%"
}
}
Shard allocation failed because is not possible due to allocation rules
It is possible to define rules to control which shards can go to which nodes. For instance, Shard allocation awareness or Shard allocation filtering.
The forced awareness setting controls replica shard allocation for every location. This option prevents a location from being overloaded until nodes are available in a different location. More information about this setting can be found here: https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cluster.html#forced-awareness
The shard allocation filter setting controls where Elasticsearch allocates shards from any index. More information about this setting can be found here: https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cluster.html#cluster-shard-allocation-filtering
A Node Leaving The Cluster
Nodes in the cluster can fail or leave the cluster for different reasons. If a node is absent from the cluster, the data might be missing if no replicas are in place and/or the node cannot be recovered.
The allocation of replica shards that become unassigned because a node has left can be delayed with the index.unassigned.node_left.delayed_timeout API endpoint, which defaults to 1 minute. Here is an example:
PUT _all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
However, if the node is not going to return, it is possible to configure Elasticsearch to immediately assign the shards to the other nodes by updating the timeout to zero:
PUT _all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "0"
}
}
Additionally, there are certain cases where it is not possible to recover the shards, such as if the node hosting the shard fails and cannot be recovered. In those cases, it will be necessary to either delete and reindex the affected index or restore the data from a backup. However, deleting the index will delete the data stored in that index.
The following endpoint can delete a specific index with failures:
DELETE my-index
Network Issues
If the nodes don’t have connectivity in the Elasticsearch cluster port range, the shards might not be properly allocated. If there is no connectivity between the node that hosts the primary shard and the node that hosts a new replica, recovery is not possible until connectivity is recovered. In this case, it is necessary to check firewall/SELinux constraints.
The following command can be used to test connectivity:
nc -zv node_ip 9300-9400
The ports used by Elasticsearch are explained here: https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html#common-network-settings
It is also possible that the shards are too big for the network bandwidth to handle. In this case, it is possible to add more primary shards per index for new indices. To accomplish the same for already created indices, it is possible to create a new index and reindex using the Reindex API. For instance:
POST _reindex
{
"source": {
"index": "<source_index_name>"
},
"dest": {
"index": "<target_index_name>"
}
}
If you are using an alias, you can point the alias to the new index:
POST _aliases
{
"actions": [
{ "add": { "index": "target_index_name", "alias": "existing_alias" } },
{ "remove": { "index": "source_index_name", "alias": "existing_alias" } }
How to Maintain an Optimal Elasticsearch Cluster
You might avoid issues caused by unassigned shards in Elasticsearch by monitoring and detecting potential problems early on and maintaining cluster health.
Monitoring and Detection
Monitoring the Elasticsearch cluster is very important to avoid issues in normal operation and avoid data loss. For this, you might rely on observability tools like Sematext Cloud, which has Elasticsearch monitoring capabilities. Here’s the default Overview dashboard, though you have many others and you can create your own:
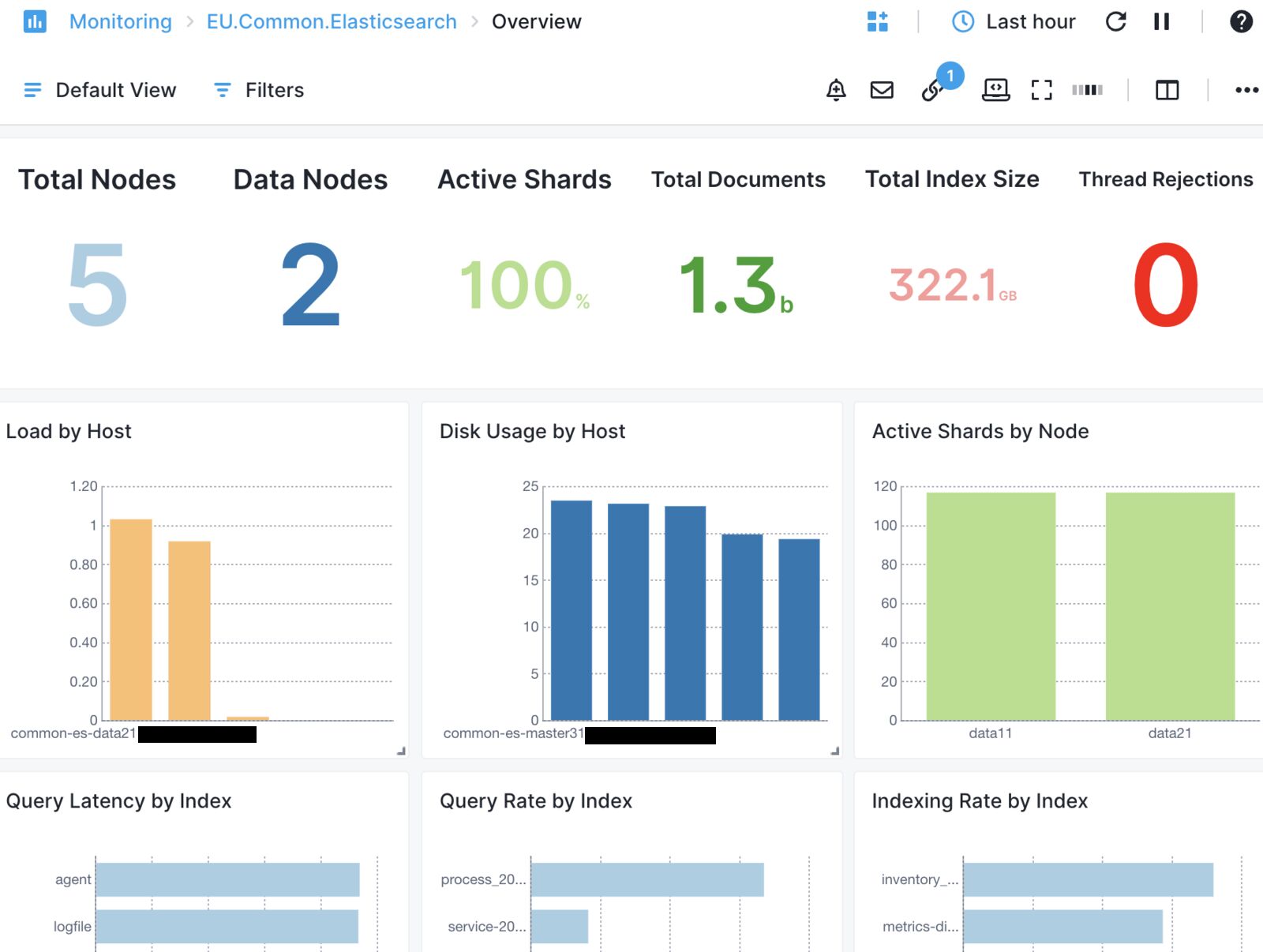
There are also various API endpoints to retrieve the status of the cluster, its nodes, usage, and shard allocation:
- Cluster health API returns the health status of a cluster.
- Nodes API returns information about the cluster’s nodes.
- Shards API provides a detailed view of which nodes contain which shards.
- Indices API returns information about the indices in a cluster.
In addition to this, Elasticsearch logs can be used to get information about the cluster activity and any errors or issues in the cluster. Some of the areas to monitor include:
- Errors or exceptions. These can indicate an issue with the cluster or operations being performed on it.
- Resource usage. High resource usage can indicate that the cluster is under a high load.
- Performance. If the cluster is performing poorly, there could be a problem that needs to be addressed.
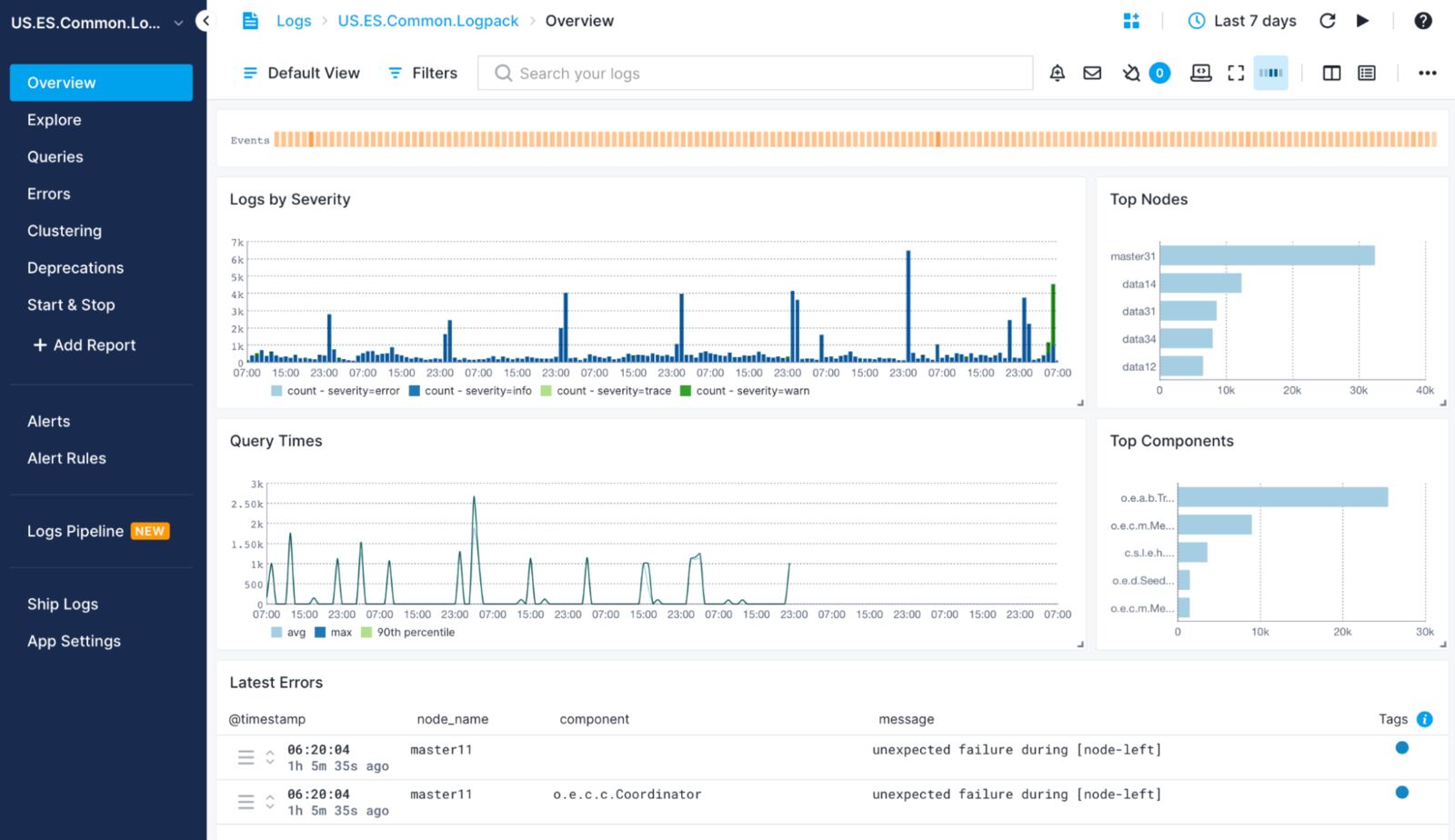
Note that Sematext Cloud can, out of the box, parse and centralize your Elasticsearch logs so you can see the above info in default (but customizable) dashboards:
Cluster Health Maintenance
To properly maintain the status of the Elasticsearch cluster, indices should be managed to avoid further issues. For example, if old indices are not removed, the server’s disk space could be affected, and the number of shards may grow to a point where the hardware of the server cannot keep up with the operations.
If the indices are time-based data, they can be managed using their timestamp as a reference. Other conditions may be applied to manage indices.
To manage the indices, there is a feature called index lifecycle management (ILM). It allows the definition of rules for managing the indices in the cluster, including actions such as closing, opening, or deleting indices based on specific criteria. For instance, it is possible to close indices that have not been accessed for a certain period of time or delete indices that have reached a certain age or size. This can help free up resources and improve the overall performance of the cluster.
The figure below shows an example of a policy consisting of four phases. In the Hot phase, there is a rollover action if the index surpasses 50 GB within one minute; otherwise, it will enter the Warm phase, but there is no action for this phase. After two minutes, the index will enter the Cold phase and, finally, will get deleted after three minutes.
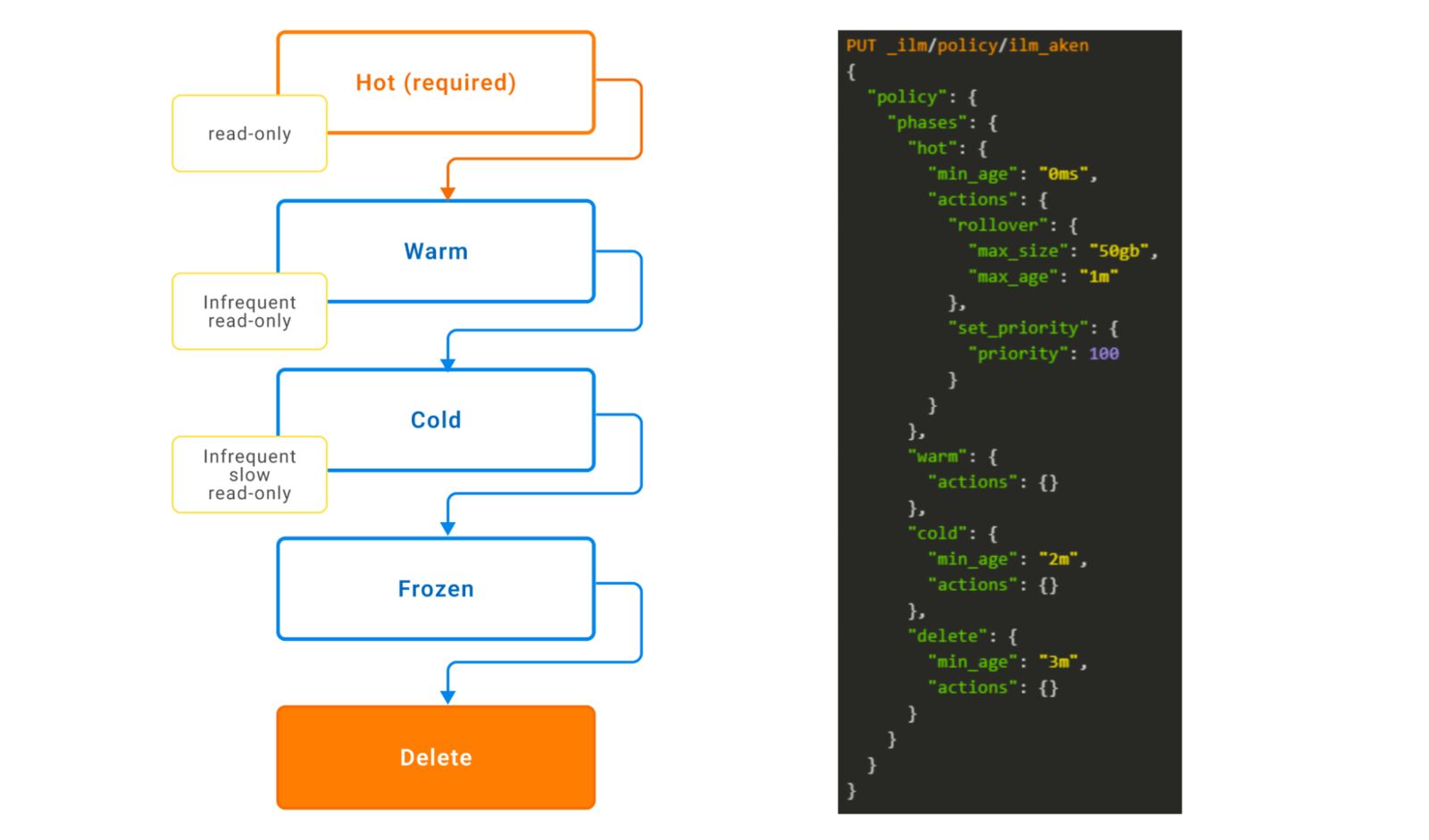
Elasticsearch ILM example policy (source).
{kind=link}
Still need some help? Sematext provides a full range of services for Elasticsearch and its entire ecosystem.
Conclusion
Unassigned shards can be a significant issue for Elasticsearch users because they can impact the performance and availability of the index. In this guide, tips and recommendations on how to resolve the issue were given.
You can use the Elasticsearch API to find out the root cause of the issue by leveraging the Cluster Allocation Explain and Cluster Health endpoints. It is then possible to take corrective measures to solve the issue, such as adding more nodes, removing data, and changing the cluster settings and index settings.
Additionally, you can leverage Elasticsearch monitoring tools like Sematext Cloud to make sure your cluster is set up to avoid similar issues in the future.
By following these recommendations, you can ensure that your Elasticsearch cluster remains healthy and able to handle the demands of your data. If you want to learn more about Elasticsearch you can check Sematext training. If you need specialized help with production environments, check out the production support subscriptions.