
When we say “logs” we really mean any kind of time-series data: events, social media, you name it. See Jordan Sissel’s definition of time + data. And when we talk about autoscaling, what we really want is a hands-off approach at handling Elasticsearch clusters.
In this post, we’ll show you how to use a Kubernetes Operator to autoscale Elasticsearch clusters, going through the following with just a few commands:
- Deploy the cluster in Kubernetes with N data nodes and M master nodes.
- Set up templates for your index series.
- Set up an initial index and an alias pointing to it, ready to handle writes.
- Set up an ILM/ISM policy to automatically rotate indices by size, expire old data, etc.
- Autoscale the cluster based on metrics relevant to you. As the Elasticsearch cluster scales up or down, the operator will also maintain the configuration initially uploaded, such as the number of shards per index.
Speaking of metrics, check out this video on which Elasticsearch metrics to monitor:
The same approach – and operator – will apply to OpenSearch. In fact, the enhancements we added to the operator were developed and tested with OpenSearch.
[product_banner type=”kubernetes”]Effortlessly monitor your entire Kubernetes infrastructure in minutes.[/product_banner]
Why Use an Operator for Scaling?
Kubernetes, on its own, can help you spawn an Elasticsearch cluster. Typically, you’d have a StatefulSet for your data nodes, one for your Master nodes, define the number of nodes you want, and you’re all set. The cluster is up.
But taking care of the Elasticsearch cluster requires some operational understanding. Say you need to do a rolling restart. Perhaps because of an upgrade or just a configuration change. You can’t simply go around killing all pods in the StatefulSet and rely on Kubernetes to restart them, because you have to make sure that at least one copy of every shard is up at all times. So when you remove a Kubernetes pod, you need to wait for it to be re-created and completely recovered before proceeding to the next one.
This is where Operators come in handy. Think of them like sidecar pods that can carry any kind of logic. They can be aware of your use-case and check to see if there’s something to reconcile between the current state and the desired state. You can tell the operator to do a rolling restart, for example, and it will know what to do. Some Elasticsearch operators can do autoscaling as well, let’s check them out.
Existing Operators
There are lots of Elasticsearch and OpenSearch operators out there, but unfortunately many of them are not actively maintained. That said, there are some which we would recommend using:
Elastic Cloud on Kubernetes. It’s the official operator for Elasticsearch and we wrote a how-to for it here. Unfortunately, it’s not really open-source, since it’s under the Elastic license. Also, you’ll need an Enterprise license to use the autoscaling functionality.
OpenSearch K8s Operator. The go-to Operator for OpenSearch. It’s open-source but, at the time of this writing, it doesn’t have autoscaling. But we did some experiments and it’s relatively easy to plug in logic that adds and removes nodes, since this Operator knows how to handle new nodes and how to drain nodes that you want to remove. We wrote a tutorial for using the OpenSearch Operator here.
es-operator. This is an Operator that Zalando is using for a while in production. It’s open-source and it already supports autoscaling for the Enterprise Search use-case (i.e. data that isn’t time series). It can scale based on CPU or based on the number of shards per node. It can also automatically add replicas if you have more nodes than shards.
We modified es-operator to work for the time-series use-case. Namely, to handle index templates, lifecycle policies and autoscaling when you keep creating and removing indices, rolling them over by size.
In the rest of this article, we’ll show the main ideas behind this Operator and how it implements them. Through a demo, of course 🙂
How to Autoscale Elasticsearch?
Initial Elasticsearch Cluster Setup
To use our fork of es-operator, you can clone our fork of the es-operator-demo repository.
Now let’s set up an Elasticsearch cluster. We’ll need to go through a few steps, all covered here. You can do this on your local machine or on any Kubernetes cluster.
If you have Docker for Desktop’s Kubernetes, you’ll need to start by installing the Metrics Server:
kubectl apply -f manifests/components.yaml
Next up, let’s set up permissions. Our operator will need to be able to create the Elasticsearch pods, for example. This is what our next RBAC-focused YAML file will do, and we’re going to apply those permissions to a separate namespace called demo:
kubectl apply -f manifests/cluster-roles.yaml
Before we deploy the operator itself, we need to define the configuration it’s supposed to work on. This is what the Custom Resource Definitions do. In this case, we’ll define things like scaleUpDiskUsagePercentBoundary – when nodes reach X% disk space, we scale up the cluster:
kubectl apply -f manifests/custom-resource-definitions.yaml
Now we’re ready to deploy the operator. It will be a deployment with one replica (i.e. we’ll have one instance of the operator):
kubectl apply -f manifests/es-operator.yaml
It should be up and running now in your demo namespace:
kubectl -n demo get pods
You can also tail the log of the operator pod (replace $POD_SUFFIX to get your actual operator pod name):
kubectl -n demo logs es-operator-$POD_SUFFIX -f
Now we’re ready to start the initial Elasticsearch pods. Our operator will only manage data nodes, so we’ll deploy the master node(s) separately as a StatefulSet:
kubectl apply -f manifests/elasticsearch-cluster.yaml
You can use kubectl -n demo get pods again to see the Elasticsearch master pod. In elasticsearch-cluster.yaml, we also have a Service that exposes port 9200, so we can do a port-forward to this service and talk to the master node:
kubectl -n demo port-forward svc/es-http 9200 # in another terminal curl localhost:9200
Finally, let’s add the data nodes, managed by the operator. This is where we put all the interesting options, such as the minimum and maximum number of data nodes (minReplicas and maxReplicas respectively), when to scale up, etc.
kubectl apply -f manifests/es-data1.yaml
We’ll discuss more options in the next section, but for now, let’s take a look at what we have:
- A cluster with one master and two data nodes. Check it with
curl localhost:9200/_cat/nodes - An index template which applies to logstash* indices. Check it with
curl 'localhost:9200/_index_template?pretty'It’s made up of two component templates: one calledlogstashwhich defines the mapping and most settings, such as the refresh interval. The other is calledscalingwhich defines the number of shards. Check them both viacurl 'localhost:9200/_component_template?pretty'The operator will change thescalingcomponent template as we scale up and down. For now, we have two shards (one primary and one replica), as we only have two nodes. - A first index called logstash-000001 (which inherited the above templates) and a write alias (
logstash_write) pointing to it. We can configure Logstash (or any other log shipper) to uselogstash_writeto index new data. - An Index State Management (ISM) policy that will roll indices over every 10GB and expire data after 7 days. Check it out via
curl 'localhost:9200/_plugins/_ism/policies?pretty'The operator may increase the index rollover size when scaling up. If you’re following this tutorial on Elasticsearch and not OpenSearch, you’ll need to adapt the code to work with “original” Index Lifecycle Management (ILM) instead of ISM. It should be easy, because ILM is more mature (and, for the most part, more feature-rich) than ISM.
Speaking of scaling up, let’s see how this works.
Elasticsearch Autoscaling
The main challenge, as clusters scale up or down, is to keep the load between nodes balanced. In other words, to prevent hotspots. For example, let’s consider this 4-node cluster with two indices: logs01 and logs02.
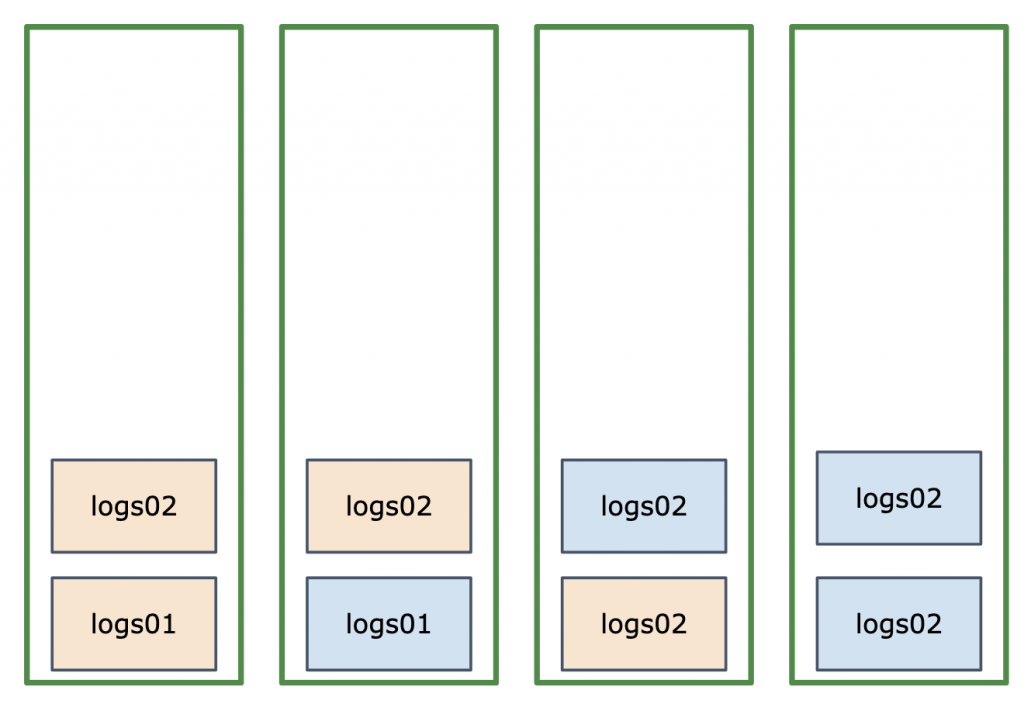
On the surface, it looks balanced: Elasticsearch tries to balance shards and even indices if possible. But in the case of time series data we write to the write alias, which points to the last index (logs02). And writing is often the main workload. In the above example, we have two shards of logs02 on the last two nodes, so we can expect them to take more load.
Our recommendation is to make sure that the number of shards for the “write” index matches the number of nodes. In this example, we can rollover to the next index (logs03) and make sure that index has 2 shards instead of 3. Here’s how the cluster would look like:
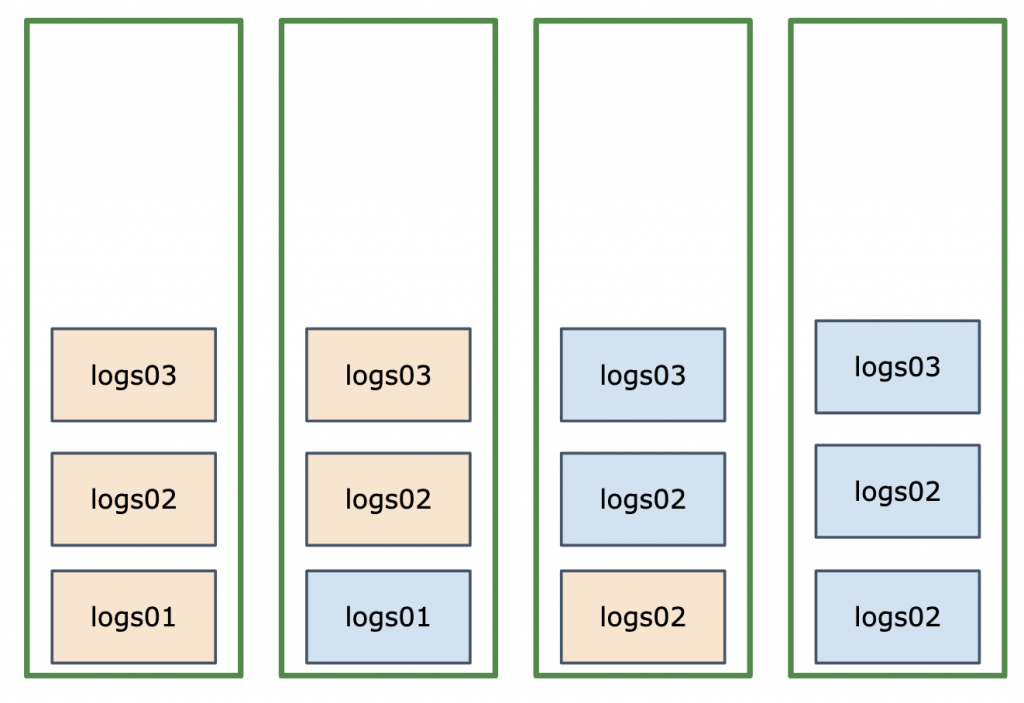
As you can see, our cluster is now balanced for writes, too – especially if we enforce this balance via total_shards_per_node. Which is also managed by the operator – let’s continue the tutorial and see how the Elasticsearch cluster autoscales up or down.
Scaling Up
With the demo configuration, the cluster will scale up if any of the following happen (all configurable in es-data1.yaml):
- Too many shards per node: maxShardsPerNode: 10
- Too much CPU usage (in milliCPUs): scaleUpCPUBoundary: 6000
- Too much disk usage: scaleUpDiskUsagePercentBoundary: 80
In practice, you’ll likely only configure disk usage, because you’ll normally know with your dataset that you need to add nodes at a specific threshold. You can set other thresholds to very high values, so that they don’t get in the way.
To simulate the need for scale up in a local environment (e.g. Docker Desktop), you can edit es-data1.yaml and lower scaleUpDiskUsagePercentBoundary. Just make sure that scaleDownDiskUsagePercentBoundary is lower. For example, you can have 2 and 1 respectively. Then, re-apply the configuration:
kubectl apply -f manifests/es-data1.yaml
If you’re still tailing the logs of the es-operator pod, you should see exactly what happens:
- It notices the actual disk usage is higher than the threshold:
Updating desired scaling for EDS 'demo/es-data1'. New desired replicas: 4. Scaling up to 4 nodes because 40.16 is higher than 2.00 - It changes the size of the StatefulSet to create more pods:
reason: 'ChangingReplicas' Changing replicas 3 -> 4 for StatefulSet 'demo/es-data1' - It waits for the new node do be ready:
Waiting for stabilization: StatefulSet demo/es-data1 has 3/4 ready replicas - It updates the scaling component template with the new number of shards and the
total_shards_per_nodevalue:Putting template component: [...]"number_of_shards\": 2 [...] total_shards_per_node\": 2 [...] - It updates the ISM policy with an index size to match the number of shards, so that we rotate indices at 10GB per shard:
Updating ISM policy with min_size 20gb - Finally, it rolls over the logstash_write alias to create a new index with the correct number of shards:
Forcing rollover for alias: logstash_write to change from 3 to 2 shards
Keen observers might be wondering:
- Why 10GB per shard instead of per index? In our tests we noticed that 10GB seems to be a sweet spot for a Lucene index – after that, indexing will require more segment merges and writes tend to be much slower. As we increase the number of shards (and nodes), we want to keep that sweet spot, we don’t want to create too many tiny shards.
- Why do we lower the number of shards from 3 to 2 if we scale UP? In these sample logs, we went from 3 nodes to 4. With 3 nodes, we need 3 shards for a perfect balance – assuming we have one replica for each primary. For 4 nodes, we only need 2 shards, because with replicas we’ll get a total of 4. In other words, with one replica, you need N shards for N nodes if N is uneven. If N is even, you need N/2 shards.
- Why is total_shards_per_node=2 when you only have one shard per node? Nice catch! There are two reasons for that: first is that it’s a good idea to have some headroom: if a node goes down and Kubernetes has a hard time replacing it, Elasticsearch will try to recreate the missing shards on the remaining nodes. But if the
total_shards_per_nodeconstraint is already at 100%, there’s no room to create additional shards on the remaining nodes, so the cluster will be yellow. The second reason is a long-standing bug that sometimes shards won’t be allocated even if total_shards_per_node would allow it.
Scaling Down
Going back to es-data1.yaml, we scale down if we don’t have a reason to scale up, but at least one of the following happens:
- Too little CPU usage:
scaleDownCPUBoundary - Too little disk usage:
scaleDownThresholdDurationSeconds - Assuming that, after scale-down, we wouldn’t break constraints like
maxShardsPerNodeanddiskUsagePercentScaledownWatermark
If you’re running this demo on a local Docker Desktop, you can simulate a scale-down by reverting the change you made in the previous section and applying es-data1.yaml again. If you had your cluster scaled up due to load or indexed data, reduce the load or remove some indices. Then you will notice what happens during scale down in the operator’s logs:
- The Operator initiates a scale down:
Actual replicas 4 and desired replicas 3 - You’ll see in the list of priorities which pod will be removed. It should be the last one:
Pod es-data1-3 with priority 1 - Before being removed, the pod is drained:
Draining Pod demo/es-data1-3 for scaledown. Let’s see how this happens - First of all, the cluster needs to be healthy:
Ensuring cluster is in green state - In order for shards to be able to move, it removes the total_shards_per_node constraint from all indices:
Removing total_shards_per_node from all indices. New rolled over index will have the new value - Shard allocation filtering is used to exclude this node from allocation:
Excluding pod demo/es-data1-3 from shard allocation - It waits for this node to have 0 shards:
Waiting for draining to finish. When that happens (Found 0 remaining shards) we’re done (Pod demo/es-data1-3 drained) - Now we can remove the pod by resizing the StatefulSet:
Changing replicas 4 -> 3 for StatefulSet 'demo/es-data1' - Once the StatefulSet is stable (
Waiting for stabilization: StatefulSet demo/es-data1 has 4/3 ready replicas), you’ll see the same messages as before: the operator adjusts the component template and ISM policy, then it forces an index rollover via the Rollover API to create a new index
Video and Slides
If you can’t/don’t want to do the demo above, maybe you want to watch it on a multi-node Kubernetes cluster on AWS. We did that + a lot more explaining, during Berlin Buzzwords. Scaling up and down was done by indexing some dummy data.
If you prefer slides, check them out here:
Conclusion
Autoscaling Elasticsearch is definitely something you can do with Kubernetes operators. For E-commerce and other flat-index use-cases, the ecosystem is quite mature already. For logs and other time-series data, you need some additional logic in order to maintain cluster balance. But that’s also doable, as you saw in this article.
What next? Well, if you’re interested in:
- Learning more about Elasticsearch? Check out our training classes.
- Developing your specific setup? We can do that through consulting.
- Assistance with production fires? We offer production support.
- Monitoring Elasticsearch and/or Kubernetes? Check out Sematext Cloud, our observability SaaS. We are particularly proud of our Elasticsearch metrics&logs synergy, and we also offer Elasticsearch services like consulting and support.
Last but not least, feel free to share your comments and questions with us on Twitter.