
As shown in Part 1 – ClickHouse Monitoring Key Metrics – the setup, tuning, and operations of ClickHouse require deep insights into the performance metrics such as locks, replication status, merge operations, cache usage and many more. Sematext provides an excellent alternative to other ClickHouse monitoring tools, a more comprehensive – and easy to set up – monitoring solution for ClickHouse and other technologies in your infrastructure.
How much hair do you have?
Open-source monitoring tools are free, but your time is not. Relatively speaking, it’s actually rather expensive. Thus, Sematext aims to save you time, effort….and your hair.
Here are a few things you will NOT have to do when using Sematext for ClickHouse monitoring:
- figure out which metrics to collect and which ones to ignore
- give metrics meaningful labels
- hunt for metric descriptions in the docs so that you know what each of them actually shows
- build charts to group metrics that you really want on the same charts, not N separate charts
- figure out, for each metrics, which aggregation to use (min? max? avg? something else?)
- build dashboards to combine charts with metrics you typically want to see together
- set up basic alert rules
The above is not even a complete story. Want to collect ClickHouse logs? Want to structure them? Prepare to do more legwork. Sematext does all this automatically for you!
Sematext’s auto-discovery of services lets you automatically start monitoring your Clickhouse instances directly through the user interface.
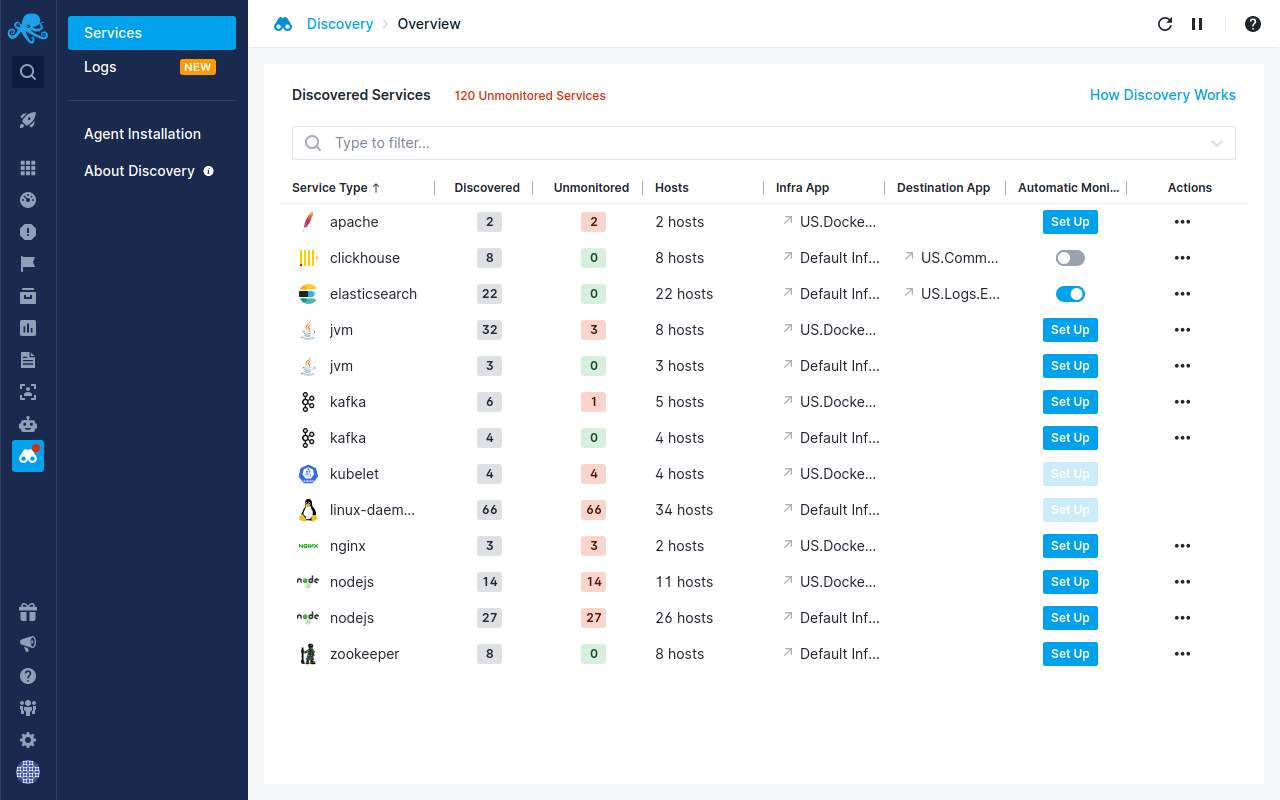
In this post, we will look at how Sematext provides more comprehensive – and easy to set up – monitoring for ClickHouse and other technologies in your infrastructure by combining events, logs, and metrics together in one integrated full-stack observability platform. By using the Sematext open-source monitoring agent and its integrations, which are also open-source, you can monitor your whole infrastructure and apps, not just your ClickHouse DB. You can see how it compares to similar solutions in our article about the best IT monitoring software.
You can also get deeper visibility into your full-stack by collecting, processing, and analyzing your logs.
ClickHouse Monitoring
Collecting ClickHouse Metrics
Sematext ClickHouse integration collects over 70 different ClickHouse metrics for system, queries, merge tree, replication, replicas, mark cache, R/W buffers, dictionaries, locks, distributed engine, as well as Zookeeper errors & wait times. Sematext maintains and supports official ClickHouse monitoring integration. Moreover, the Sematext ClickHouse integration is customizable and open source.
Bottom line: you don’t need to deal with configuring the agent for metrics collection, which is the first huge time saver!
Installing Monitoring Agent
Setting up the monitoring agent takes less than 5 minutes:
-
- Create a ClickHouse App in the Integrations / Overview (or Sematext Cloud Europe). This will let you install the agent and control access to your monitoring and logs data. The short What is an App in Sematext Cloud video has more details.
- Name your ClickHouse monitoring App and, if you want to collect ClickHouse logs as well, create a Logs App along the way.
- Install the Sematext Agent according to the setup instructions displayed in the UI.

For example, on Ubuntu, add Sematext Linux packages with the following command:
echo "deb http://pub-repo.sematext.com/ubuntu sematext main" | sudo tee /etc/apt/sources.list.d/sematext.list > /dev/null wget -O - https://pub-repo.sematext.com/ubuntu/sematext.gpg.key | sudo apt-key add - sudo apt-get update sudo apt-get install spm-client
Then setup ClickHouse monitoring by providing ClickHouse server connection details:
sudo bash /opt/spm/bin/setup-sematext --monitoring-token --app-type clickhouse --agent-type standalone --SPM_MONITOR_CLICKHOUSE_DB_USER '' --SPM_MONITOR_CLICKHOUSE_DB_PASSWORD '' --SPM_MONITOR_CLICKHOUSE_DB_HOST_PORT 'localhost:8123'
The last step, go grab a drink.. but hurry – ClickHouse metrics will start appearing in your charts in less than a minute.
ClickHouse Monitoring Dashboard
When you open the ClickHouse App you find a predefined set of dashboards that organize more than 70 ClickHouse metrics and general server monitoring in predefined charts grouped into an intuitively organized set of monitoring dashboards:
- Overview with charts for all key ClickHouse metrics
- Operating System metrics such as CPU, memory, network, disk usage, etc.
- ClickHouse metrics
- Query: query time, query count, query memory
- Merge: merged bytes, merge count, merged rows
- MergeTree stats: table size on disk, row count and active part count
- Replication: replication part checks, failed replication part checks, lost replicated parts, distributed connection retires and distributed connection fails
- Zookeeper: A breakdown of various zookeeper errors, zookeeper wait times and leader elections
- Replicas: Replication status, Replica parts, replica queue size, replica queue inserts, replica queue merges
- System: Memory allocator stats, active HTTP and TCP connections, network errors and cache dictionary stats
- R/W Buffer: Reads/Writes, open files and file descriptor failures
- Mark Cache: Mark cache hits and misses and mark cache size
- Locks: Lock acquired read blocks, RW Lock reader wait time, Lock write wait times, Lock read wait times
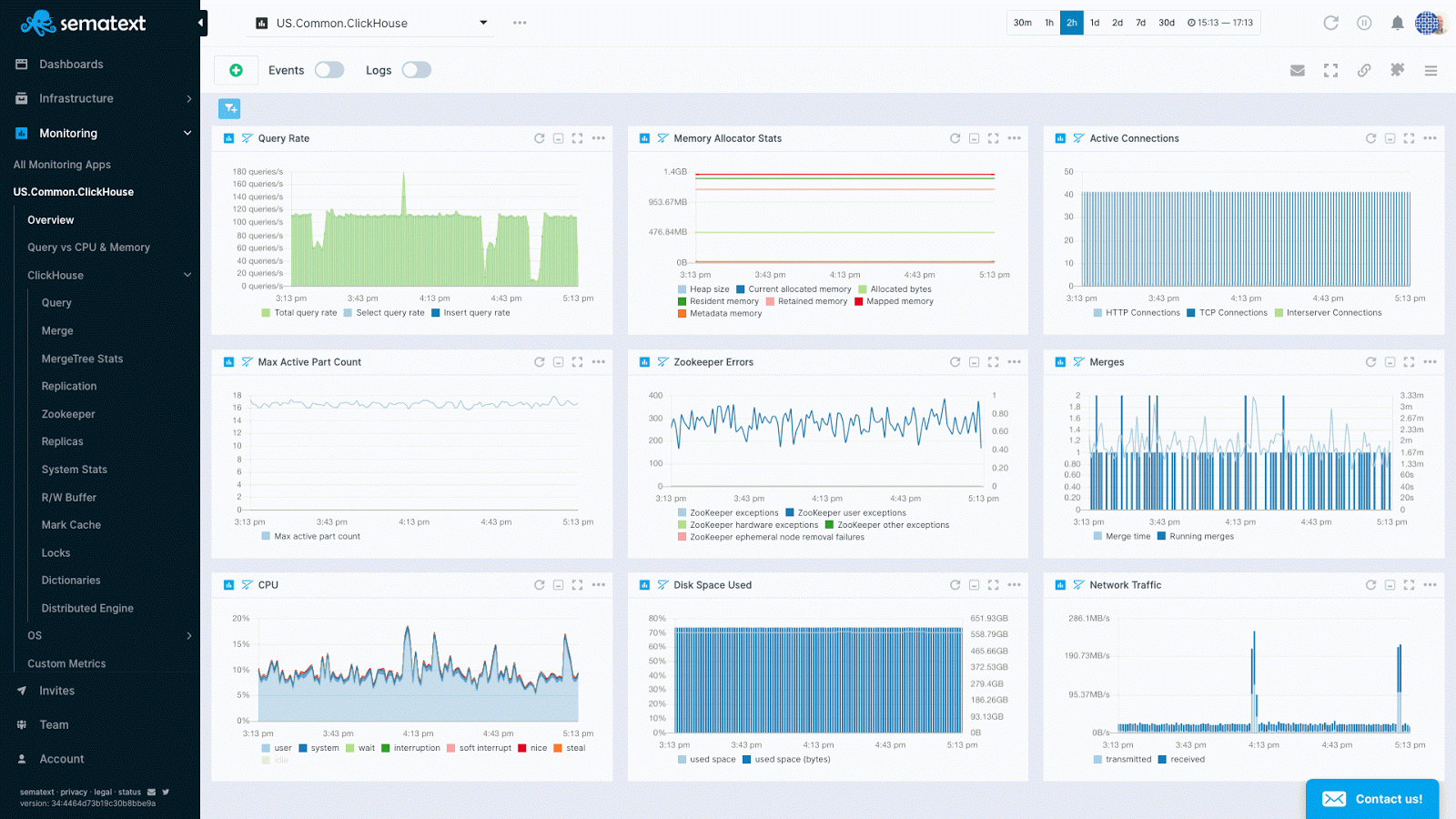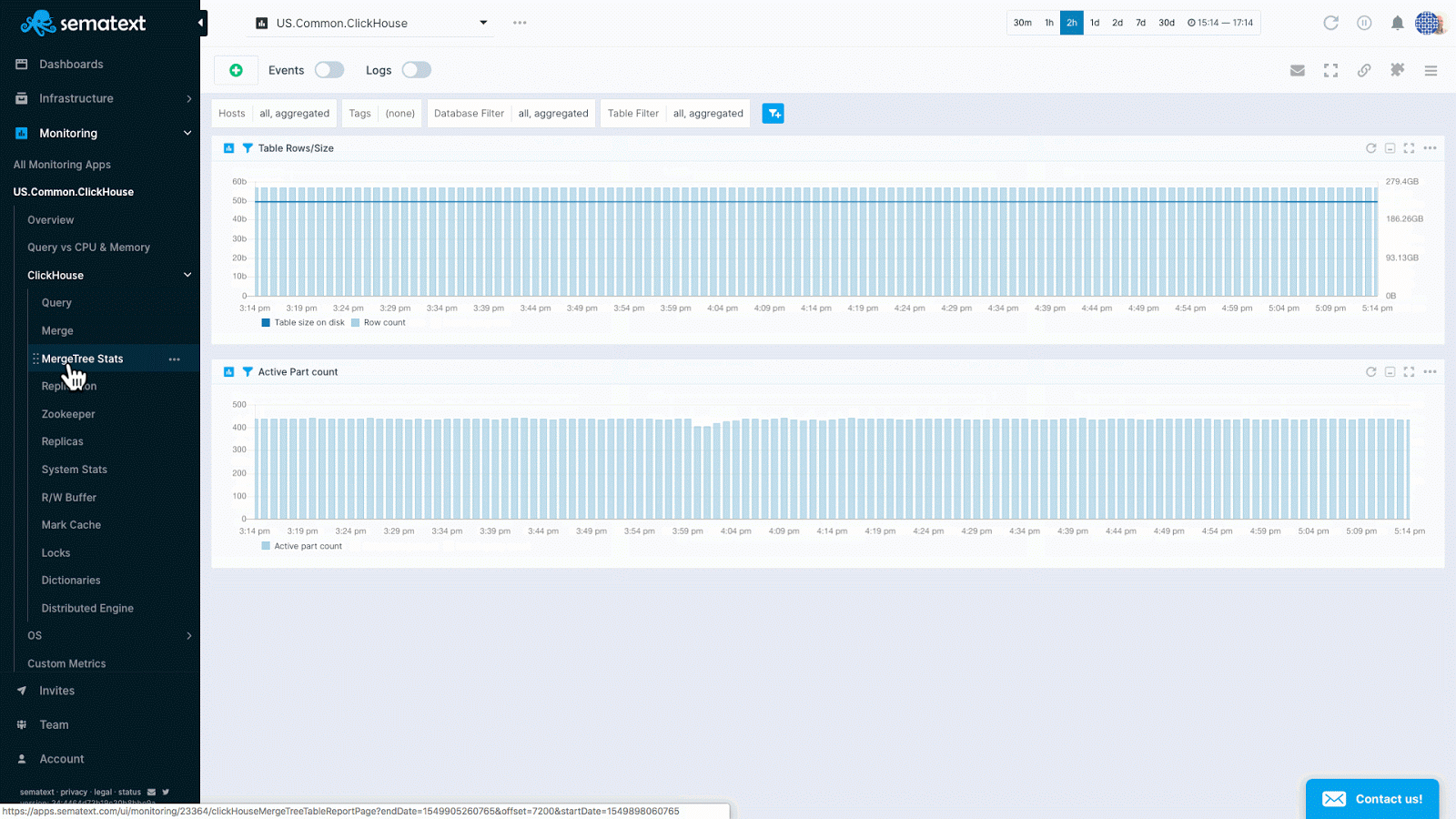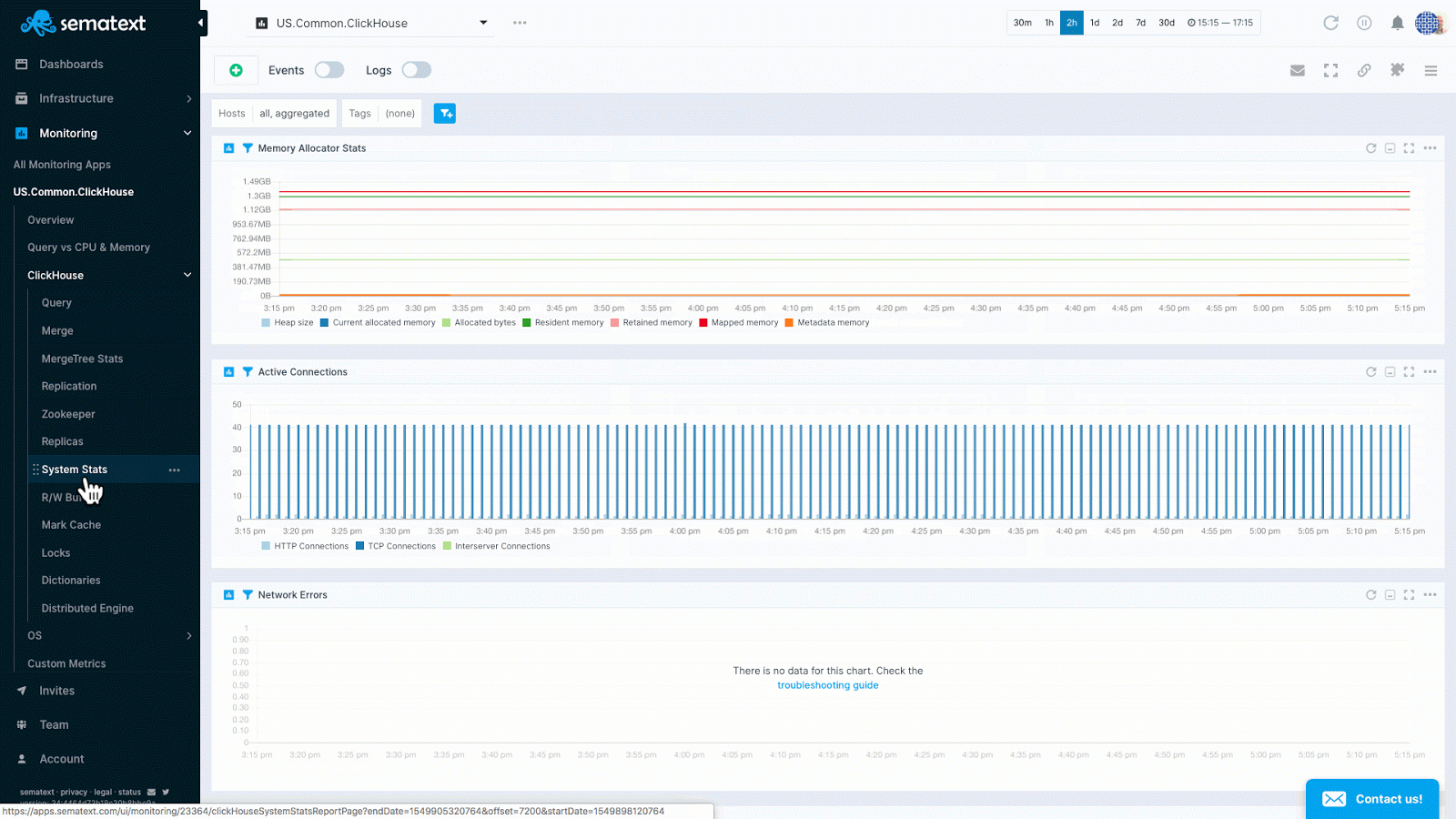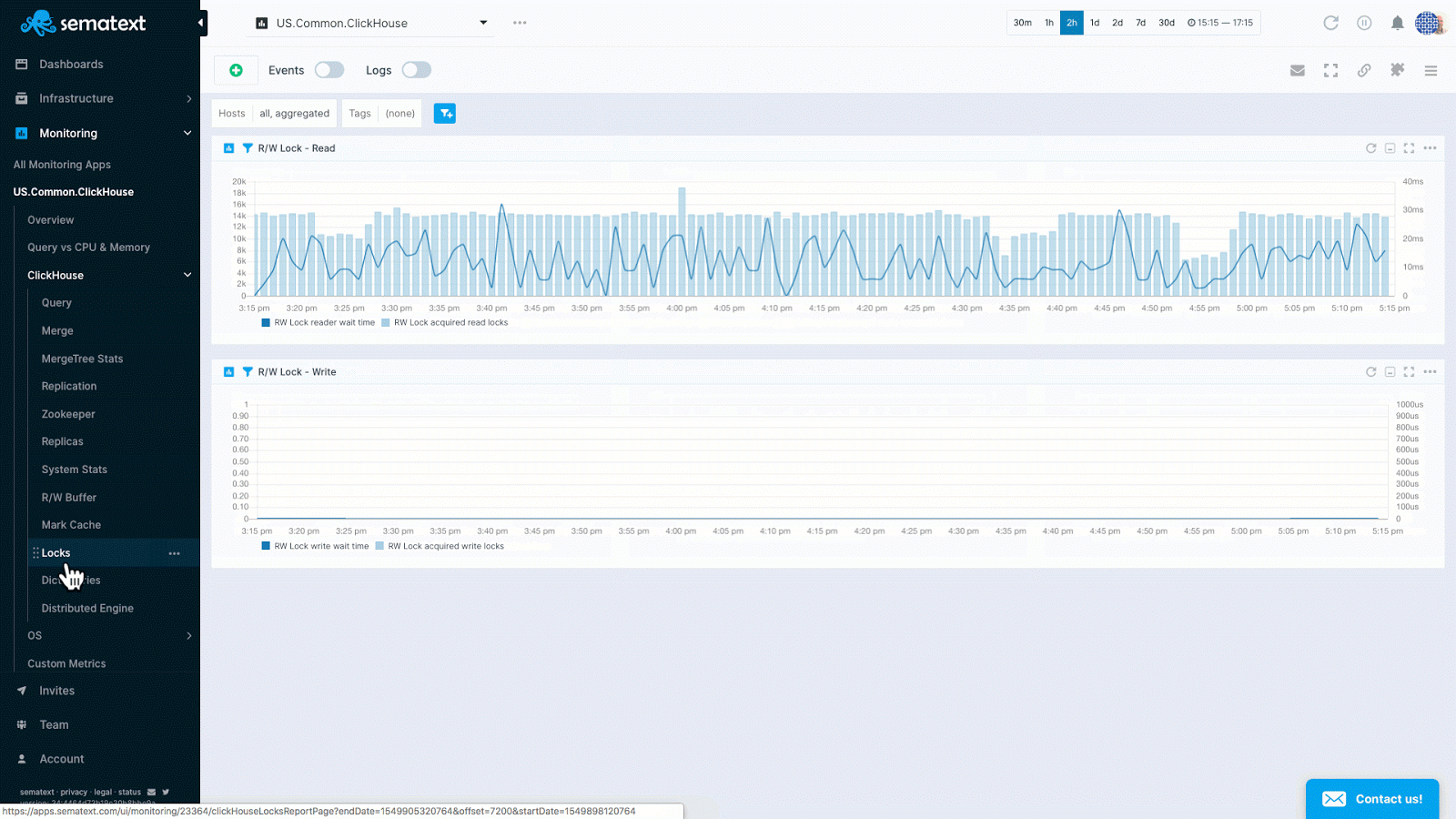
ClickHouse key metrics in Sematext Cloud
Setup ClickHouse Alerts
To save you time Sematext automatically creates a set of default alert rules such as alerts for low disk space. You can create additional alerts on any metric. Watch Alerts in Sematext Cloud for more details.
Alerting on ClickHouse Metrics
There are 3 types of alerts in Sematext:
- Heartbeat alerts, which notify you when a ClickHouse DB server is down
- Classic threshold-based alerts that notify you when a metric value crosses a pre-defined threshold
- Alerts based on statistical anomaly detection that notify you when metric values suddenly change and deviate from the baseline
Let’s see how to actually create some alert rules for ClickHouse metrics in the animation below. The Query Processing Memory chart shows a spike. We normally have a really low query memory close to 3 MB, but we see it can jump to over 80 MB. To create an alert rule on a metric we’d go to the pulldown in the top right corner of a chart and choose “Create alert”. The alert rule applies the filters from the current view and you can choose various notification options such as email or configured notification hooks (PagerDuty, Slack, VictorOps, BigPanda, OpsGenie, Pusher, generic webhooks etc.). Alerts are triggered either by anomaly detection, watching metric changes in a given time window or through the use of classic threshold-based alerts.
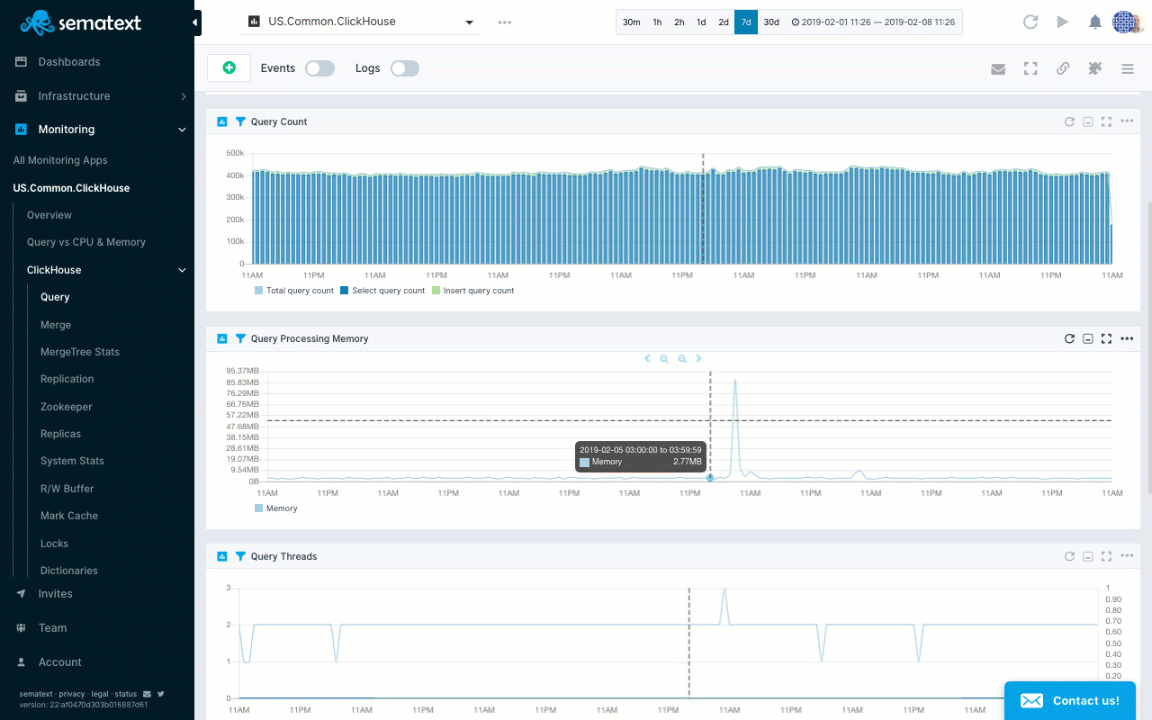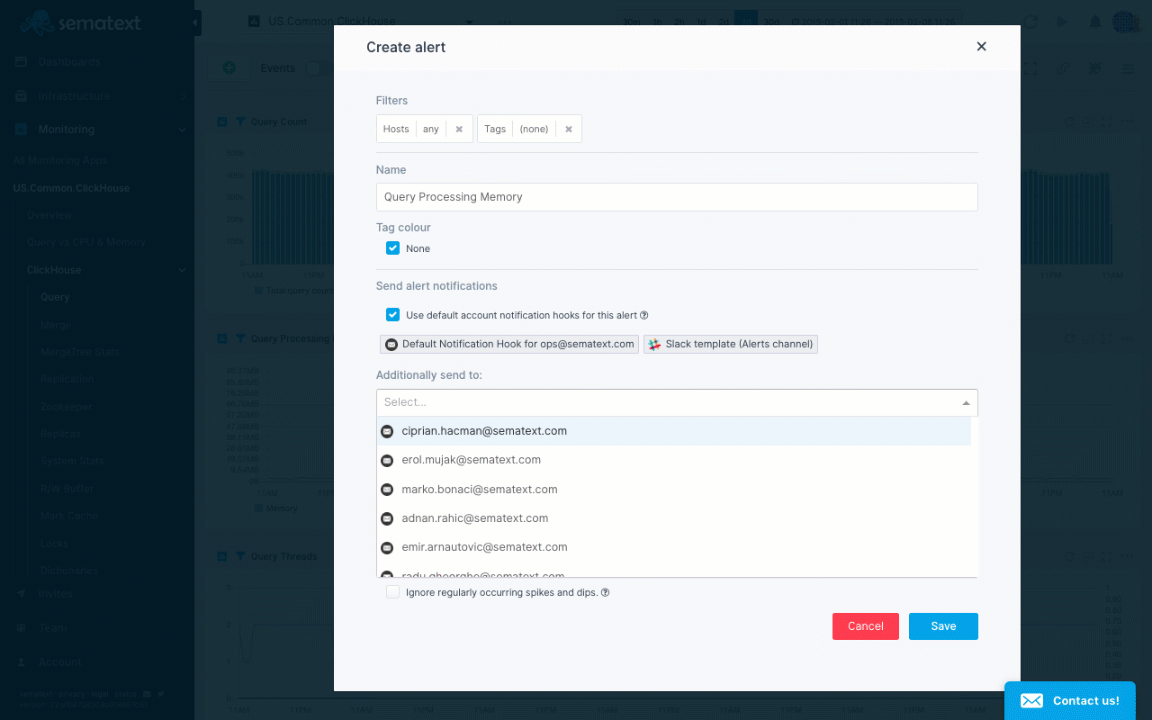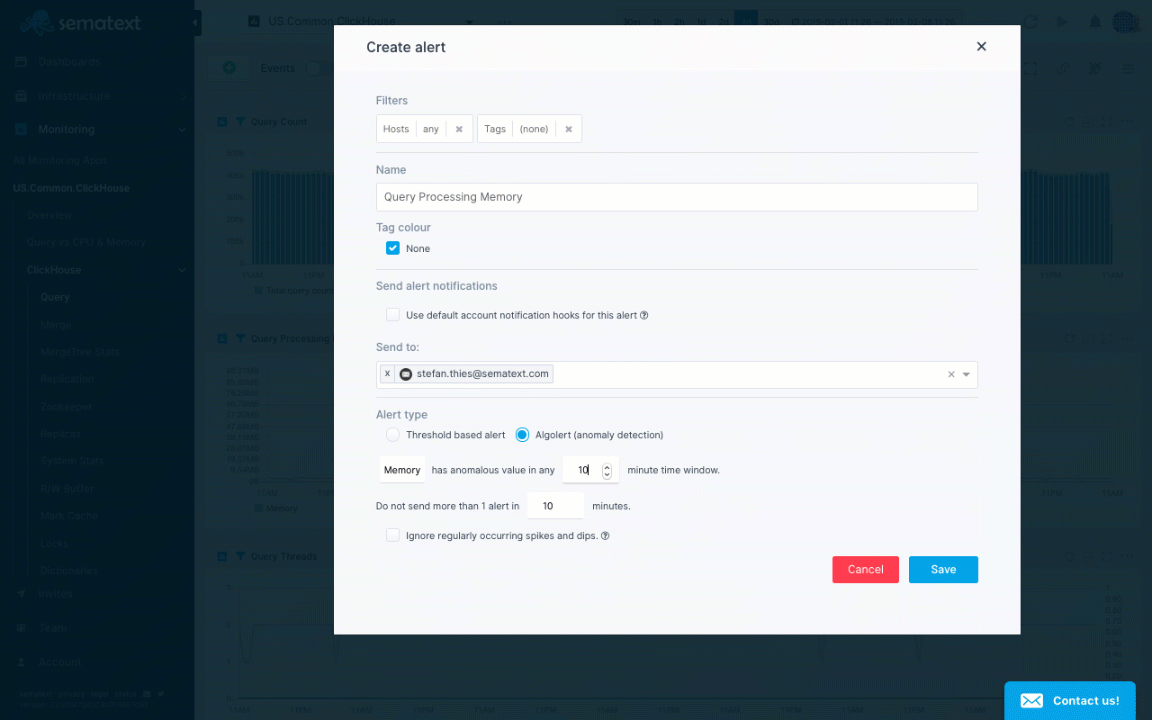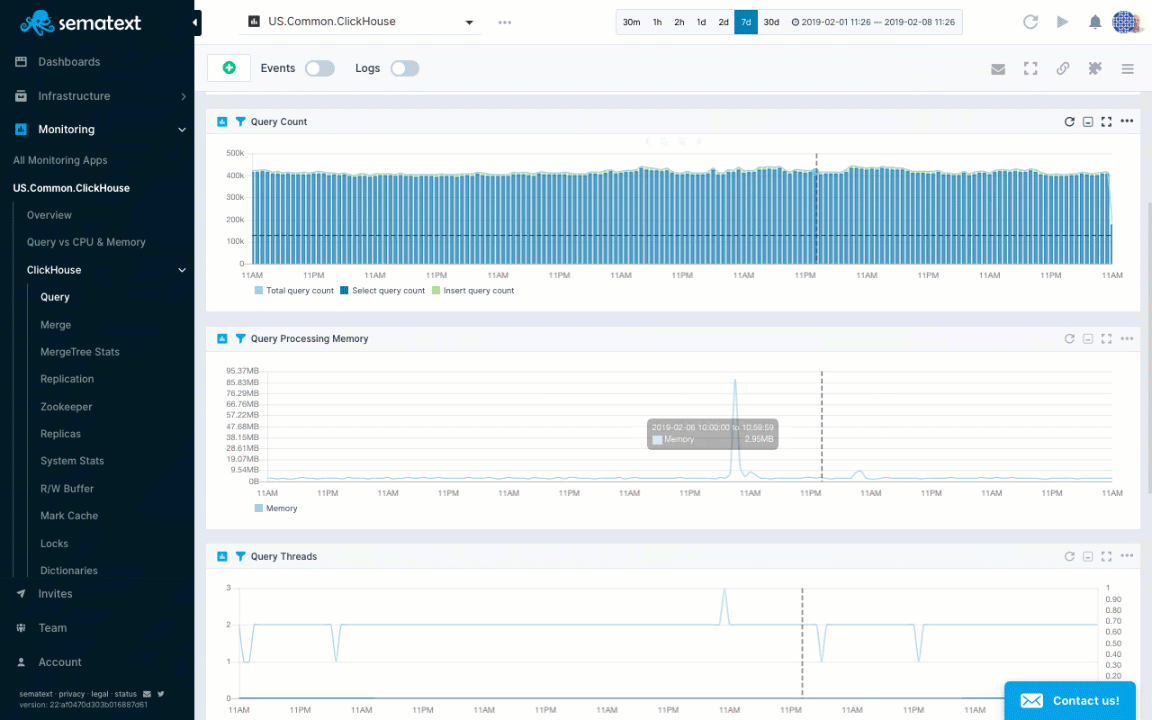
Alert creation for ClickHouse query memory
ClickHouse Logs
Shipping ClickHouse Logs
Since having logs and metrics in one platform makes troubleshooting simpler and faster let’s ship ClickHouse logs, too. You can use many log shippers, but we’ll use Logagent because it’s lightweight, easy to set up and because it can parse and structure logs out of the box. The log parser extracts timestamp, severity, and messages. For query traces, the log parser also extracts the unique query ID to group logs related to query execution.
Step 1. Create a Logs App to obtain an App token
Step 2. Install Logagent npm package
sudo npm i -g @sematext/logagent
If you don’t have Node, you can install it easily. E.g. On Debian/Ubuntu:
curl -sL https://deb.nodesource.com/setup_10.x | sudo -E bash - sudo apt-get install -y nodejs
Step 3. Install Logagent service by specifying the logs token and the path to ClickHouse log files. You can use -g ‘var/log//clickhouse*.log` to ship only logs from ClickHouse server. If you run other services, such as ZooKeeper or MySQL on the same server consider shipping all logs using -g ‘var/log//*.log’. The default settings ship all logs from /var/log/**/*.log when the -g parameter is not specified.
Logagent detects the init system and installs Systemd or Upstart service scripts. On Mac OS X it creates a Launchd service. Simply run:
sudo logagent-setup -i YOUR_LOGS_TOKEN -g ‘var/log/**/clickhouse*.log` #for EU region: #sudo logagent-setup -i LOGS_TOKEN #-u logsene-receiver.eu.sematext.com #-g ‘var/log/**/clickhouse*.log`
The setup script generates the configuration file in /etc/sematext/logagent.conf and starts Logagent as system service.
Note, if you run ClickHouse in containers, setup Logagent for container logs. Note that ClickHouse server does not log to console when running in containers. You need to mount a modified ClickHouse server config file to /etc/clickhouse-server/config.xml in the container to enable logging to console:
<logger> <console>1</console> </logger>
Log Search and Dashboards
Once you have logs in Sematext you can search them when troubleshooting, save queries you run frequently or create your individual logs dashboard.
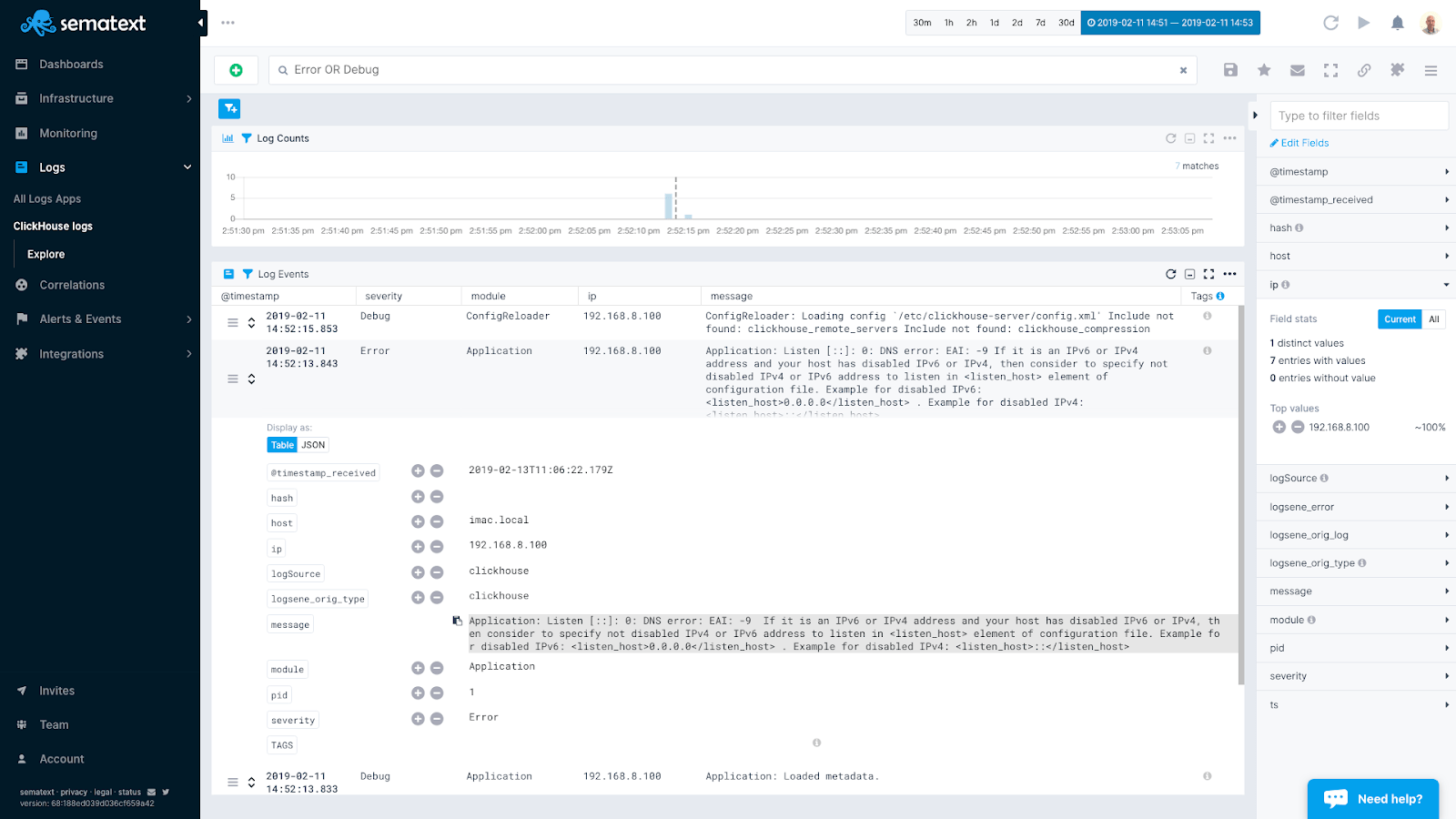
Search for ClickHouse Logs
Log Search Syntax
If you know how to search with Google, you’ll know how to search your logs in Sematext Cloud.
- Use AND, OR, NOT operators – e.g. (error OR warn) NOT exception
- Group your AND, OR, NOT clauses – e.g. message:(exception OR error OR timeout) AND severity:(error OR warn)
- Don’t like Booleans? Use + and – to include and exclude – e.g. +message:error -message:timeout -host:db1.example.com
- Use explicitly field references – e.g. message:timeout
- Need a phrase search? Use quotation marks – e.g. message:”fatal error”
When digging through logs you might find yourself running the same searches again and again. To solve this annoyance, Sematext lets you save queries so you can re-execute them quickly without having to retype them. Please watch how using logs for troubleshooting simplifies your work.
Alerting on ClickHouse Logs
To create an alert on logs we start by running a query that matches exactly those log events that we want to be alerted about. To create an alert just click to the floppy disk icon.
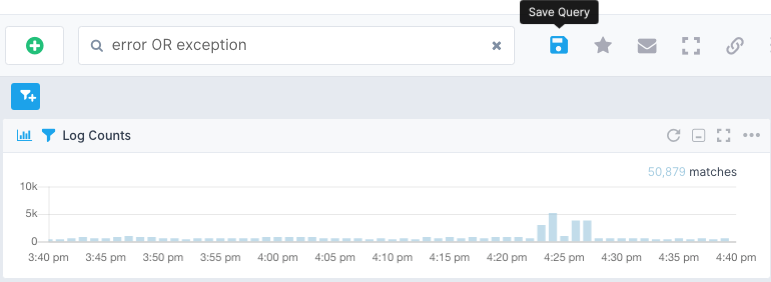
Similar to the setup of metric alert rules, we can define threshold-based or anomaly detection alerts based on the number of matching log events the alert query returns.
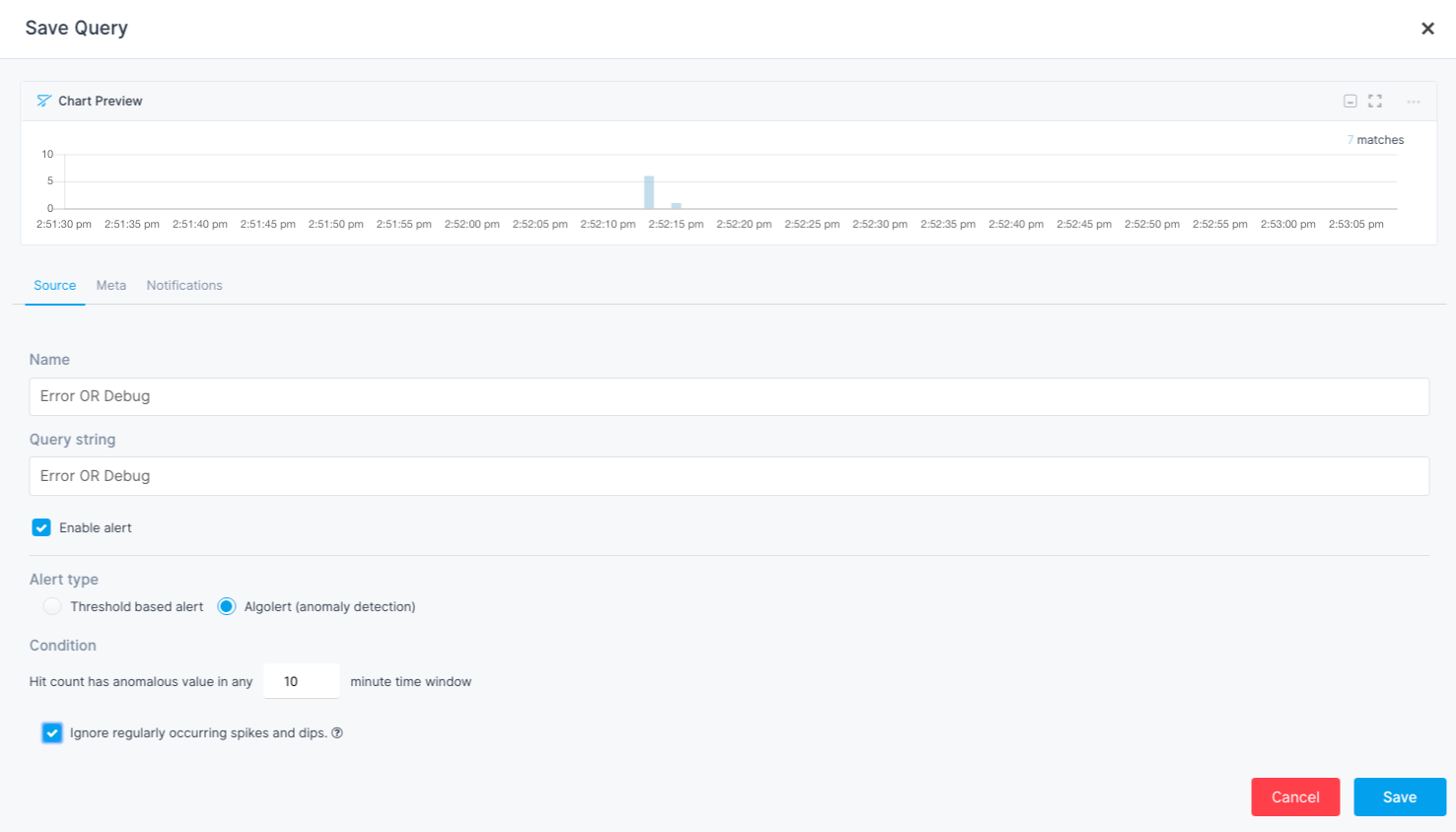
Please watch Alerts in Sematext Cloud for more details.
ClickHouse Metrics and Log Correlation
A typical troubleshooting workflow starts from detecting a slowness in metrics, then digging into logs to find the root cause of the problem. Sematext makes this really simple and fast. Your metrics and logs live under one roof. Logs are centralized, the search is fast, and powerful log search syntax is simple to use. Correlation of metrics and logs is literally a click away.
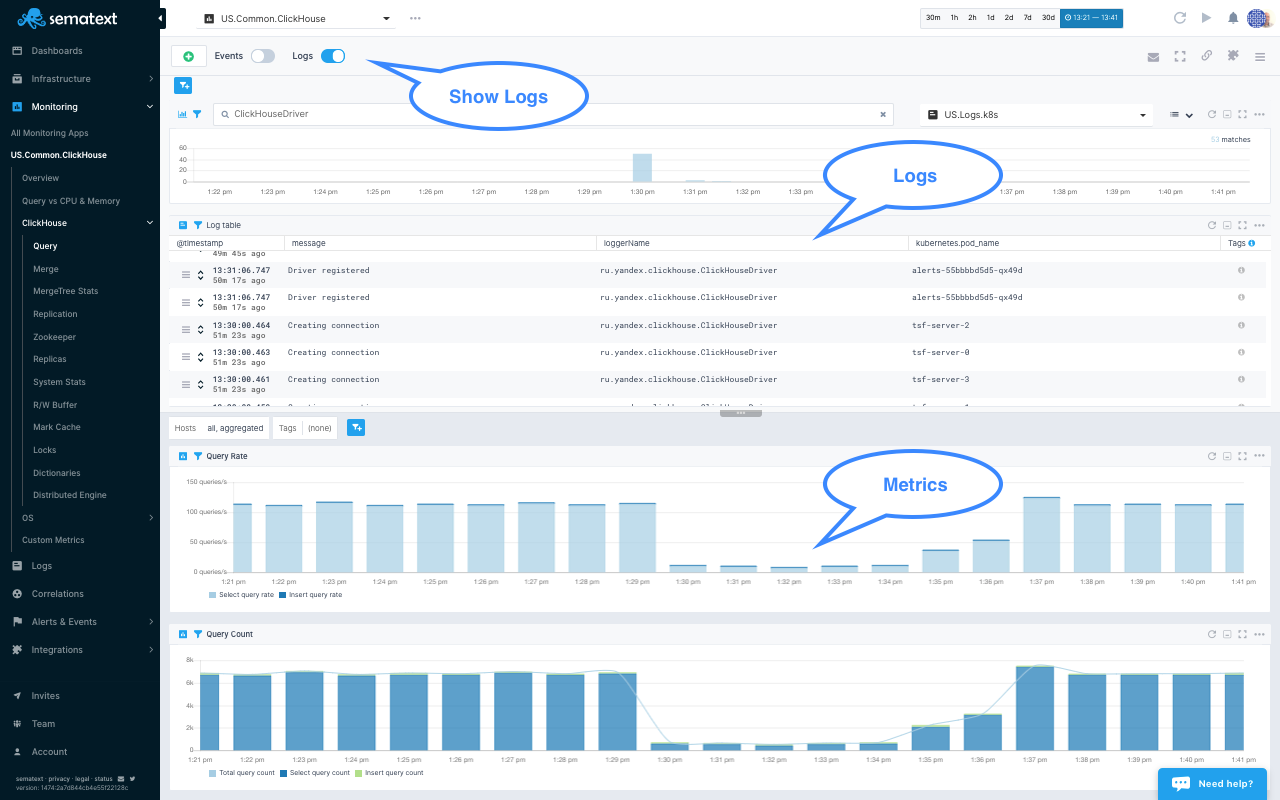
ClickHouse logs and metrics in a single view
Full Stack Observability for ClickHouse & Friends
ClickHouse’s best friends are ZooKeeper, MySQL and Kafka. While ZooKeeper is essential for ClickHouse cluster operations other integrations are optionally used to access data from external storages.
- ZooKeeper: ClickHouse relies on ZooKeeper to synchronize distributed workloads in ClickHouse clusters.
- MySQL: ClickHouse supports MySQL as an external storage engine for ClickHouse tables. In addition, MySQL can serve as an external ClickHouse dictionary for key/value lookups.
- Kafka: Apache Kafka can be used as an external storage engine for ClickHouse tables.
- Others: Several other integrations exist for external dictionaries (data lookups), such as generic ODBC interfaces or MongoDB or PostgreSQL (3rd party) integrations.
ClickHouse and Zookeeper
Because ClickHouse cluster stability depends on ZooKeeper performing well, we recommend setting up ZooKeeper monitoring and log collection for related logs. As shown in the dashboard below, this allows us to, for example, correlate high ZooKeeper wait times in ClickHouse metrics, with JVM garbage collection metrics in ZooKeeper.
Distributed system require ZooKeeper responses to be quick, so any delays caused by slow JVM garbage collection can cause performance and cluster stability issues. Having the ability to easily correlate ZooKeeper and ClickHouse metrics, like in the custom ClickHouse monitoring dashboard below, makes it easier to fix the root cause of bad performance faster.
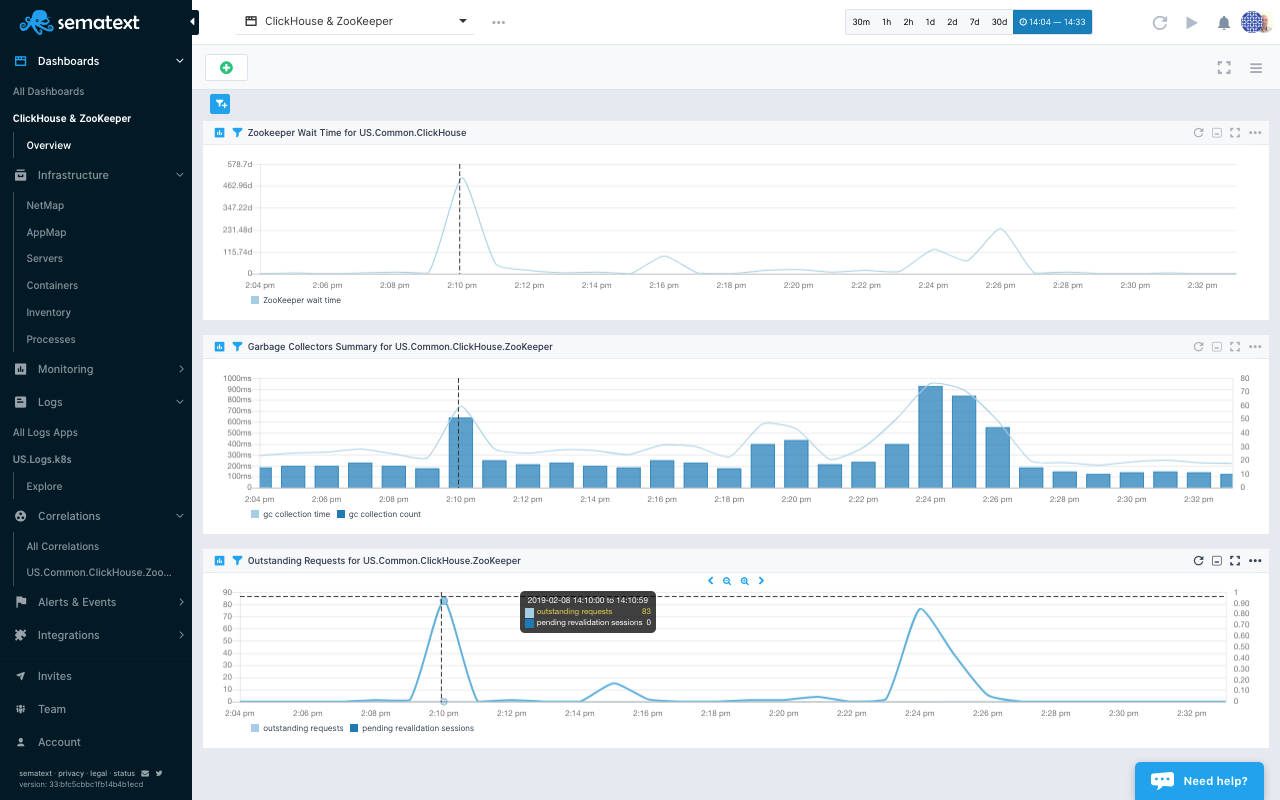
Correlation between ZooKeeper/JVM Garbage Collection and ClickHouse ZooKeeper wait time
In many cases, a performance issue can be solved by analyzing “related” metrics as well as the metric that was suspicious at the beginning of the investigation. For ad-hoc metric correlation analysis use the automatic metrics correlation to find all metrics whose patterns correlate to any base metric of your choice.
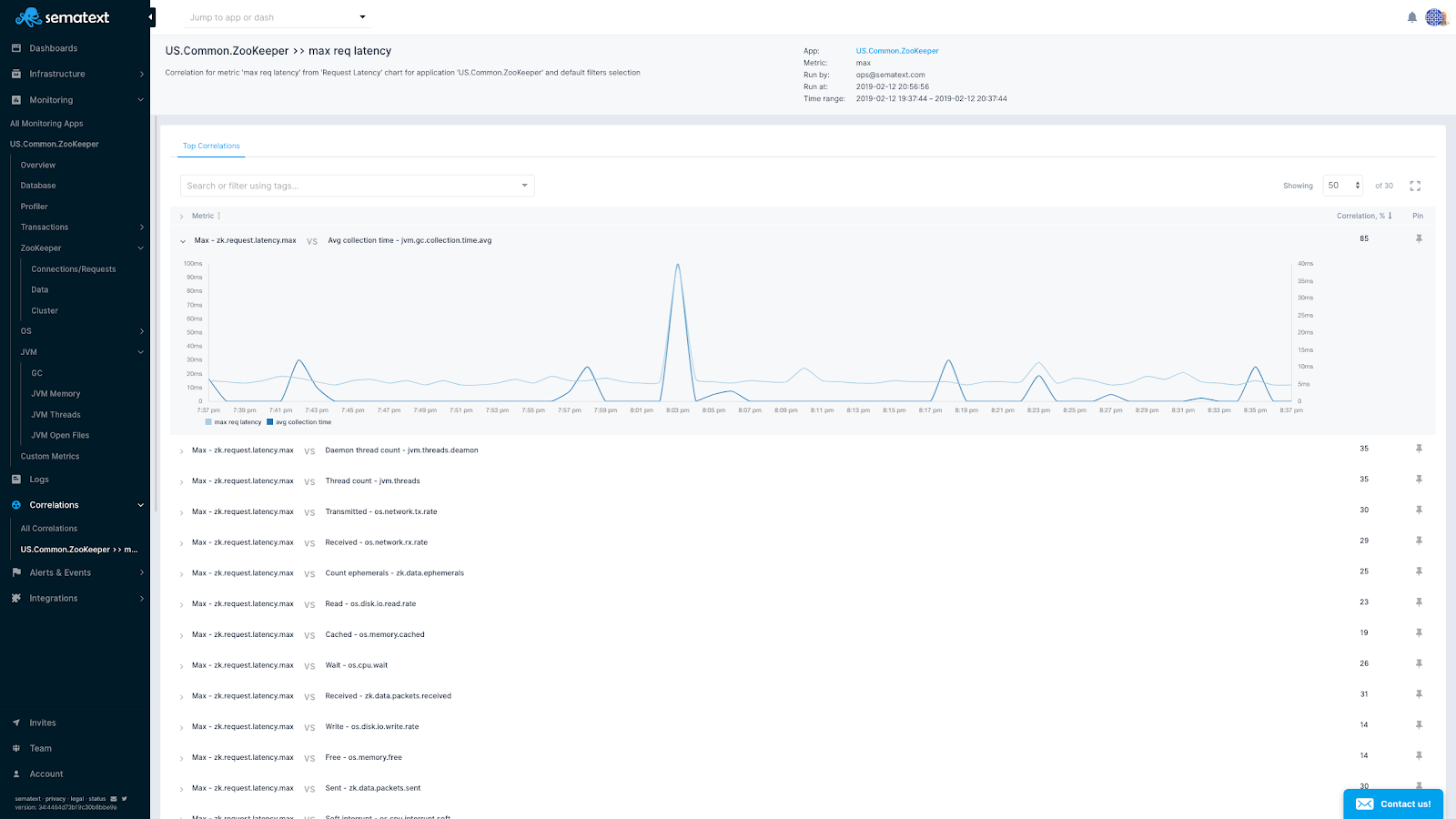
Metric correlation of garbage collection time and request latency in ZooKeeper
Integration with MySQL or Kafka
ClickHouse integrates with MySQL. MySQL can be used as an external storage engine to query data from MySQL tables in ClickHouse queries. In addition, ClickHouse supports MySQL for data lookups as an external dictionary. A dictionary is a mapping (key -> attributes) that is convenient for various types of reference lists. ClickHouse supports special functions for working with dictionaries that can be used in queries. It is easier and more efficient to use dictionaries with functions than a JOIN with reference tables. If you run MySQL, see MySQL Monitoring for more info.
Apache Kafka is only integrated as an external storage engine. Once ClickHouse faces a high latency while requesting data from external data sources such as MySQL or Kafka we have to figure out what slows down external data sources. By setting up MySQL and Kafka monitoring you can benefit from full stack observability, having your favorite ZooKeeper, MySQL, Kafka, and ClickHouse metrics together with related logs for faster troubleshooting. See Apache Kafka metrics to monitor and Monitoring Apache Kafka to learn more.
Monitor ClickHouse with Sematext
Comprehensive monitoring for ClickHouse involves identifying key metrics for both the ClickHouse cluster and ZooKeeper, collecting metrics and logs, and connecting everything in a meaningful way. In this post, we’ve shown you how to monitor ClickHouse metrics and logs in one place. We used OOTB and customized dashboards, metrics correlation, log correlation, anomaly detection, and alerts. And with other open-source integrations, like MySQL or Kafka, you can easily start monitoring ClickHouse alongside metrics, logs, and distributed request traces from all of the other technologies in your infrastructure. Get deeper visibility into ClickHouse today with a free Sematext trial.