
Over the years, natural language processing, in the world of search, went from interesting detail to a must have, especially in areas such as e-commerce. Engineers started incorporating classification, synonym generation, named entity recognition and much more into their search systems giving users better search results and in some cases leading to more revenue. In the beginning, integrating natural language processing into Solr was not easy – it required coding skills and knowledge about both Solr and the NLP library that we wanted to integrate. However, if you are using Solr released after June 2018 you’ve got a simple text tagger available out of the box. We only need to feed it with data – let’s see how we can do it.
What is Text Tagging
Text tagging is the process of adding tags or annotations to an unstructured text. Such a process can be done manually or automatically. Some of the algorithms used for automatic tagging use advanced natural language processing algorithms and machine learning, while others are quite simple and use a defined set of rules or words to match them against the unstructured text. Whichever approach one chooses text tagging can help with things such as:
- Improving the relevancy of search results by extracting keywords. This can be extremely useful for product search to reduce recall and improve the precision of queries and thus help users find what they are looking for.
- Data analysis where tagging can help understanding what the data is about.
- Text classification where we tie a document to a given, pre-defined category by extracting tags from the unstructured text.
Let’s see how one can use Solr for Text Tagging.
Solr Text Tagger
Solr Text Tagger or, more specifically, Tagger Request Handler is a naive tagger. It doesn’t do any kind of natural language processing, no machine learning is involved – it is purely based on the Lucene text analysis. The Solr Text Tagger pipeline looks as follows:
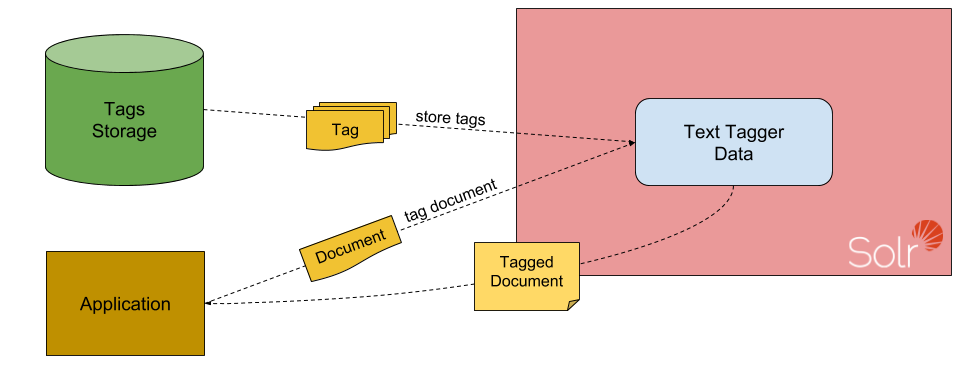
To use Solr Text Tagger we first need to feed it with data – in this case the tags. The data will be indexed in a Solr collection, just like you’d expect. Once the tags are in Solr, we can easily use the Tagger Request Handler and get the information about which tags were found in the document that we just sent for tagging. We can then easily use the received data to enrich our documents and send them to Solr for indexing.
Use Case: Product Search
Let’s assume that we have product catalogue data with each product record containing a product description field, but no other attributes. Because the description is just a blob of textone can only run full text search queries. What if we wanted to boost documents based on certain manufacturers or other named entities? To do so we need to extract that data from the description field. Assuming that we have our tags extracted we can feed Solr with that data and use Solr tagging capabilities to return data that we can add to our documents.
Now that we know the principles of how Text Tagger works and what we will use it for we can can dig into the details about the implementation.
Configuring Solr for Tagging
To be able to use Solr Text Tagger we need to properly prepare Solr. To do that we will create a new, specialized collection for holding the tags that we will use.
For the purpose of the blog post let’s assume that we are interested in the following tags:
Sony Panasonic Samsung Philips LG
All these companies are producing TVs and we have product data that includes TVs, so these manufacturers should work for us. However, we can’t just index the data into any fields as the Tagging Request Handler has its requirements or suggested settings. Let’s dig into that next.
Schema Requirements
There are two key points that Solr requires for the Tagging Request Handler to work:
- A unique key needs to be defined
- The field that we index tags to needs to be defined with a type using solr.TextField class, it needs to have solr.ConcatenateGraphFilterFactory as the last filter during indexing and not during querying, and it should have the preservePositionIncrements property set to false.
It is also recommended to have the following field settings for the field that we use for indexing tags:
- omitNorms should be set to true so that we ignore norms for that field,
- omitTermFreqAndPositions should be set to true so that we don’t have frequencies and positions for terms,
- postingsFormat should be set to FST50, so that we use highly optimized data structure to store the tags.
Creating Solr Tagging Schema
Knowing that we can now start Solr:
$ bin/solr start -c
And create the tags collection:
$ bin/solr create -c tags -shards 1 -replicationFactor 1
Of course, our tags collection will use the _default collection that is shipped out of the box with Solr. With our collection live we can easily use the Solr Schema API to create the fields that we need. We will create the tag field to be used for tagging and a tag_orig field to keep the original, stored tag that will also be analyzed so we can search on it. To do that we will use the following request:
$ curl -XPOST -H 'Content-type: application/json' 'http://localhost:8983/solr/tags/schema' -d '{
"add-field-type" : {
"name" : "tag_type",
"class" : "solr.TextField",
"postingsFormat" : "FST50",
"omitNorms" : true,
"omitTermFreqAndPositions" : true,
"indexAnalyzer" : {
"tokenizer" : {
"class" : "solr.WhitespaceTokenizerFactory"
},
"filters" : [
{
"class" : "solr.LowerCaseFilterFactory"
},
{
"class" : "solr.ConcatenateGraphFilterFactory",
"preservePositionIncrements" : false
}
]
},
"queryAnalyzer" : {
"tokenizer" : {
"class" : "solr.WhitespaceTokenizerFactory"
},
"filters" : [
{
"class" : "solr.LowerCaseFilterFactory"
}
]
}
},
"add-field" : {
"name" : "tag",
"type" : "tag_type",
"stored" : false
},
"add-field" : {
"name" : "tag_orig",
"type" : "text_general"
},
"add-copy-field" : {
"source" : "tag",
"dest" : [ "tag_orig" ]
}
}'
As you can see we used the Solr Schema API to create a tag_type field type using all the constraints and recommendations, we created two fields and used copy field to copy the contents of the tag field to the tag_orig field.
Indexing Tags
With the collection created and configured, we can easily index our tags, so that we can use them for tagging. The indexing process is no different from what we are already used to, so we just run the following command:
$ curl -XPOST -H 'Content-type: application/json' 'http://localhost:8983/solr/tags/update' -d '[
{ "tag" : "Sony" },
{ "tag" : "Panasonic" },
{ "tag" : "Samsung" },
{ "tag" : "Philips" },
{ "tag" : "LG" }
]'
Please notice that we are not providing the identifier parameter, which is our unique key – this is because the _default configuration will just generate the identifier for us which is enough for the purpose of this post.
 How to access all the new Solr features – Running Solr, Data Manipulation, Searching, Faceting, etc.
How to access all the new Solr features – Running Solr, Data Manipulation, Searching, Faceting, etc.Solr Cheat Sheet
Tagging Request Handler
Just like you, my dear reader, I can’t wait any longer to start tagging. But before we can actually run any kind of tagging requests we need to add the tagger itself, because the Tagging Request Handler is not included in the default configuration shipped with Solr. However, because we have our lovely Solr APIs we can easily add the Tagging Request Handler by using the following command:
$ curl -XPOST -H 'Content-type: application/json' 'http://localhost:8983/solr/tags/config' -d '{
"add-requesthandler" : {
"name" : "/tag",
"class" : "solr.TaggerRequestHandler",
"defaults" : {
"field" : "tag"
}
}
}'
We named our handler /tag, we used the solr.TaggerRequestHandler class, and we provided one default parameter called field that provides the field name that is used for tagging. As simple as that.
Tagging Documents
Let’s start tagging finally. Let’s assume we have the following document that we would like to send for tagging:
{
"id" : 1,
"text" : "Sony Corporation is the electronics business unit and the parent company of the Sony Group (ソニー・グループ Sonī Gurūpu), which is engaged in business through its four operating components: electronics (AV, IT & communication products, semiconductors, video games, network services and medical business), motion pictures (movies and TV shows), music (record labels and music publishing) and financial services (banking and insurance). These make Sony one of the most comprehensive entertainment companies in the world. The group consists of Sony Corporation, Sony Pictures, Sony Mobile, Sony Interactive Entertainment, Sony Music, Sony/ATV Music Publishing, Sony Financial Holdings, and others."
}
The above text is a part of Sony description on Wikipedia. However, we can’t just take it as-is and send it for tagging. The problem is that the Tagging Request Handler only works with text data, so no JSON, no XML, etc. Because of that, we first need to extract the text that we want to be tagged and send it in the request body, just like this:
$ curl -XPOST -H 'Content-type:text/plain' 'http://localhost:8983/solr/tags/tag?fl=tag_orig&wt=json&indent=true' -d 'Sony Corporation is the electronics business unit and the parent company of the Sony Group (ソニー・グループ Sonī Gurūpu), which is engaged in business through its four operating components: electronics (AV, IT & communication products, semiconductors, video games, network services and medical business), motion pictures (movies and TV shows), music (record labels and music publishing) and financial services (banking and insurance). These make Sony one of the most comprehensive entertainment companies in the world. The group consists of Sony Corporation, Sony Pictures, Sony Mobile, Sony Interactive Entertainment, Sony Music, Sony/ATV Music Publishing, Sony Financial Holdings, and others.'
The response from Solr for the above request looks as follows:
{
"responseHeader":{
"status":0,
"QTime":1},
"tagsCount":9,
"tags":[[
"startOffset",0,
"endOffset",4,
"ids",["73117cf2-57be-4965-9aa9-eada84f9dfbb"]],
[
"startOffset",80,
"endOffset",84,
"ids",["73117cf2-57be-4965-9aa9-eada84f9dfbb"]],
[
"startOffset",439,
"endOffset",443,
"ids",["73117cf2-57be-4965-9aa9-eada84f9dfbb"]],
[
"startOffset",534,
"endOffset",538,
"ids",["73117cf2-57be-4965-9aa9-eada84f9dfbb"]],
[
"startOffset",552,
"endOffset",556,
"ids",["73117cf2-57be-4965-9aa9-eada84f9dfbb"]],
[
"startOffset",567,
"endOffset",571,
"ids",["73117cf2-57be-4965-9aa9-eada84f9dfbb"]],
[
"startOffset",580,
"endOffset",584,
"ids",["73117cf2-57be-4965-9aa9-eada84f9dfbb"]],
[
"startOffset",612,
"endOffset",616,
"ids",["73117cf2-57be-4965-9aa9-eada84f9dfbb"]],
[
"startOffset",651,
"endOffset",655,
"ids",["73117cf2-57be-4965-9aa9-eada84f9dfbb"]]],
"response":{"numFound":1,"start":0,"docs":[
{
"tag_orig":["Sony"],
"id":"73117cf2-57be-4965-9aa9-eada84f9dfbb"}]
}}
As you can see, the first part of the response, the tags part, contains the start and end offset of the tagged fragment and the ids array which contains identifiers of tags that were matched against the term defined by the start and end offset. In addition to that we have the standard response section which contains our original tag along with its identifier. Having these two pieces should allow us to enrich our data by simply adding the manufacturer to our document, just like this:
{
"id" : 1,
"manufacturers" : [ "Sony" ],
"text" : "Sony Corporation is the electronics business unit and the parent company of the Sony Group (ソニー・グループ Sonī Gurūpu), which is engaged in business through its four operating components: electronics (AV, IT & communication products, semiconductors, video games, network services and medical business), motion pictures (movies and TV shows), music (record labels and music publishing) and financial services (banking and insurance). These make Sony one of the most comprehensive entertainment companies in the world. The group consists of Sony Corporation, Sony Pictures, Sony Mobile, Sony Interactive Entertainment, Sony Music, Sony/ATV Music Publishing, Sony Financial Holdings, and others."
}
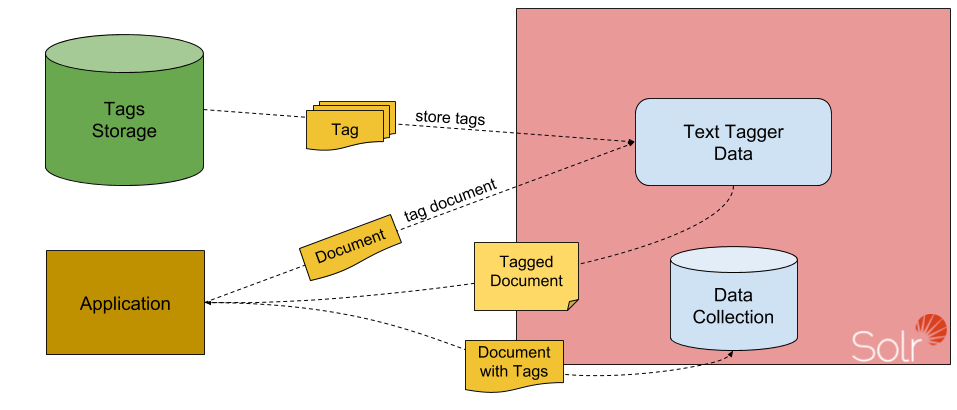
Such a document can then be indexed by Solr and used during standard queries. We can introduce boosting queries on the manufacturers’ field or use Learning to Rank to re-sort the top N documents.
Limitations and Optimizations
Of course, we could end here, but not everything is perfect when it comes to the Tagger handler in Solr.
First, we have tosend the data for tagging in an unstructured form – just plain text. This means that we can’t tag more than one document at a time, at least not easily. As Solr official documentation suggests we could concatenate the text of multiple documents with an artificially inserted separatorthat will never appear in your data, like XXXYYYXXXYYYXXXYYY and then run multiple documents in a single request. However, this is not very convenient I have to admit that, however, when dealing with large data volume we may be forced do resort to this.
Speaking of performance, the tags collection should be built of a single shard and, once you index the tags, into it you should run optimize so that the number of segments is small – ideally only one. If you have more Solr nodes than one, you can have multiple Solr replicas of the single shard in your collection, which should help to spread the load evenly.
Second, Solr tagger is single threaded. That gives us some space for performance improvements when tagging multiple documents – we can send multiple requests from different threads and parallelize the processing of our data that way. Of course, we should only do that if we have free CPU resources – it will go bad if you try to do that on already overloaded CPU. A good Solr monitoring tool will help you fine-tune your Solr tagger performance.
Conclusion
While the Solr Tagger request handler is not perfect and it doesn’t do any kind of black magic to look at the text and automagically retrieve everything that we may be interested in, it does do the job It is good for simple tagging as we have demonstrated in this post – if we know what we are looking for and we already have the tags we are looking for defined or extracted then we can easily use Solr Text Tagger Request Handler in our indexing pipeline and enrich data to add more value and provide more relevant search results to our users.
If you find this stuff exciting, please join us: we’re hiring worldwide. If you need any other help with your search infrastructure, please reach out, because we provide:
- Solr Consulting
- Production support for Solr
- Solr training classes (on-site and remote, public and private). See upcoming online classes.
- Monitoring, log centralization and tracing for not only Solr, but for other applications (e.g. Kafka, Zookeeper, Elasticsearch…), infrastructure and containers.
Good luck on improving your search relevance! Before you go, don’t forget to download your Solr Cheat Sheet:
How to access all the new Solr features – Running Solr, Data Manipulation, Searching, Faceting, etc.Solr Cheat Sheet