Application Performance Monitoring (APM)
Monitor application performance and user experience with powerful APM software. End-to-end monitoring to optimize customer satisfaction and business operations.
- Real User Monitoring
- Synthetic API and Website Monitoring
- Distributed Transaction Tracing
- Infrastructure Performance and Logs Monitoring

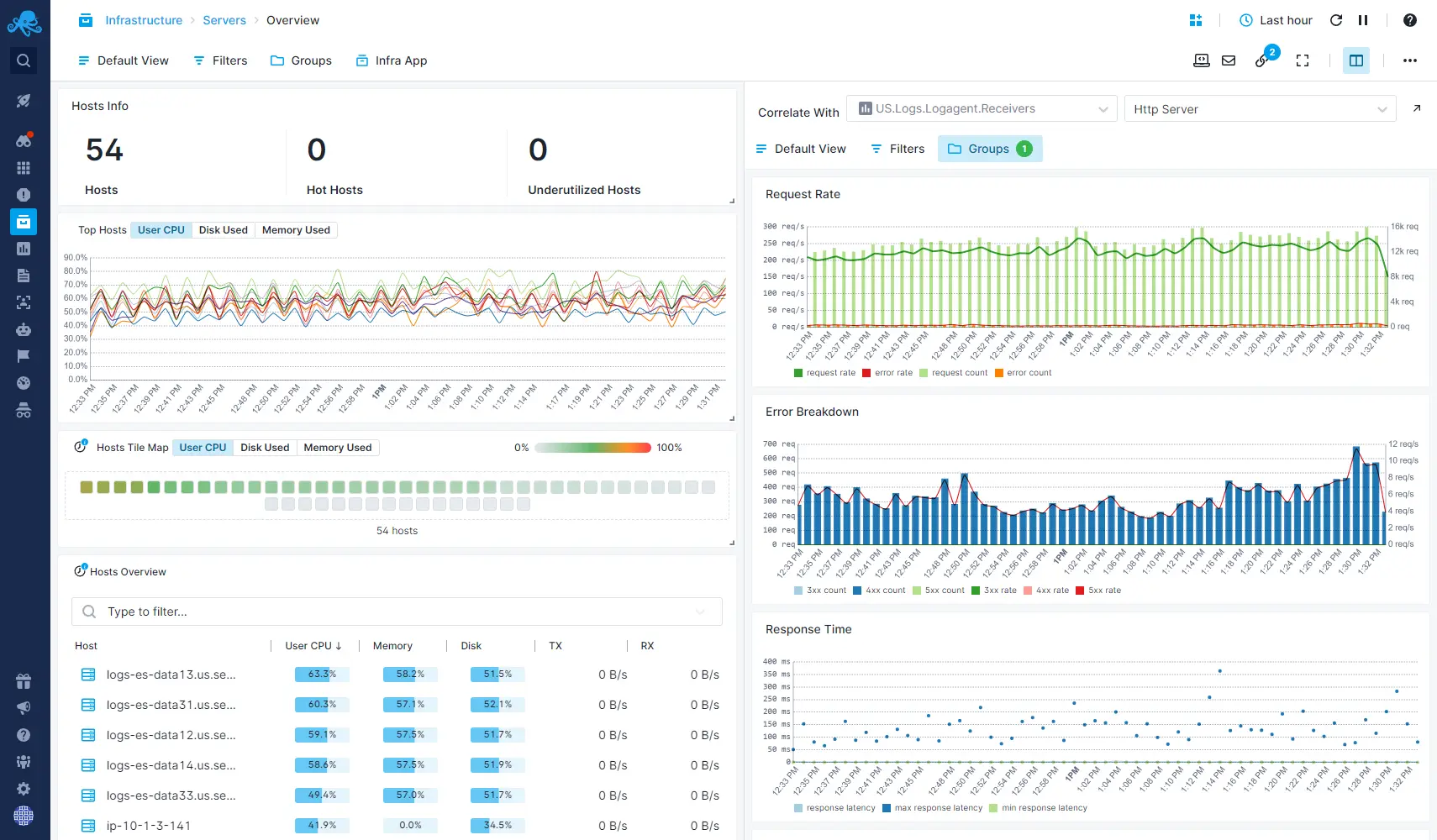
Distributed Transaction Tracing
Get full application performance visibility with Transaction Tracing by monitoring end-to-end request execution across multiple applications, tiers, servers, microservices, and processes.
- Pinpoint root causes of poor application performance with deep-dive analysis
- Find the slow and suboptimal parts of your application
- Trace requests across networks and apps all the way down to databases
- Expose slow SQL statements
Currently, only Java and Scala applications can be traced.
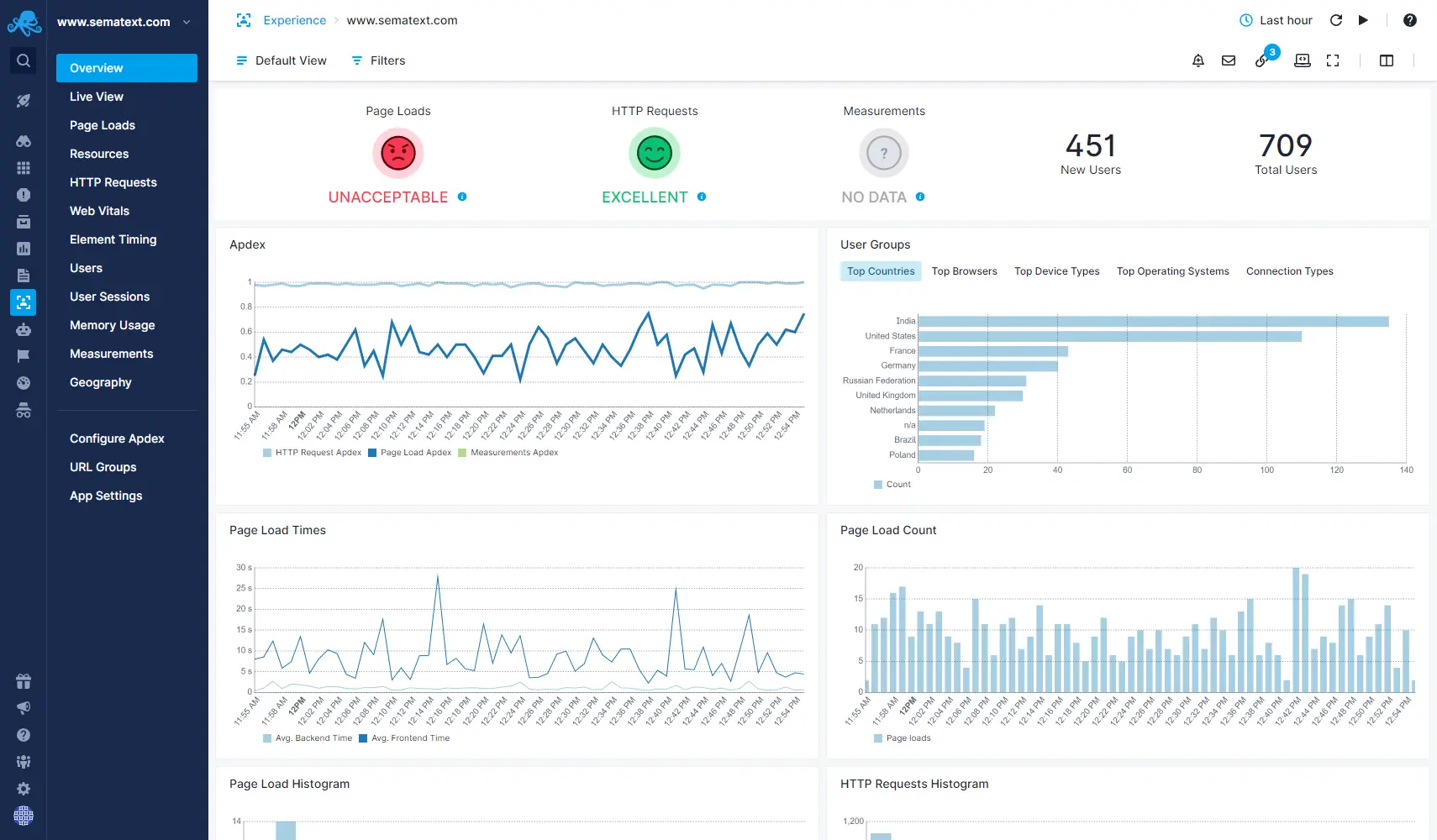
Real User Monitoring
Increase customer satisfaction by analyzing data from real user sessions. We detect anomalies and send you alerts in real time. Enhance your front-end application performance with Real User Monitoring insights.
- Get a full resource waterfall view showing assets that are slowing down your pages including detailed load time analysis
- Monitor page performance and resource usage of your single-page applications
- Monitor your Apdex Score to identify application performance bottlenecks and ensure high user satisfaction
- Be the first to know when your customers encounter website performance issues with automatic alerting
- Retrace real user journeys and see where and why they encountered performance issues such as slow page loading or errors
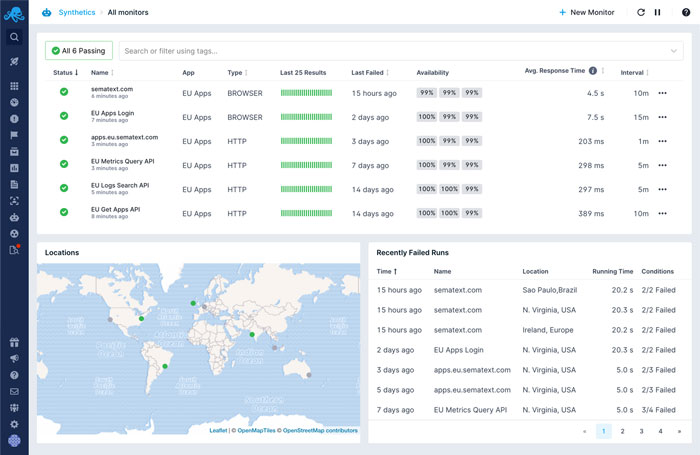
Synthetic Monitoring
Monitor the availability and performance of your web applications and APIs. Simulate business-critical user journeys. Get alerted when checks fail. Nothing to install, nothing to maintain.
- Monitor availability of your APIs and website from multiple locations
- Identify business-critical web application performance metrics
- Monitor & identify issues with third-party resources
- Waterfall chart to visualize individual resource timings and identify resources that impact page load time
- Monitor APIs & websites behind the firewall using private agent deployed in your network
- Proactive real-time alerting
- Create public status page showing the availability of your selected web services and share it with your customers
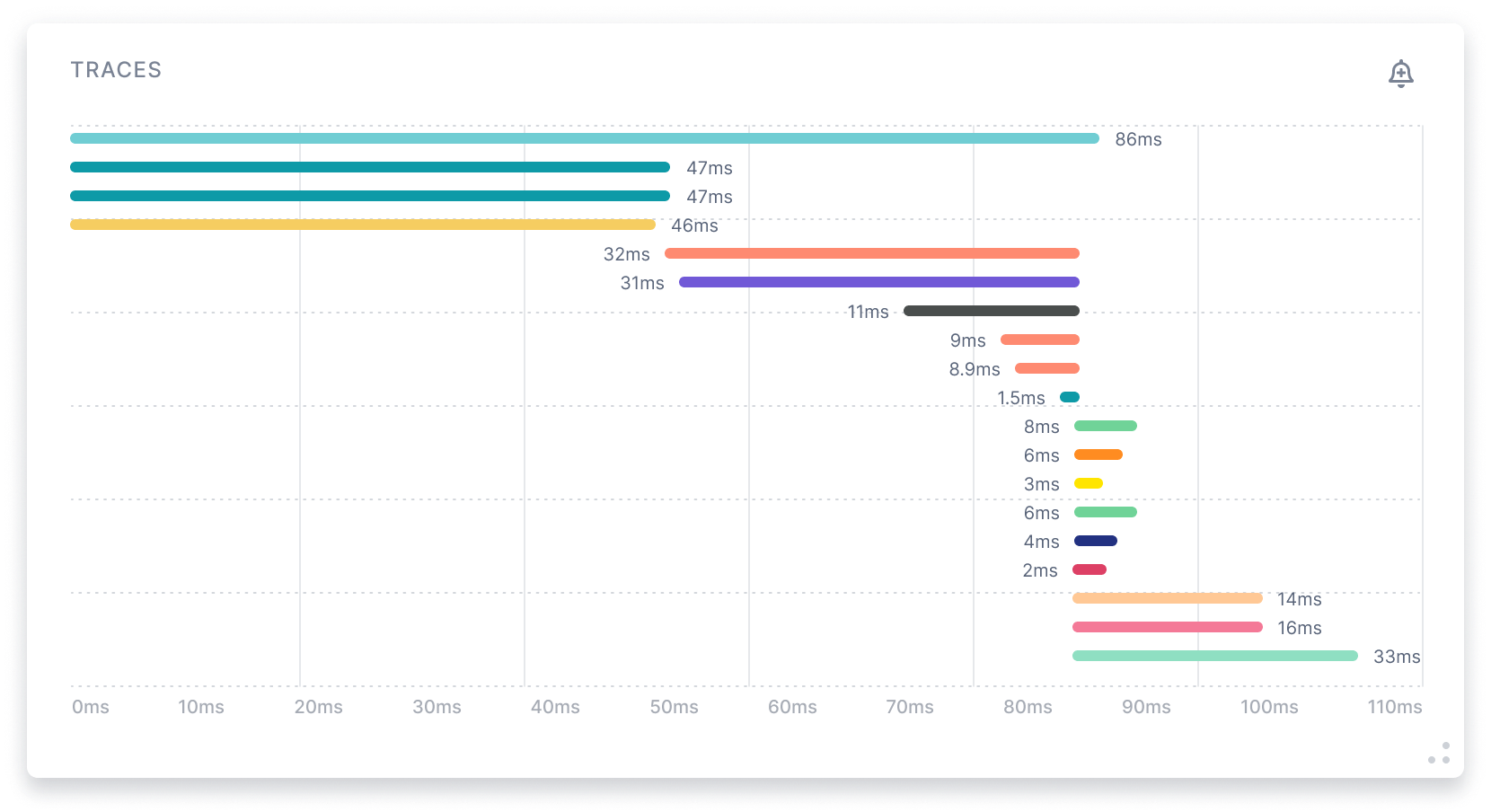
Database Operations & Slow SQL Monitoring
Sematext's application performance monitoring tool tracks database operations and slow SQL. You can detect and fix issues that affect application performance.
- Find the slowest database operation types
- View detailed performance metrics for each SQL statement
- See end-to-end HTTP transaction context, through multiple tiers, including full call trace
- Get top 10 database operations by throughput, latency, or time consumed
- Filter database operations by type
Full-Stack Observability
Application performance monitoring, infrastructure monitoring, real user monitoring, and synthetic monitoring in a single solution with the option to add log management functionality.
- Combine the power of logs, metrics, traces, and real user data for faster troubleshooting
- Troubleshoot performance issues proactively and detect potential business impact and opportunities with real-time data
- Go from metric spikes to your apps' and servers' logs in seconds
- See any application performance metrics and logs in a single unified view
- Find similar metric patterns with built-in metric correlation