Sematext Cloud
Cloud Monitoring
Comprehensive cloud monitoring tools to ensure peak performance from a single pane of glass. Get end-to-end visibility from the performance of your servers to the availability of your SaaS applications.
Free for 14 days. No credit card required.
A few words from our happy customers
Sematext is great for monitoring SolrCloud, with out of the box dashboards and easy to setup alerts

Manager – VIPConsult
Sematext Logs provides us a flexible, extensible and reliable means of monitoring all of our environments in real time.

Test Automation Lead – Healthgrades
Sematext shows one unified view for all of our Docker log, events, and metrics!

DevOps Engineer - Tozny
Monitor Private, Public, and Hybrid Cloud Services
Cloud application monitoring no matter where they run - whether it's a public cloud, private or hybrid. With Sematext Cloud, you get a unified view over server and application metrics, logs, service availability and performance for gap-free observability.
- Monitor infrastructure, database, application and site response times for faster root cause analysis.
- Centralize and drill down into server and application logs.
- Set up alerts and anomaly detection on both metrics and logs.
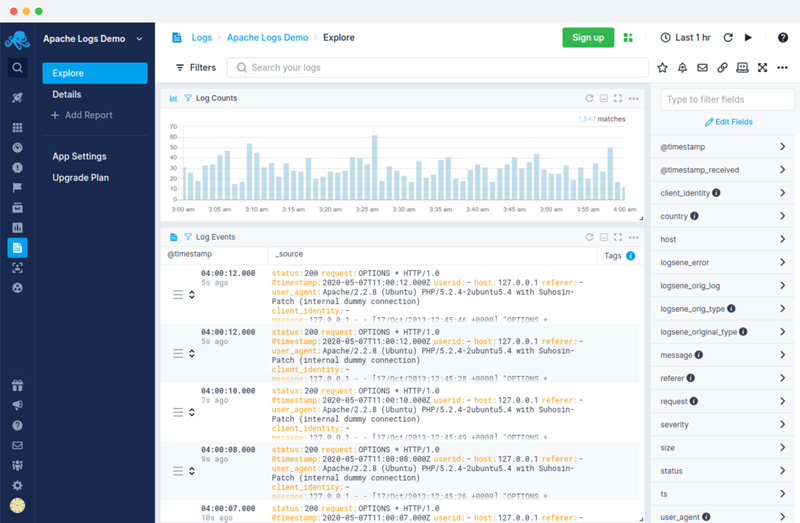
Easy Integration with Your Cloud and Container Platforms
Better cloud monitoring with a lightweight agent that has automated discovery for both services and logs. Deploy it easily anywhere from bare metal or virtual machines to Docker and Kubernetes.
- Choose what you'd like to monitor from the list of discovered services and logs.
- Explore collected data through predefined monitoring dashboards and customize them.
- Get a better view of resource usage to understand and optimize your cost centers.
- Automatically monitor new hosts, containers, applications and logs as your cloud service scales.










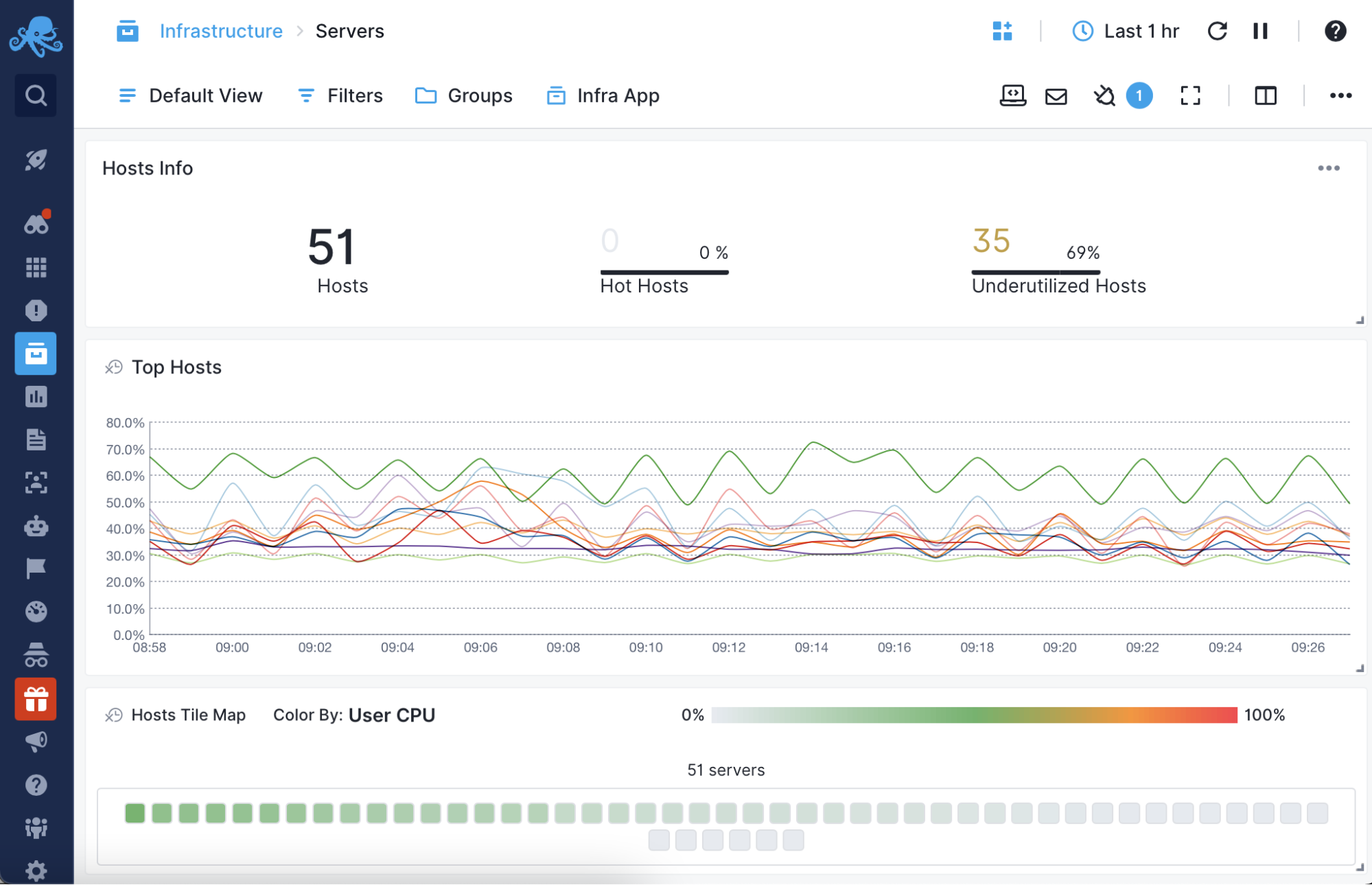
Container and Microservices Monitoring
Collect both metrics and logs out-of-the-box from Docker and pretty much all flavors of Kubernetes, managed or not.
- In elastic environments, monitor new containers via Helm or Sematext Operator.
- Get host, container and application-level metrics as well as logs.
- Pay only for what you use: our pricing model works well with short-lived containers and long-lasting ones.
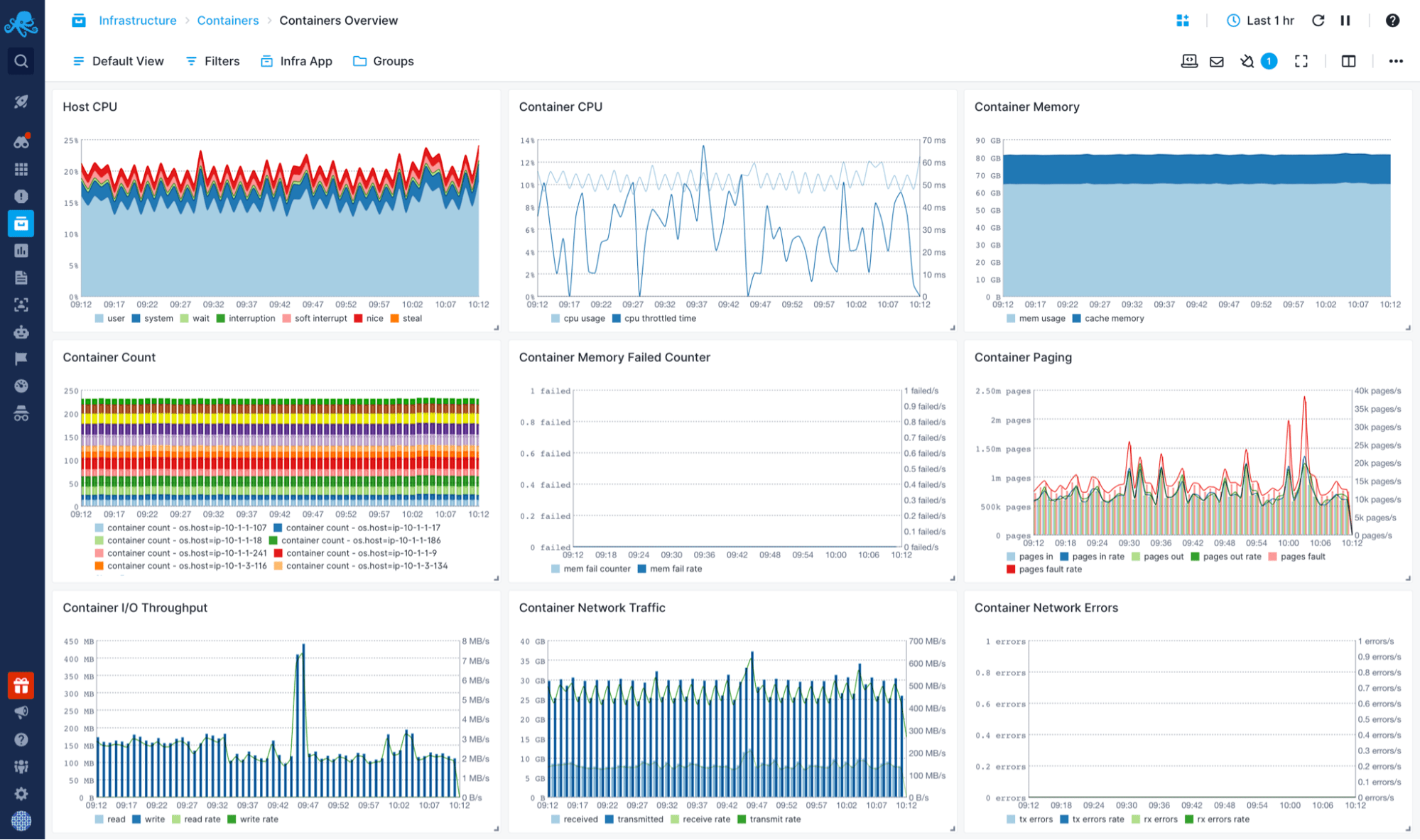
Cloud Application and Infrastructure Monitoring
Use Sematext Cloud's performance monitoring software to collect application-specific metrics. It allows you to alert on and explore them in predefined or custom dashboards.
- Monitor resource utilization, installed hardware and packages.
- Explore metrics in an aggregated view or filter them by any dimension.
- Get predefined alerts depending on the technology.
- Alert on thresholds or anomalies for any metric.
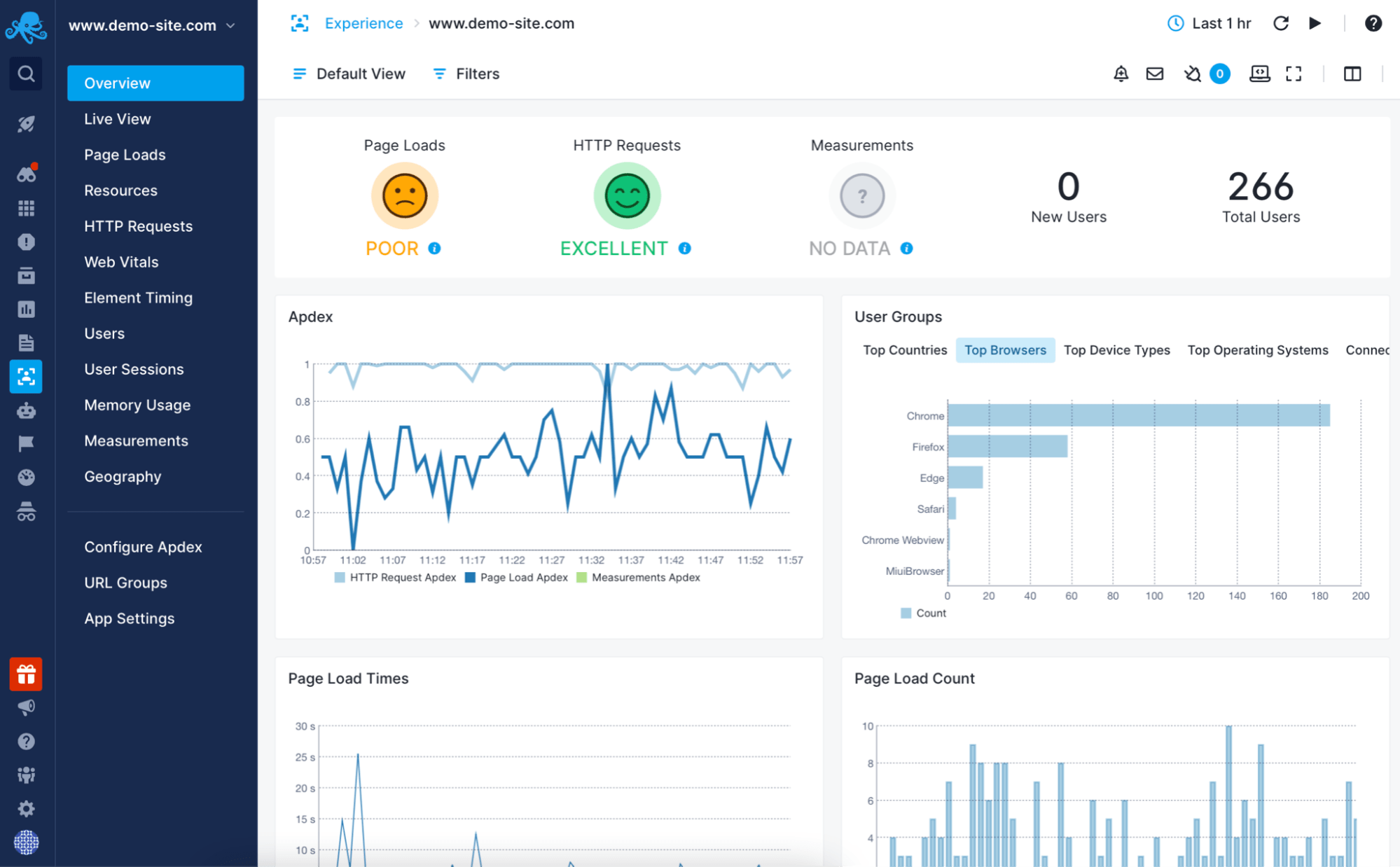
Real User Monitoring
Sematext Cloud's monitoring solution includes Sematext Experience, the option of adding real user monitoring to your monitoring stack to see website performance as users experience it.
- Get business insights from perceived performance metrics: Apdex, time to first byte, largest contentful paint and much more.
- Set up alerts on thresholds or anomalies for any of the metrics.
- Drill down into what is affecting page load times, such as specific elements, domains, browsers or countries.
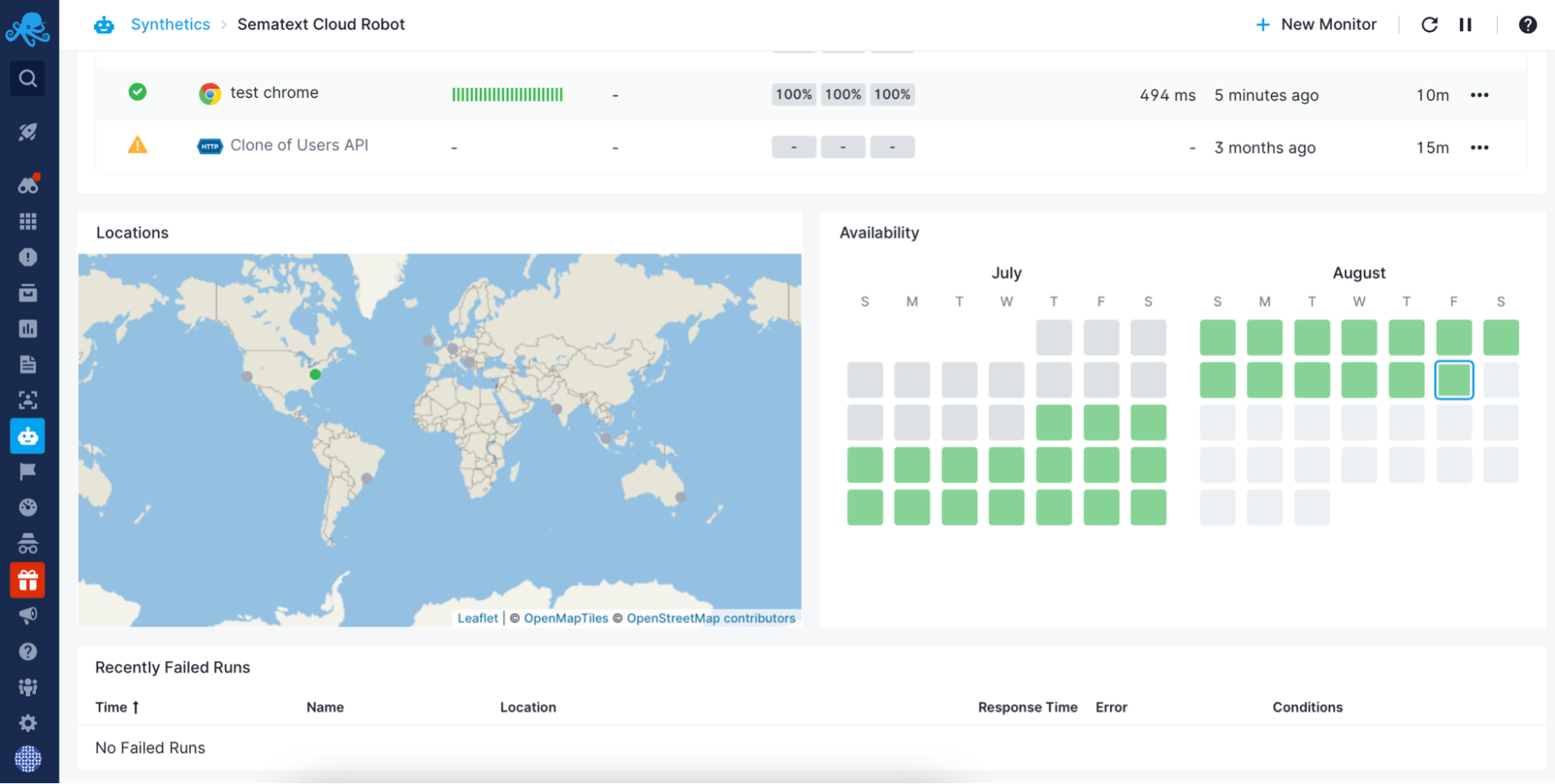
Synthetic Monitoring
Use Sematext Synthetics, Sematext Cloud's synthetic monitoring service to track the availability of your websites and HTTP APIs. Set up alerts on failures, high response times, SSL certificate expiry and other anomalies.
- Check service availability and latency from multiple locations around the globe.
- Use browser monitors to check the availability of user journeys, such as creating an account or buying a product.
- Get notified on failures and anomalies through your preferred channel: email, Slack, webhooks, etc.
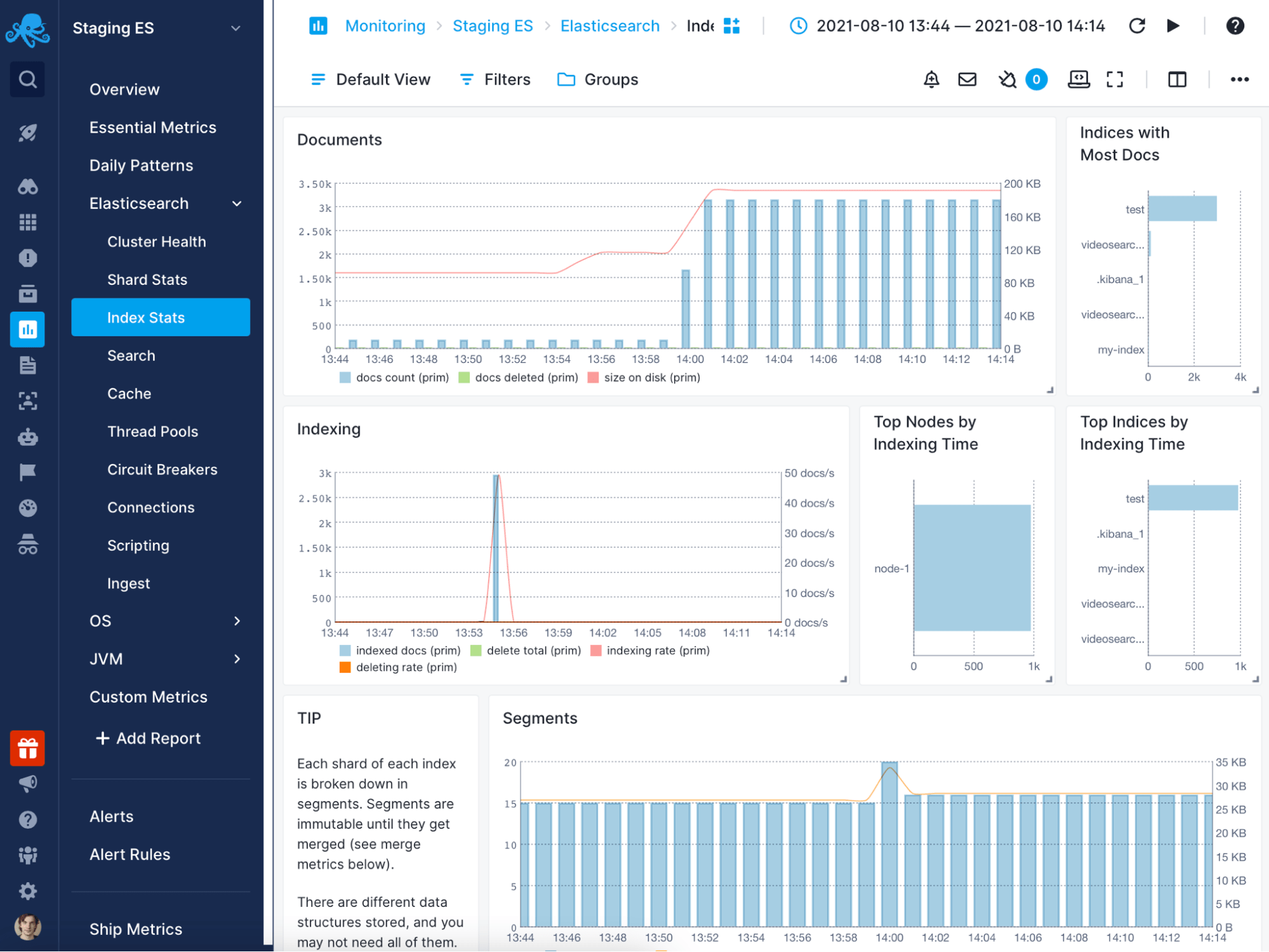
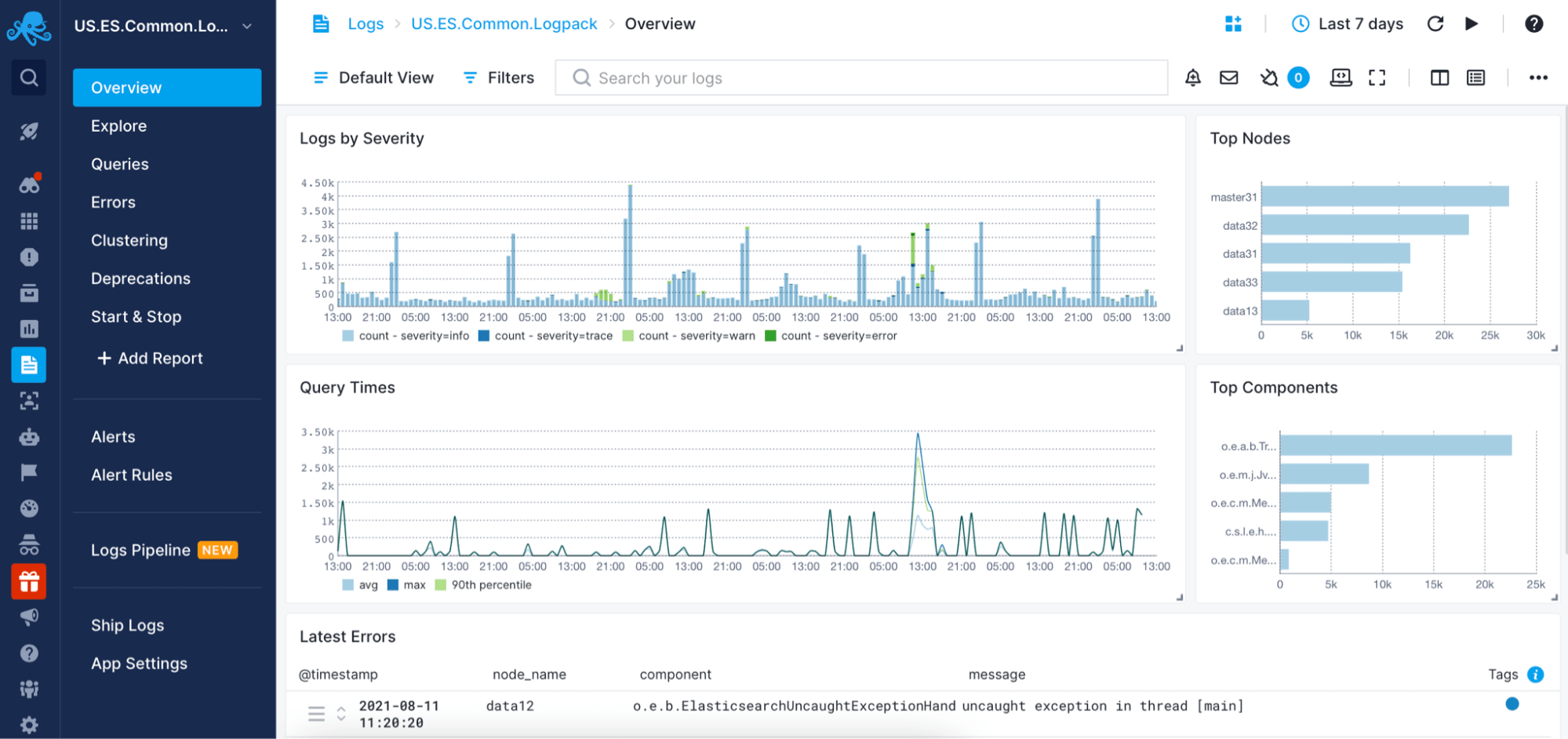
Cloud-Based Log Management and Analysis
Sematext Cloud's monitoring system features Sematexs Logs, optional log management tools for you to centralize and analyze all infrastructure and application logs for faster troubleshooting.
- Get out-of-the-box parsing and dashboard for a number of technologies, from Linux system logs to Solr and Elasticsearch and any kind of events.
- Ship any time-series data through HTTP/HTTPS or syslog protocols.
- Drill down into your logs through powerful queries and visualizations.
- Save queries and set up alerts based on metrics from your logs.
100+ OOTB Integrations
Use any of the compatible log shippers, logging libraries, platforms, and frameworks to make the most out of your logs. We provide over 100 apps and native integrations to give you out-of-the-box visibility into the technologies that power your applications.

You're in good hands.
We have customers that span from dozens of companies whose products and services you use every day to startups that you haven't heard of… yet.

Our Deliant Application Monitoring & Troubleshooting has become simplified with Sematext Cloud.
Sematext Cloud provides the best APM characteristics to visualize our organization's architecture, its state of operation, and health status in its dashboard. Troubleshooting is done fast with the help of its user logs, metrics, and traces in a single unified view. Using Application token and API keys, we gain effective control over our log access, and each log is encrypted with TLS/SSL standards. It provides real-time anomaly detection whenever there is a drastic deviation in log counts. Archiving these logs is also effortless thanks to its seamless integration with Amazon S3.