Elasticsearch is near-realtime, in the sense that when you index a document, you need to wait for the next refresh for that document to appear in a search. Refreshing is an expensive operation and that is why by default it’s made at a regular interval, instead of after each indexing operation. This interval is defined by the index.refresh_interval setting, which can go either in Elasticsearch’s configuration, or in each index’s settings. If you use both, index settings override the configuration. The default is 1s, so newly indexed documents will appear in searches after 1 second at most.
Because refreshing is expensive, one way to improve indexing throughput is by increasing refresh_interval. Less refreshing means less load, and more resources can go to the indexing threads. How does all this translate into performance? Below is what our benchmarks revealed when we looked at it through the Sematext Cloud lens.
Please tweet about Elasticsearch refresh interval vs indexing performance
Test conditions
For this benchmark, we indexed apache logs in bulks of 3000 each, on 2 threads. Those logs would go in one index, with 3 shards and 1 replica, hosted by 3 m1.small Amazon EC2 instances. The Elasticsearch version used was 0.90.0.
As indexing throughput is a priority for this test, we also made some configuration changes in this direction:
- index.store.type: mmapfs. Because memory-mapped files make better use of OS caches
- indices.memory.index_buffer_size: 30%. Increased from the default 10%. Usually, the more buffers, the better, but we don’t want to overdo it
- index.translog.flush_threshold_ops: 50000. This makes commits from the translog to the actual Lucene indices less often than the default setting of 5000
Results
First, we’ve indexed documents with the default refresh_interval of 1s. Within 30 minutes, 3.6M new documents were indexed, at an average of 2K documents per second. Here’s how indexing throughput looks like in Elasticsearch monitoring dashboard:
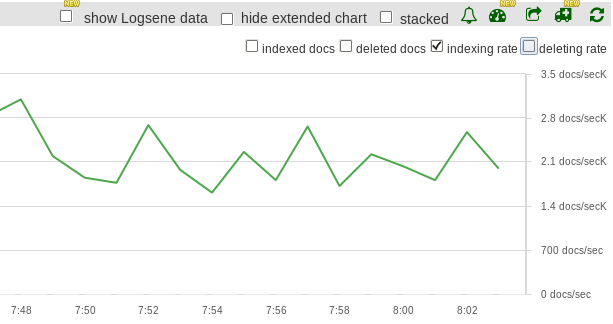
Then, refresh_interval was set to 5s. Within the same 30 minutes, 4.5M new documents were indexed at an average of 2.5K documents per second. Indexing thoughput was increased by 25%, compared to the initial setup:
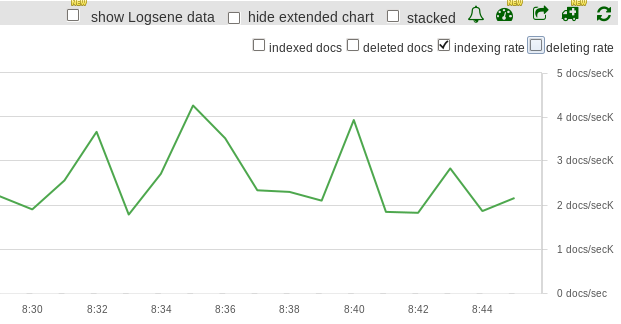
The last test was with refresh_interval set to 30s. This time 6.1M new documents were indexed, at an average of 3.4K documents per second. Indexing thoughput was increased by 70% compared to the default setting, and 25% from the previous scenario:
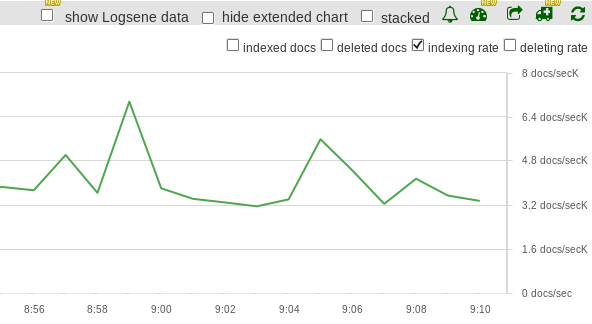
Other server metrics such as load, CPU, memory disk I/O usage, and JVM metrics like JVM Heap or Garbage Collection didn’t change significantly between runs. So configuring the refresh_interval really is a trade-off between indexing performance and how “fresh” your searches are. What settings works best for you? It depends on the requirements of your use-case. Here’s a summary of the indexing throughput values we got:
- refresh_interval: 1s – 2.0K docs/s
- refresh_interval: 5s – 2.5K docs/s
- refresh_interval: 30s – 3.4K docs/s