One of the trends we see in our Elasticsearch and Solr consulting work is that everyone is processing one kind of data stream or another. Including us, actually – we process endless streams of metrics, continuous log and even streams, high volume clickstreams, etc. Kafka is clearly the de facto messaging standard. In the data processing layer Storm used to be a big hit and, while we still encounter it, we see more and more Spark. What comes out of Spark typically ends up in Cassandra, or Elasticsearch, or HBase, or some other scalable distributed data store capable of high write rates and analytical read loads.
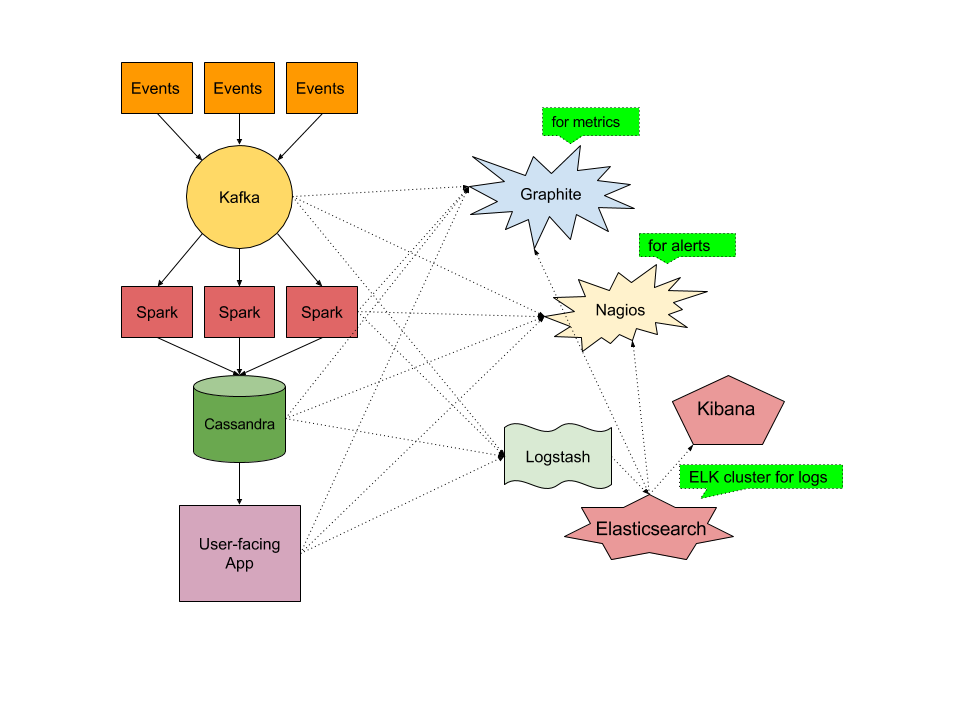
The left side of this figure shows a typical data processing pipeline, and while this is the core of a lot of modern data processing applications, there are often additional pieces of technology involved – you may have Nginx or Apache exposing REST APIs, perhaps Redis for caching, and maybe MySQL for storing information about users of your system.
Once you put an application like this in production, you better keep an eye on it – there are lots of moving pieces and if any one of them isn’t working well you may start getting angry emails from unhappy users or worse – losing customers.
Imagine you had to use multiple different tools, open-source or commercial, to monitor your full stack, and perhaps an additional tool (ELK or Splunk or …) to handle your logs (you don’t just write them to local FS, compress, and rotate, do you?) Yuck! But that is what that whole right side of the above figure is about. Each of the tools on that right side is different – they are different open-source projects with different authors, have different versions, are possibly written in different languages, are released on different cycles, are using different deployment and configuration mechanism, etc. There are also a number of arrows there. Some carry metrics to Graphite (or Ganglia or …), others connect to Nagios which provides alerting, while another set of arrows represent log shipping to ELK stack. One could then further ask – well, what/who monitors your ELK cluster then?!? (don’t say Marvel, because then the question is who watches Marvel’s own ES cluster and we’ll get stack overflow!) That’s another set of arrows going from the Elasticsearch object. This is a common picture. We’ve all seen similar setups!
Our goal with SPM and Logsene is to simplify this picture and thus the lives of DevOps, Ops, and Engineers who need to manage deployments like this stream processing pipeline. We do that by providing a monitoring and log management solution that can handle all these technologies really well. Those multiple tools, multiple types of UIs, multiple logins….. they are a bit of a nightmare or at least a not very efficient setup. We don’t want that. We want this:
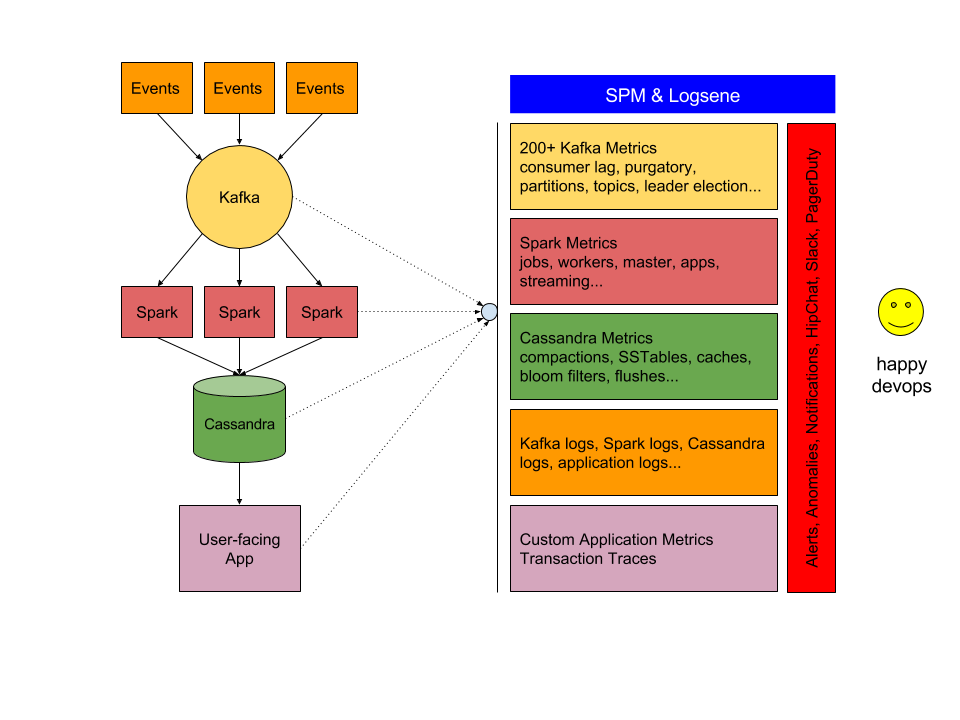
Once you have something like SPM & Logsene in place you can see your complete application stack, all tiers from frontend to backend, in a single pane of glass. Nirvana… almost, because what comes after monitoring? Alerting, Anomaly Detection, notifications via email, HipChat, Slack, PageDuty, WebHooks, etc. The reality of the DevOps life is that we can’t just watch pretty, colourful, real-time charts – we also need to set up and handle various alerts. But in case of SPM & Logsene, at least this is all in one place – you don’t need to fiddle with Nagios or some other alerting tool that needs to be integrated with the rest of the toolchain.
So there you have it. If you like what we described here, try SPM and/or Logsene – simply sign up here – there’s no commitment and no credit card required. Small startups, startups with no or very little outside investment money, non-profit and educational institutions get special pricing – just get in touch with us. If you’d like to help us make SPM and Logsene even better, we are hiring!