Containers
Monitor Docker and containerd containers, container orchestration systems like Swarm and Nomad, or cloud container orchestration services EKS, ECS, AKS, GKE with Sematext by installing Sematext Agent and using our interface that shows everything in one simple screen.
Create a Sematext Monitoring App¶
Go to the All Apps page by clicking the Octi icon in the top-left corner of the main navigation menu, or click any of the reports listed under the Infrastructure Monitoring section. From there, select Create App and choose Infrastructure Monitoring to create your Infra App. Give it a name, select plan and click 'Create App'.
During the Infra App creation process, you will get a screen displaying Sematext Agent installation instructions for various supported environments. You can install the agent during the Infra App creation process by following the Container instructions during environment selection.
Check also:
See Container data in Sematext Monitoring¶
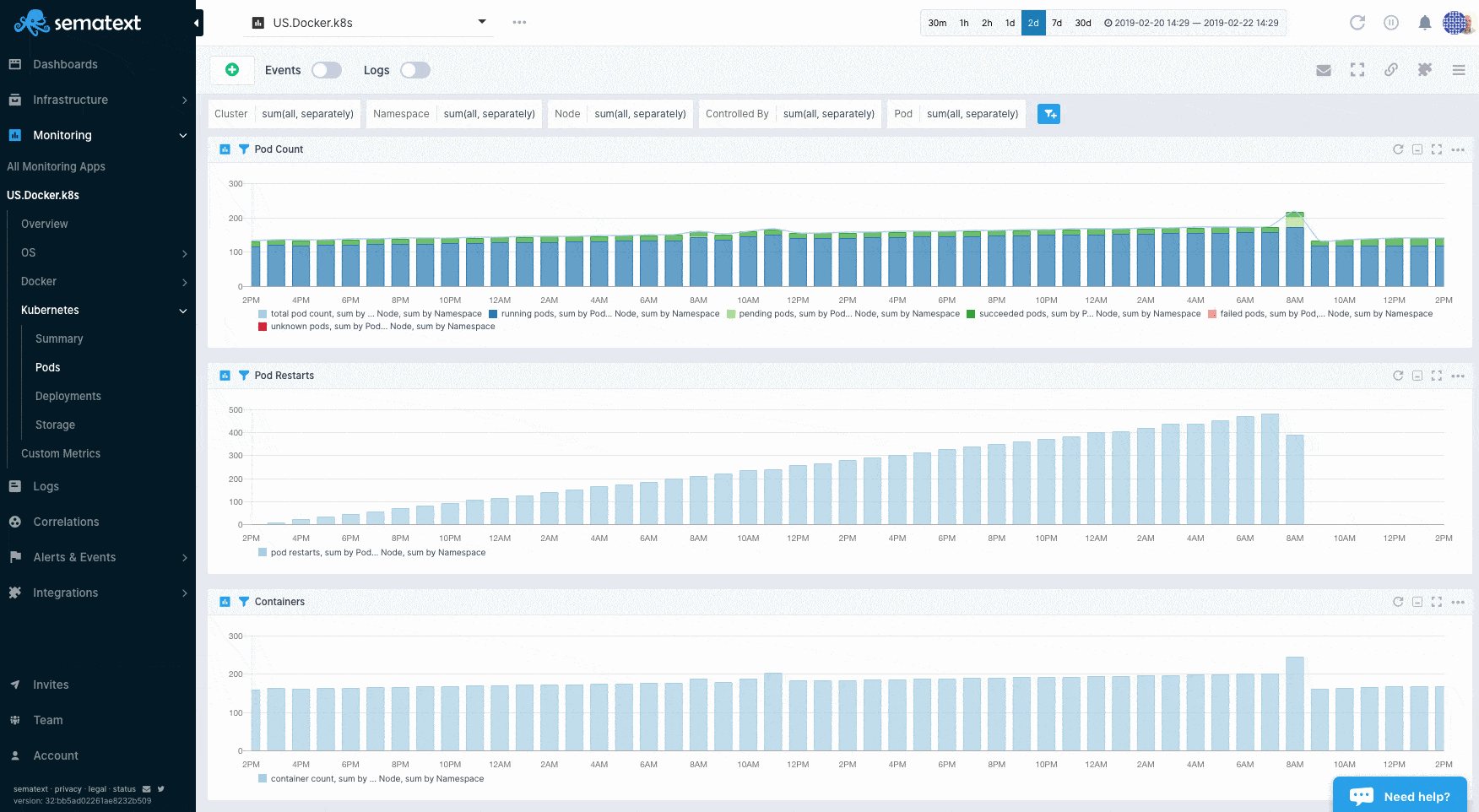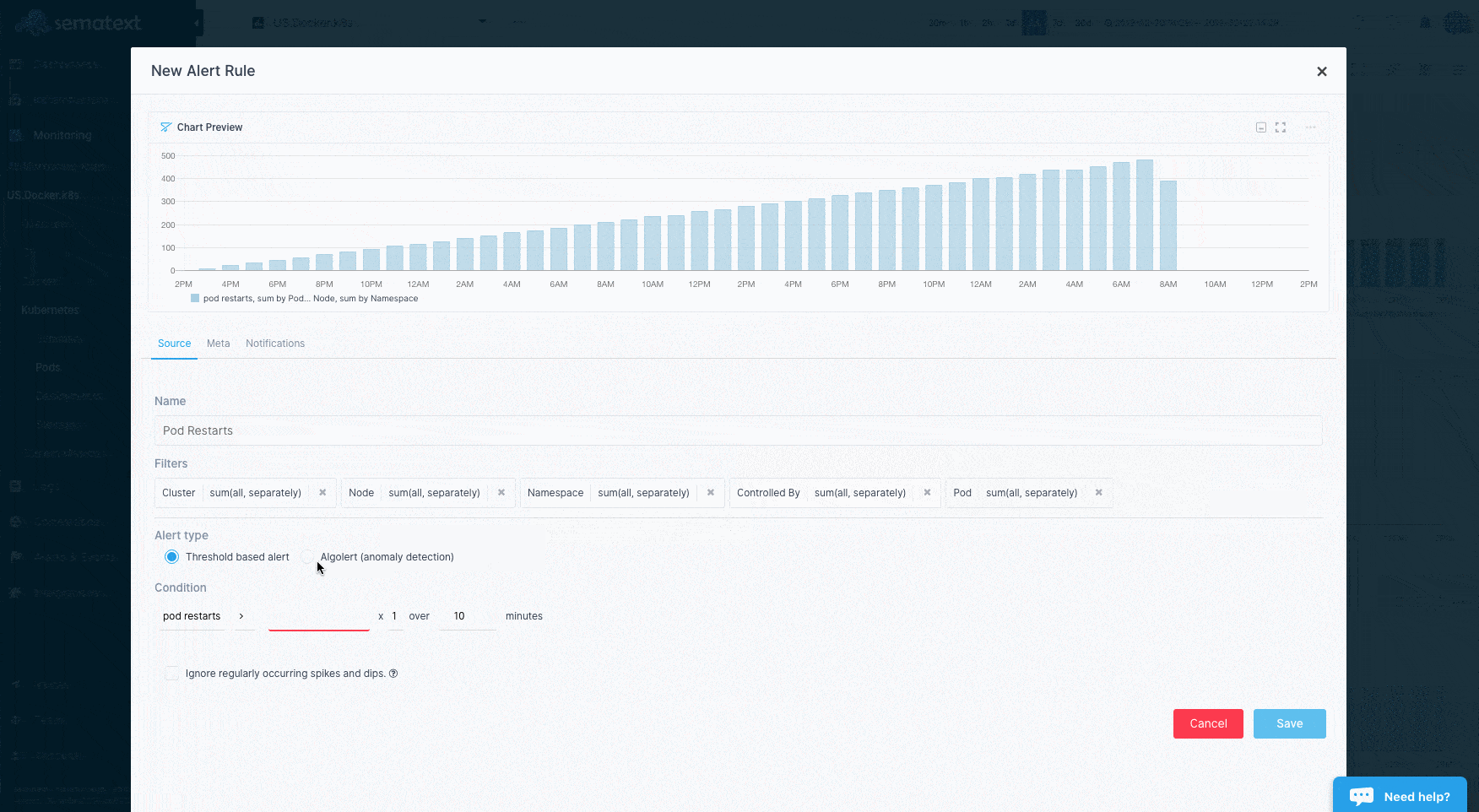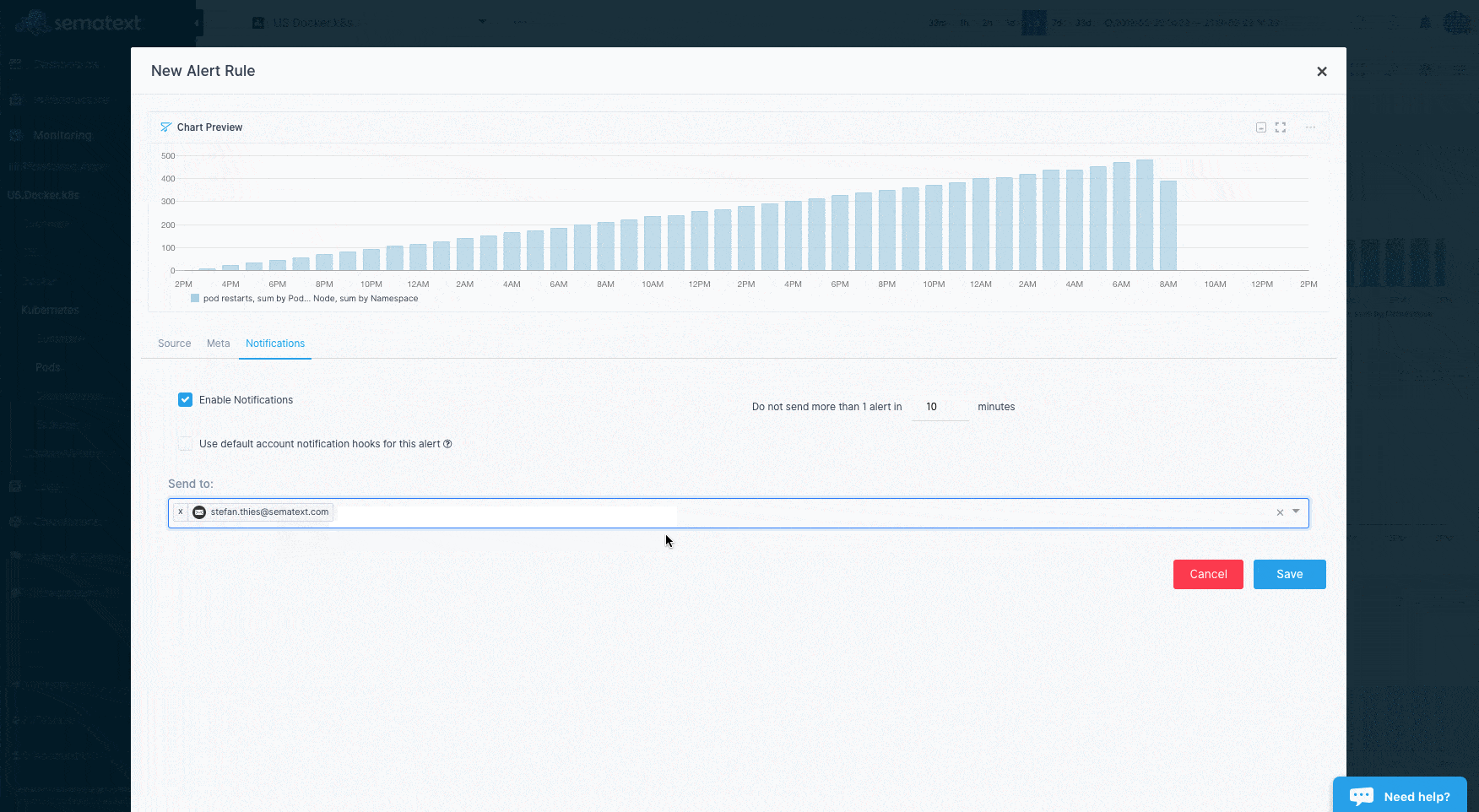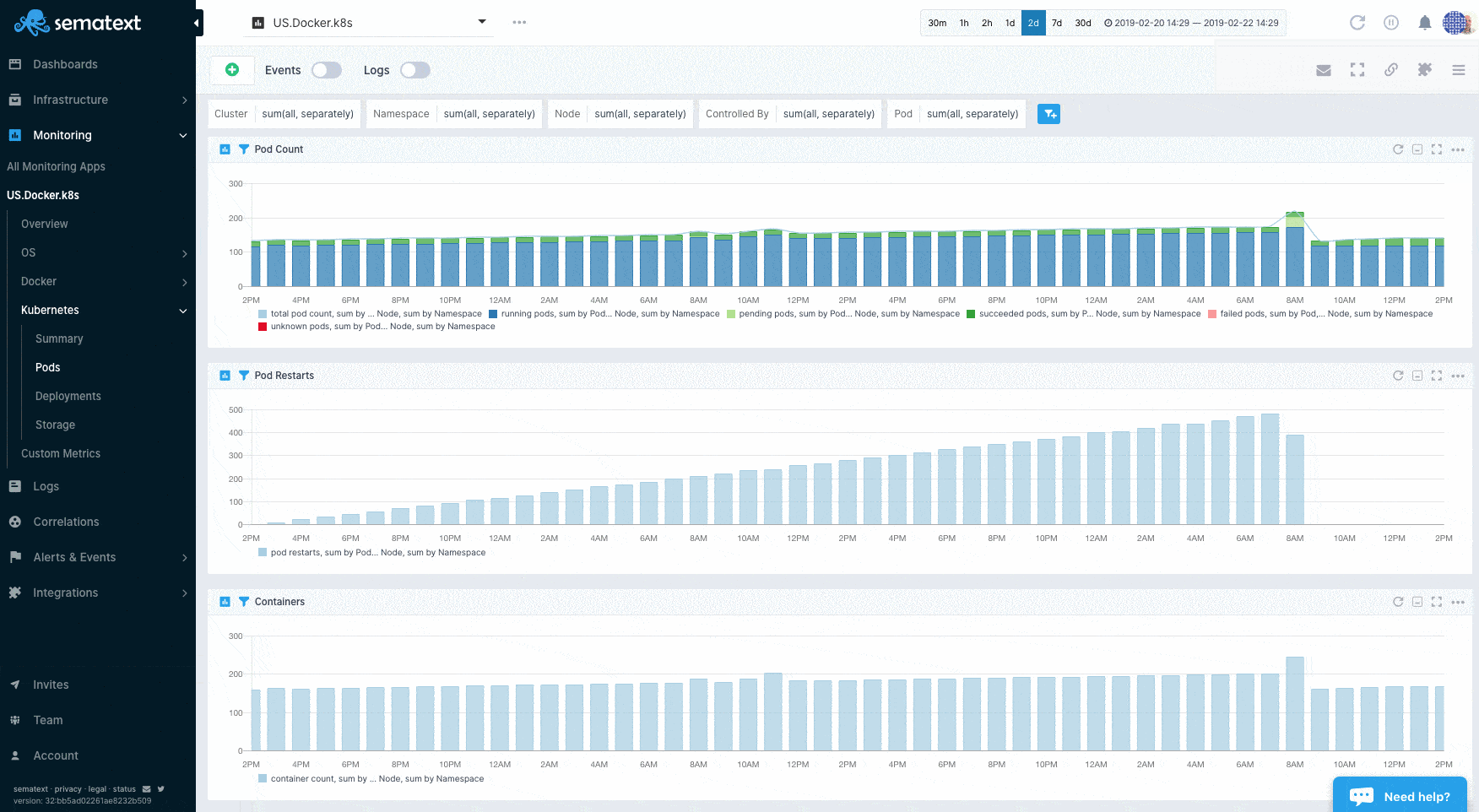
Sematext Agent collects a plethora of metrics about containers (Docker, containerd) and orchestrator platforms and ships that to Sematext Cloud.
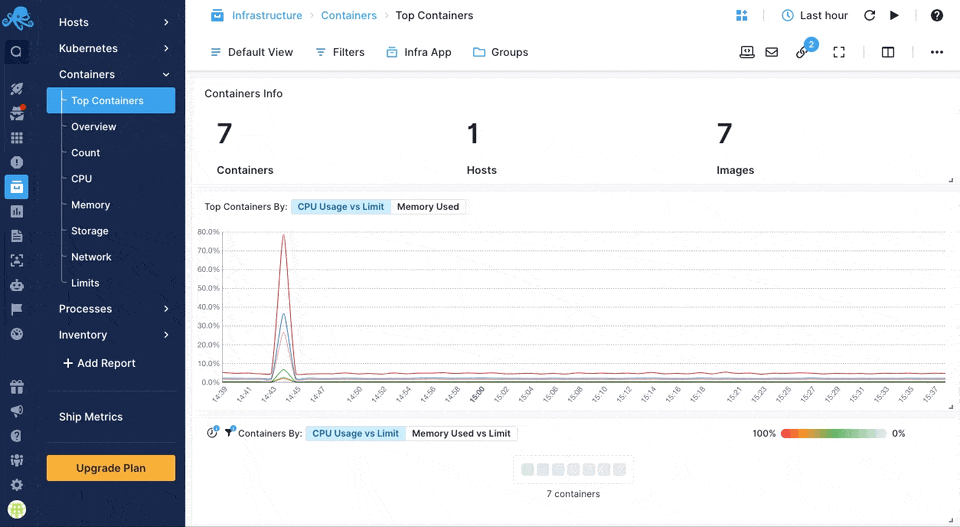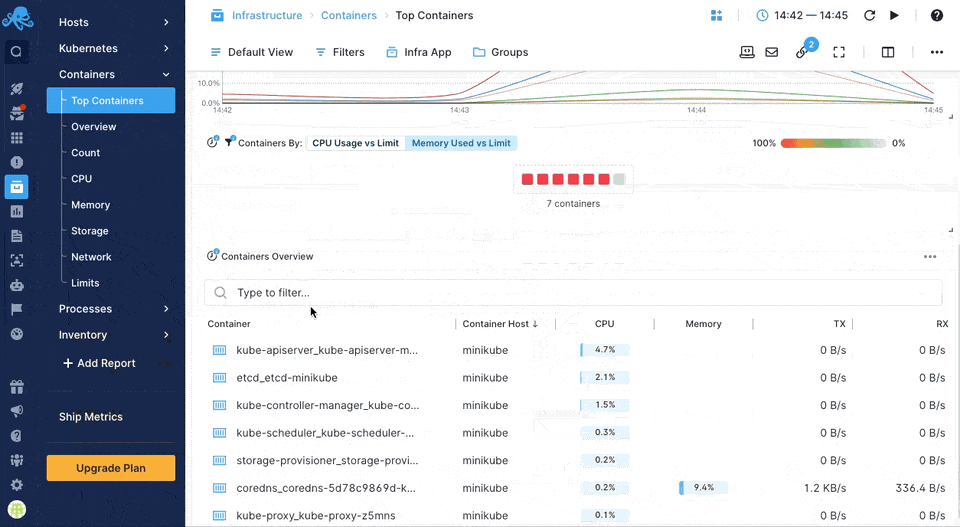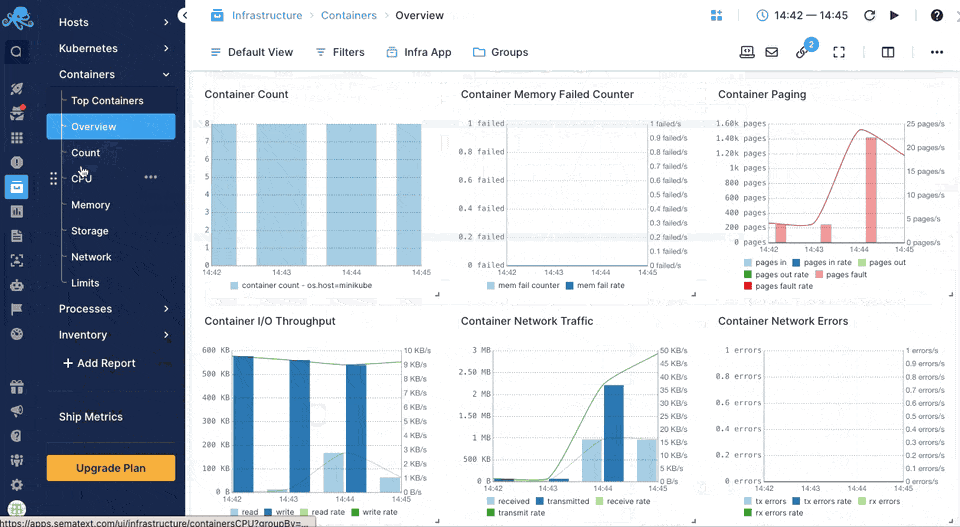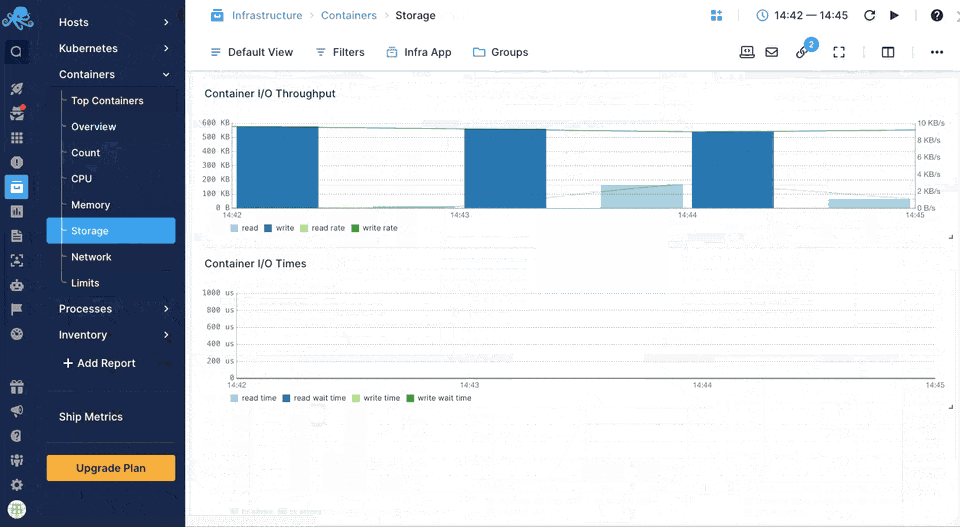
You can see host and container metrics or have a high-level overview of all your containers in Infrastructure reports.
Check out the Sematext Agent installation for containers guide for more info.
Container Alerting¶
To save you time Sematext automatically creates a set of default alert rules such as alerts for low disk space. You can create additional alerts on any metric.
There are 3 types of alerts in Sematext:
- Heartbeat alerts, which notify you when a server is down
- Threshold-based alerts that notify you when a metric value crosses a predefined threshold
- Alerts based on statistical anomaly detection that notify you when metric values suddenly change and deviate from the baseline
Container Events¶
Events reflect changes in your infrastructure, from node restarts to container deployments, or changes in running containers. Events can track every container command. Sematext Agent collects events from container runtimes and Kubernetes API. Whenever something goes wrong in your container stack, you can correlate Logs or Metrics with the time of container events.
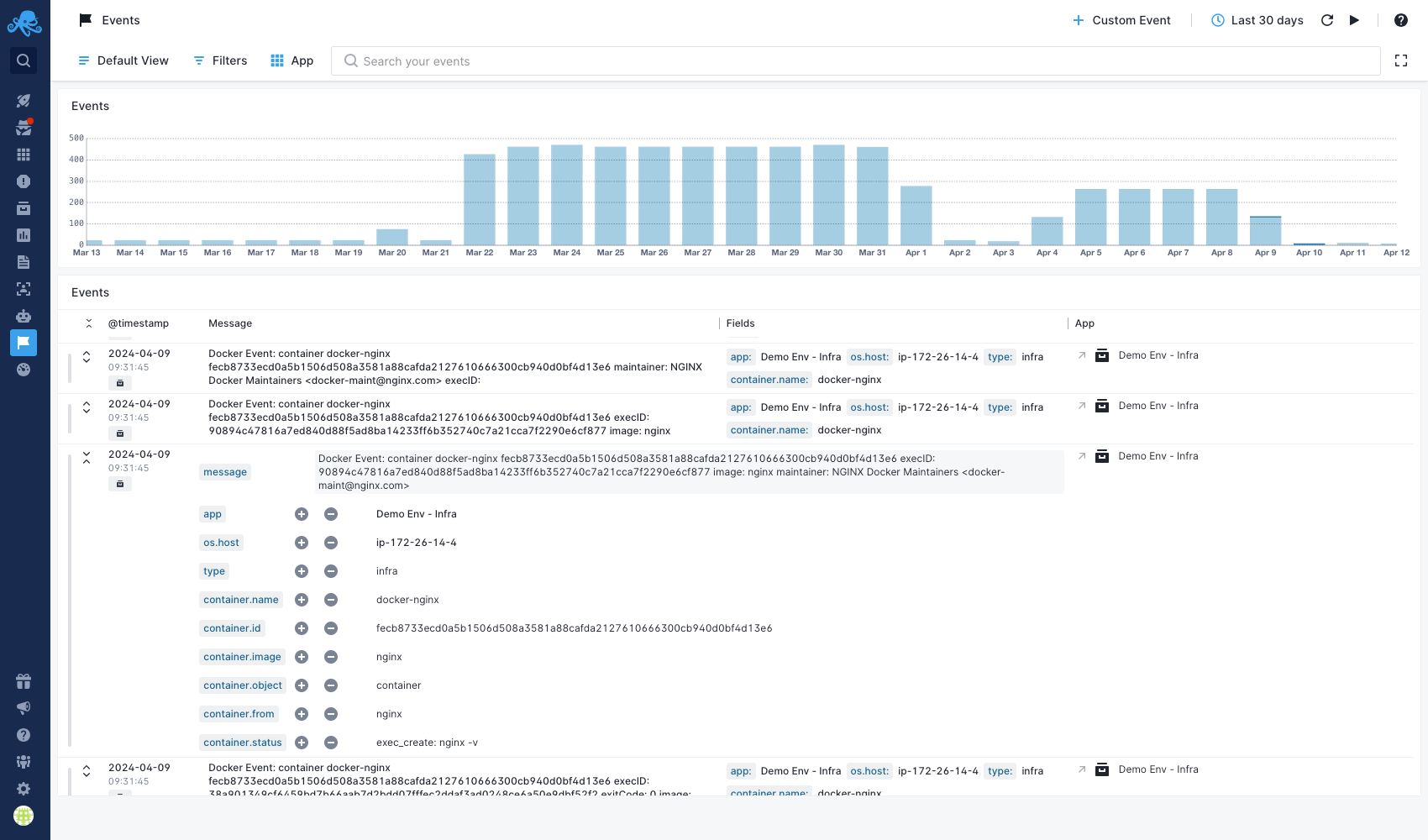
Refer to the Agent container events page for more details on all container events collected by the Sematext Agent.
Container Metrics¶
Check out the all the supported Container metrics shipped by Sematext Agent.